
0 引言
随着科技的发展,智能设备大量涌现,其中智能汽车作为典型代表之一,对其进行研究开发也相当普遍,当然人与这些智能化设备之间快捷可靠的交互方式很多,其中语音辨识技术以其独特的趣味性成为了人与智能系统交互方式中的热点。本文所设计的智能小车利用语音辨识技术,实现自动前进、后退、左拐、右拐和停车。
1 智能车语音辨识系统的开发平台SPCE061A
采用语音辨识技术构建的智能小车的语音辨识系统实现了小车的自动行驶,而SPCE061A控制器是构建语音辨识系统的开发平台。
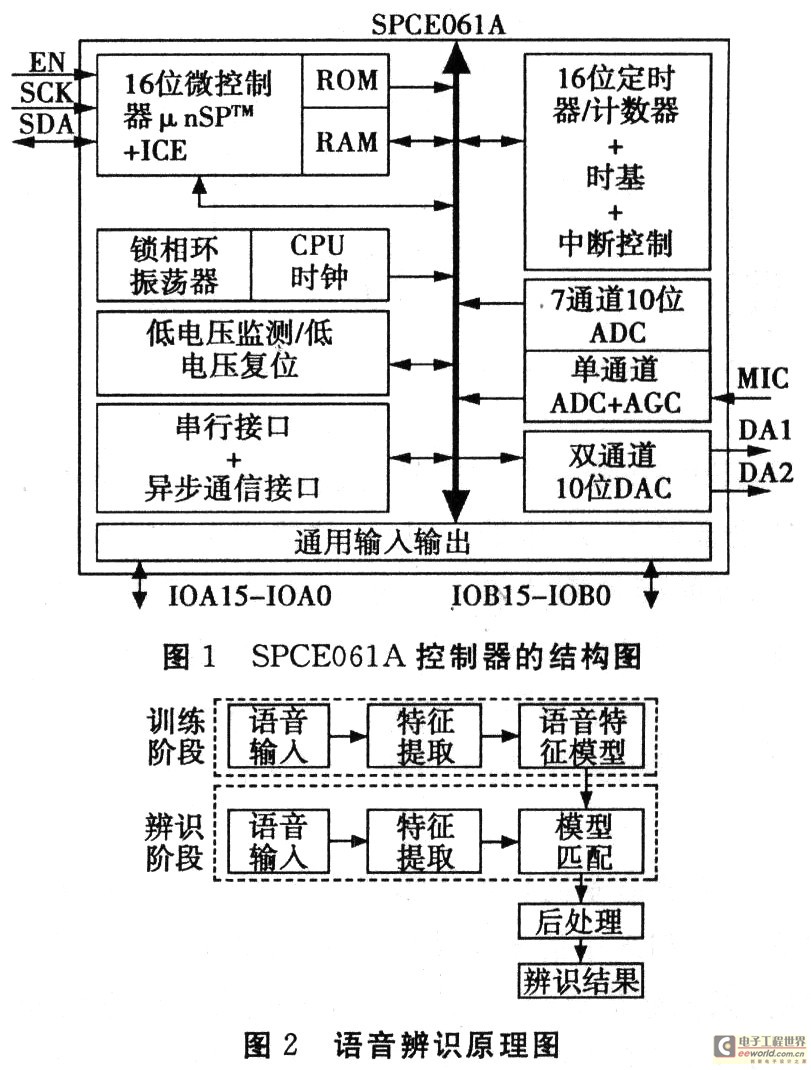
SPCE061A是一款16位独具语音特色的控制器,片内采用的μ‘nSPTM(microcontroller and signal processor)核心处理器,具有较高的处理速度,能够完成16位算术逻辑运算、16×16位硬件乘法运算和DSP内积滤波运算、能够快速处理复杂的数字信号,不需要额外的专用语音控制芯片,就能实现语音的编解码等,既节省了设计成本,又能满足一定的控制要求。控制器采用模块化架构,集成了ICE(在线仿真)、锁相环振荡器、时基控制器、7通道10位AD转换器、单通道AD+AGC(自动增益)转换器、双通道10位DA转换器、通用异步通信接口、串行输入输出接口、电压监控等模块,其结构如图1所示。
2 语音辨识的基本原理
语音辨识是建立在对人的语音交互过程的基础上,它是一种多维模式辨识过程,分为训练和辨识两个阶段,其基本原理图如图2所示。辨识过程主要包括语音信号的预处理、特征提取、语音模型库、模式匹配、后处理等几个环节。预处理包括滤波、采样和量化、加窗、端点检测、预加重等过程,然后对预处理后的语音信号样本进行分析处理,从中提取出语音特征信息,建立特征模型;之后开始模式匹配,将输入语音信号的特征与已有的特征模型进行对比,如果两者达到一定的匹配度,则输入的语音被辨识。机器语音辨识处理的过程与人对语音辨识处理的过程基本上是一致的,目前主流的语音辨识技术是基于统计模式辨识的基本理论。
3 基于SPCE061A的语音辨识系统在智能小车上的实现
智能小车的语音控制系统以SPCE061A控制器和语音输入电路、语音输出电路为硬件基础,语音输入电路如图3所示,其中VMIC提供传声器的电源,VSS是系统的模拟地,VCM为参考电压,1脚和2脚分别是传声器X1的正极、负极的输入引脚,连接SPCE061A的MICP、NICN管脚上。当对着传声器讲话时,1脚和2脚将随着传声器输入的声音产生变化的波形,并在SPCE061A的两个端口处形成两路反相的波形,送到SPCE061A控制器内部的运算放大器进行音频放大,经过放大的音频信号,通过 ADC转化器转化为数字量,保存到相应的寄存器中。语音输出电路如图4所示,其中VDDH为参考电压,VSS是系统的模拟地。音频信号由SPCE061A 的DAC引脚输出送到电路的9端,通过音量电位器R9的调节端送到集成音频功率放大器SPY0030,经音频放大后,音频信号从SPY0030输出经J2 端口外接扬声器播放声音。

SPCE061A配有专用的麦克接口用于语音训练和辨识阶段的语音输入,16位的定时/计数器用于语音信号的控制采样,内置的硬件乘法器和内积运算保证了辨识算法的运行。在软件方面,凌阳科技提供一个语音辨识函数库bsrv222SDL.lib,它能够完成特定人语音的连续辨识,包括训练函数和辨识函数,还可以将训练好的特征模型导入和导出等。
