
一种基于属性加权的代价敏感支持向量机算法
2009-07-29
作者:戴元红, 陈鸿昶, 胡海龙
摘 要: 针对实际中存在的各类别样本错分造成不同危害程度的分类问题,提出了一种基于属性加权的代价敏感支持向量机分类算法,即在计算各个样本特征属性对分类的重要度之后,对相应的属性进行重要度加权,所得的数据用于训练和测试代价敏感支持向量机。数值实验的结果表明,该方法提高了误分代价高的类别的分类精度,同时属性重要度的引入提高了分类器的整体分类性能。该方法对错分代价不对称的数据分类问题具有重要的现实意义。
关键词: 属性加权; 支持向量机; 代价敏感支持向量机
SVM算法是一种专门研究小样本情况下机器学习规律的理论,它能够解决渐进理论所难于解决的过拟合、局部极小和泛化能力差等问题。这一新的机器学习方法表现出很多优于已有方法的性能,迅速引起各领域的关注和研究,并成功地引入到很多领域的应用中,取得了大量的应用研究成果。
在SVM算法的研究中,提高它的分类能力是所有研究的宗旨和目的,很多学者提出了改进的支持向量机方法:给每一类样本赋以不同权值的加权支持向量机算法WSVM(Weighted SVM)[1-2],对类别差异造成的影响进行相应的补偿,提高了小类别样本的分类精度,但影响了整体的分类性能;将模糊学引入了支持向量机,提出了模糊支持向量机算法FSVM(Fuzzy SVM)[3-4],减少野值和噪声的影响;利用样本的属性重要度的支持向量机方法[5],给各个属性设定相应的权值,提高了分类的精度。
针对实际应用中各类别样本错分所造成的不同程度危害,提出了代价敏感支持向量机算法[6],该方法对支持向量机算法进行改进,将分类代价考虑进去,使得分类结果的代价最小,该方法对错分代价不对称的数据分类问题具有重要的现实意义,如网络故障、网络安全等。
1 支持向量机
支持向量机的基本思想是对于给定的样本集(xi,yi),xi∈Rn,yi∈{+1,-1},i=1,…,l,其中xi是n维空间中的向量,yi是xi所属类的类别标识,寻找将两类数据正确分开并使分类间隔最大的超平面,该超平面称为最优超平面,分类情况如图1所示。

为了寻找最优超平面,需要求解下面的二次规划问题:

其中,
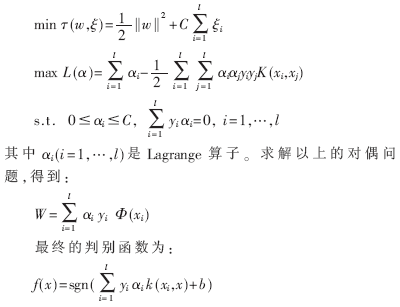
这是由Vapnik提出的第一种支持向量机,也被称为C-SVM或标准支持向量机。
2 代价敏感支持向量机
考虑两类的分类问题,类别分别为C+和C-,假定C+的错分代价大于C-的错分代价。为了解决分类中的代价不对称问题,将分类算法SVM进行改造,基本思想就是对C+错分、C-错分两种错误分别引入不同的代价函数。这种方法等价于对误分代价高的类使用更大的拉格朗日算子αi,从而使分类平面远离C+,而靠近C-,使得未知数据被划分为C+的概率更大,从而减小了分类中因错分引起的损失。
在支持向量机(SVM)中,原始问题为:
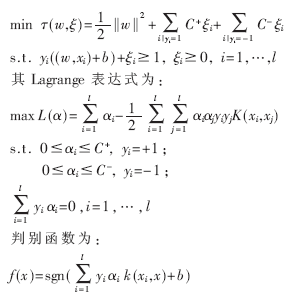
在训练过程中使用C+>C-,得到的分类器的决策平面靠近类别C-,使测试样本更多地落在C+的区域中,从而减小C+类的样本错分的可能性,但也加大了C-类样本被错分的可能性。因此需寻找合适的参数,使得两类样本的分类结果都尽可能地达到最优。设两类样本的约束值的比值为:
s=C+/C-
s值通常使用穷举的方法来确定,先固定C-的值为C,搜索最佳参数C+的值,使得分类的错误代价最小。
代价敏感支持向量机的主要思想就是通过改变两类的惩罚因子C+和C-的比值,使得分类面向远离错分代价高的一类的方向移动,从而使得样本更大可能地被分为这一类,降低分类错误代价,但提高某一类样本的分类正确率总是以牺牲另一类的分类正确率为代价的。
3 属性的权值
样本属性重要性的度量是属性相关分析的主要内容,在模糊集和粗糙集理论方面有许多的研究。这里介绍常用的基于信息熵的属性权值的计算方法[6]。
设有数据样本集合S,该样本集有m个不同的属性值和n个不同的类别,分别定义为Ai(i=1,…,m)和Cj(j=1,…,n),si为Ci中的样本数。根据概率分布和联合概率分布以及信息论中熵和条件熵的定义,对于一个给定的样本分类问题所需的期望信息由下式给出:

