
基于双Booth 2编码的双有限域模乘法器设计与实现
2009-01-15
作者:徐金甫, 仲先海, 杨 洋
摘 要: 采用双Booth 2编码技术,对高基radix-16 Montgomery模乘法器进行了优化设计,减小了电路面积,提高了模乘运算速度。使用SMIC0.18μm标准单元工艺库综合后,计算256bit有限域GF(p)上的模乘只需要0.51μs。
关键词: 布斯编码; Montgomery; 有限域; 模乘法器
RSA算法、数字签名标准、椭圆曲线密码系统都要涉及到模乘或模幂运算。Montgomery模乘算法[1]把模乘运算时的除法运算转换成了简单的移位操作,大大提高了模乘运算的速度,从而得到了广泛的应用[2-4]。公钥密码体制中模乘运算的操作数位宽很大,ECC需要160~512bit,RSA等甚至达到1 024~2 048bit。直接利用原始的Montgomery模乘算法只能处理固定位宽的操作数,而且速度和面积均不理想。为此,一种基于字的Montgomery模乘算法被提了出来[2],该算法不仅大大缩短了关键路径,而且可将操作数扩展到任意位宽。目前已有多种基于这种算法的模乘法器设计方案[3-4]。本文基于双Booth 2编码提出了另一种改进方案并进行了优化设计,使得模乘运算的速度得到了进一步的提高。
1 基于字的双有限域Montgomery模乘算法
Tenca[2]提出了基于字的双有限域Montgomery模乘算法。基于这种算法设计的模乘法器采用基于字的操作数代替固定长度操作数,不但解决了大数加法进位链过长使电路关键路径延迟太大的问题,而且使得模乘法器具有了可扩展性,能支持任意位长的模乘。把素数域GF(p)与二进制域GF(2m)上的模乘统一起来则能在一个硬件上支持两种域上的运算,从而节省了成本。基于字的双有限域Montgomery模乘算法如下:
Input: A,B,p,w,k,field
Output: C∈[1,p-1]
1a: C=0
1b: spill=0
2: for i=0 to u-1
3: (spill|c0)=(aib0)φc0
4: q=f(c0,p0,field)
5a: (spill|c0)=(q·p0)φ(spill|c0)
5b: for j=0 to e-1
5c: (spill|cj)=(ai·bj)φcjφspillφ(q·pj)
6a: cj-1=(cj|cj-1)/r mod w
6b: ce-1=(spill|ce-1)/r mod w
6c: ce=0
7: if C>p, then C=C-p
算法把m bit模乘操作数扩展后看作基于字的向量,然后对操作数逐字扫描进行运算。其中,p=(0,pe-1,…,p1,p0),B=0(0,be-1,…,b1,b0),C=(0,ce-1,…,c1,c0),A=(au-1,…,a1,a0),pi、bi、ci是基为2w的字,ai是基为2k的字,u= 二进制域上多项式A(x)可以简单地看成素数域上的A,只是在部分积累加时有区别,素数域上有进位的传播,二进制域上为“异或”运算无进位,算法中统一用φ表示。函数f(c0,p0,field)只用到了c0、p0的最低k bit,有限域GF(p)上q=(c0·(2k-p0-1))mod r,有限域GF(2m)上q=(c0·p0-1)mod r。
二进制域上多项式A(x)可以简单地看成素数域上的A,只是在部分积累加时有区别,素数域上有进位的传播,二进制域上为“异或”运算无进位,算法中统一用φ表示。函数f(c0,p0,field)只用到了c0、p0的最低k bit,有限域GF(p)上q=(c0·(2k-p0-1))mod r,有限域GF(2m)上q=(c0·p0-1)mod r。
Tenca[2]把上述Montgomery模乘算法组织成了流水线结构。它包括s级处理单元(PE),每个PE运算单元做两次一个字长的加法,加法器采用带域选择信号field的进位保留加法器(CSA),运算结果经过一级流水线寄存器后传给下一级PE运算单元。PE经重定时优化后采用两级寄存器结构,第一级计算q,第二级完成第5步的累加。PE每次处理3bit的A,即对A的编码采用基为8的Booth 3编码。为面向RSA应用,Yibo Fan[3]在素数域GF(p)上对Tenca[2]提出的结构进行了优化,采用基为16的Booth 4编码,提高了近26%的性能。
2 双Booth 2双有限域模乘法器的设计
Yibo Fan[3]采用的处理单元PE采用分裂基的方法简化对ai的Booth编码,有效避免了不规则bi、pi的倍数(如出现3bi、7pi),但其需要六选一的数据选择器,而且左右两个数据选择器不一样,造成布局布线的不规则。本文经研究发现可以把基为16的ai分成两个基为4的操作数同时操作,仍然可采用类似分裂基的硬件结构,而且左右数据选择器相同,使得VLSI实现时布线更容易;对基为4的操作数采用Booth 2编码后,编码器结构也更简单,数据选择器的输入只有0、bi、-bi、2bi、-2bi,它们只需要经过简单的移位与取反操作就能够实现,从而减小了电路面积。编码电路和数据选择器电路更加简单还可以缩短关键路径的延迟,从而提高了模乘法器的速度。