由于语音命令的特征模型要保存到RAM中,所以首先擦除SPCE061A中的RAM,与语音训练做准备。训练模式启动后,系统播放语音提示,提示用户语音训练已启动,接下来用户可按照系统提示依次对各条命令进行训练,在训练过程中,如训练成功则由语音提示进行下一条命令进行训练,若失败,也会提示用户继续训练此条语音,全部命令训练完毕后系统将准备进行语音辨识;当向控制器发出语音命令时,声波通过麦克端口输入,将相应的信号传递到SP-CEO61A处理芯片,经编解码电路和数字信号处理后,在芯片中通过相关程序与预先植入的语音库中的命令进行比较辨识,根据辨识的结果进行判断,转换为能被系统辨识的信号,从而对被监控系统进行控制。语音辨识的过程如图5所示。

智能小车的语音辨识系统在SPCE061A上的实现过程可分为以下五个阶段,如图6所示。
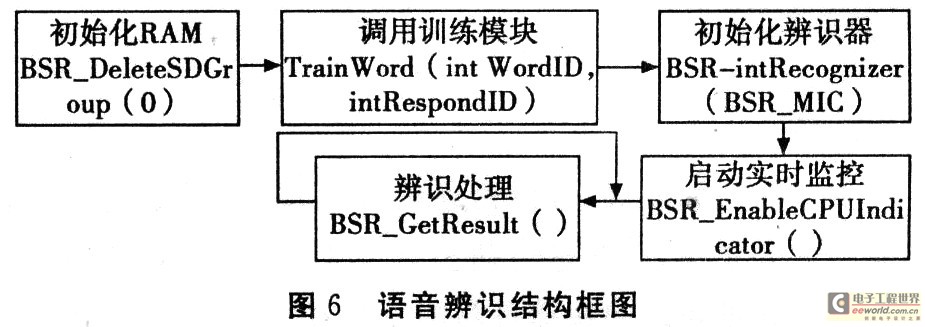
(1)初始化RAM
语音命令的特征模型被保存在SPCE061A的内部
RAM中,如果所需的RAM空间被旧的特征模型数据占满,新特征模型则无法保存到RAM中,利用BSR_DeleteS-DGroup(0)函数可以把 RAM空间中所有的特征模型删除,释放出所需的空间。当RAM擦除成功BSR_DeleteS-DGroup(0)函数返回0,否则返回-1。
(2)调用训练模块
语音训练过程通过调用函数im BSR_Train(int Corn-mandID,int TraindMode)来完成,CommandID为命令序号,范围从0x100到0x105,并且对于每组训练语句都是唯一的。TraindMode为训练次数,为1表示使用者训练一次,为2表示训练者训练两次。为了增强可靠性,最好训练两次,否则辨识的命令就会倾向于噪音,训练次数是2时,两次一定会有一些差异,所以一定要保证两次训练结果尽量接近。当int BSR_Train返回0时表明语音训练成功。
(3)初始化辨识器
用来定义语音输入来源,可以通过调用函数void BSR_InitRecognizer(int AudioSource)完成,其中参数Audio-Source为0时表示MIC语音输入,为1时表示LINE_IN模拟电压输入。当主程序调用该函数时,语音辨识器便打开8kHz采用频率的FIQ_TMA中断,并将采样得到的语音数据填入语音辨识器的数据队列中。
(4)启动实时监控
实时监控是用来观察语音辨识是否正常工作,如果辨识正常则会产生脉宽为16ms连续稳定方波,否则会产生不稳定的波形,此时需要删除命令或优化程序,否则将会丢失语音数据,产生辨识出错信息。完成此功能可以通过调用BSR_EnableCPUIndicator()函数来完成。
(5)辨识处理
由函数int BSR_GetResult()完成语音辨识处理,当无命令辨识出来时,函数返回0;辨识器停止未初始化或辨识未激活返回-1;当辨识不合格时返回-2;当辨识出来时返回命令的序号。
4 实验与结论
实验中智能小车的正确辨识率在90%以上,实验过程中发现影响小车正常辨识的因素主要包括周围环境的噪音、人与小车的距离等,这些需要在今后的工作改正。需要说明的是在训练过程中中,每条语音命令的长度不要超过13 s,训练后得到的语音模型保存在RAM中,每条命令占用96Word。由于RAM空间有限,同时可辨识的语音命令为5条,为了运行复杂的辨识程序,必须通过扩展必要的存储芯片完成系统的功能。
这种语音控制的智能小车机器人不仅可以将来为人服务,稍加扩展,就可以在多种不适合人作业的场合替代人执行任务,因此这种语音控制小车机器人具有重要的学术研究价值。