2.1 总体结构设计与优化
双Booth 2双有限域模乘法器的核心仍然是基于字的Montgomery模乘算法,因此也可以组织成流水线结构,如图1所示。它由s个处理单元(PE)、一个移位寄存器、两个同步读写RAM、一个异步FIFO以及控制模块组成。移位寄存器根据算法外层循环依次移位输出ai,两个同步读写RAM则根据算法内层循环输出bi、pi。如果在模乘运算中出现流水线溢出,则把中间结果暂存到FIFO中,等待流水线空闲;如果不出现流水线溢出,则旁路掉FIFO直接使中间结果进入新的流水线。PE处理后的数据是以carry-save的冗余形式表示的,中间数据位宽增大了一倍,造成FIFO需要增大一倍。由于FIFO一路的中间结果不处在关键路径上,可以用一个并行前缀加法器PPA把carry-save冗余形式转化为整数形式,这样可以节省一半的FIFO。Tenca[2]实现的模乘法器中使用循环寄存器存储bi、pi需要占用大量的面积,而本文使用RAM代替可以充分利用标准单元库的资源,减小了电路面积。
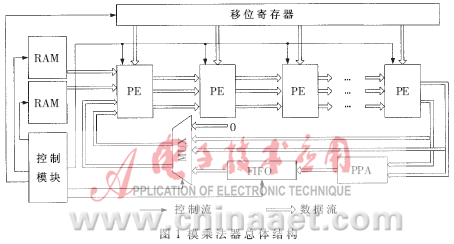
2.2 模乘处理单元结构
模乘处理单元PE是模乘法器的核心部件,若干级PE通过流水线寄存器串联起来执行大数模乘运算,其电路结构如图2所示。它包含4个五选一的数据选择器、2个双有限域进位加法器CSA、1个4位超前进位加法器CLA、2个Booth 2编码器、2个修改的Booth 2编码器及若干寄存器。为了提高电路工作频率,用寄存器把PE电路分成两个部分,使其用两个时钟完成部分积的累加。为平衡路径延迟,把两个CSA放在寄存器的两边。由于第二个时钟周期内的编码电路比第一个时钟周期内的编码电路要复杂,延时更大,如果把4位CLA放在第一个时钟内计算则刚好能达到大致平衡。
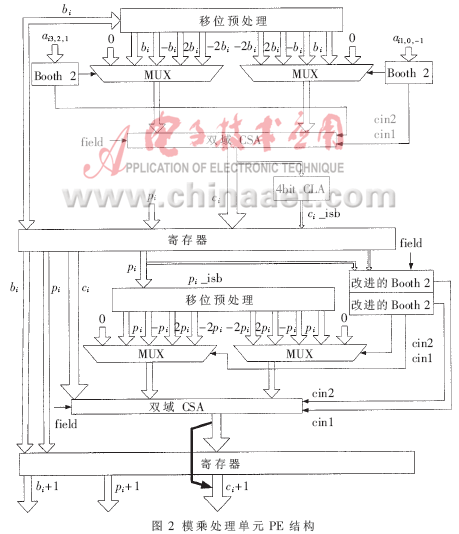
乘数A每次扫描4位,分成两组,每组2位,经Booth 2编码后得到3位的输入数据控制数据选择器的输出。函数f通过编码器实现,有限域GF(p)与GF(2m)上的q值计算不一样,因此需要同时编码并通过域选择信号field选择输出。编码输出的四位q值再次经过双Booth 2编码控制数据选择器的输出。上述分两步的编码方式其中间值q是可以省略的,直接修改Booth 2编码的输入信号,一次编码完成,部分编码如表1所示。

3 实现结果
基于双Booth 2编码的双有限域模乘法器作为核心部件应用在双有限域ECC协处理器中,根据协处理器的实际需要,处理的最长操作数为384位,因此模乘法器采用4级流水;bi、pi的字宽为32位,便于与常用总线连接。这种设计既考虑了处理速度,又兼顾了电路占用的面积。模乘法器用Verilog语言描述,采用Synopsys公司的Design Complier 在SIMC 0.18μm-typcal工艺库下综合,等效“与非门”为4.5万门,最高工作频率可达280MHz,完成一次GF(p)上的256bit模乘运算只需要0.51μs。表2是本文设计的模乘法器与已发表文献中同类设计的比较结果。表中结果显示,本文设计的速度比最好的已发表的设计[3]提高了16%。

双有限域模乘法器使用同一套硬件电路实现有限域GP(p)与GF(2m)上的ECC模乘运算,节约了硬件成本,扩展了运用空间。本文基于双Booth 2编码对基为16的Booth 4编码的模乘法器进行了优化,使得电路更加规范、简单。从实现结果可以看出,本文的设计有效地减小了关键路径延迟,提高了模乘法器的运算速度。
参考文献
[1] MONTGOMERY P L. Mondular multiplication without trial division. Mathematics of Computation, 1985,44(7):519-521.
[2] TENCA A F, SAVAS E, KOC C K. A design framework for scalable and unified multipliers in GF(p) and GF(2m). International Journal of Computer Research, 2004,13(1):68-83.
[3] FAN Yi Bo, ZENG Xiao Yang, GANG Yi Yu,et al. A modified high-radix scalable montgomery multiplier. IEEE International Symposium on Circuit and System(ISCAS), Island of Kos, Greece, May. 2006.
[4] 史焱,吴行军.高速双有限域加密协处理器设计.微电子学与计算机,2005,22(5):8-12.