式中 pi是样本属于Cj的概率,其中 pi=si/s。
设属性A有v个不同值{a1,a2,…,av},属性A可将样本集S划分为v个子集{s1,s2,…,sv},其中Sj为在属性A上具有值ai,设sij为子集Sj中类Ci的样本数。根据A的这种划分的期望信息为:

式中pij=sij/|sj|,|sj|是sj中样本属于类Ci的概率。
在属性A上该划分获得的信息增益为:
δ=H(C)-E(A)
根据上面的计算得到每个属性的权重系数为:
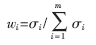
从分析中知道,该权重系数反应了样本中各个属性的重要程度,权重系数值越大则该属性越重要,对分类的贡献越大。
在确定了样本属性重要度后,就可以构造基于样本属性重要度的代价敏感支持向量机。
4 实验结果
本文利用MATLAB软件进行模拟实验,对+1类和-1类的分类性能进行比较,在三维空间中引入两类不同的样本:正类和负类,并引入了一定数量的噪声和野值数据。为了验证所提算法的有效性,利用所提算法进行了一系列比较实验。在实验中,模拟用的训练样本和测试样本均随机产生,样本数据情况如表1所示。
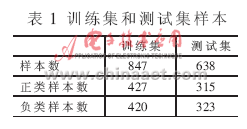
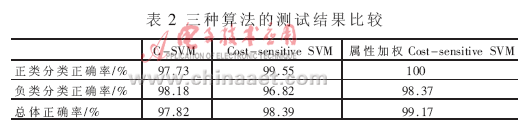
在实验中考虑正类的错分代价大于负类的错分代价,分别用C-SVM、Cost-sensitive SVM和属性加权的Cost-sensitive SVM进行性能测试,表2所示为分类准确率的比较。由表2可见代价敏感支持向量机分类算法提高了错分代价高的类别的分类精度,在进行属性加权后,总体的分类精度也得到了提高。
本文在对支持向量机分析的基础上,提出了对样本属性加权型的代价敏感加权支持向量机。数值实验的结果表明,该方法能够提高错分代价敏感的类别的分类精度,同时整体的分类性能也得到了提高。但是如何确定代价系数仍然是一个需要解决的问题,也是笔者下一步要研究的方向。
参考文献
[1] 范昕炜,杜树新,吴铁军.可补偿类别差异的加权支持向量机算法[J].中国图像图形学报,2003,8(7):1037-1042.
[2] 贾银山,贾传荧. 一种加权支持向量机分类算法[J].计算机工程,2005,10(5):35-39.
[3] LIN C F, WANG S D. Fuzzy support vector machine [J]. IEEE Trans. On Neural Networks, 2002, 13(2):464-471.
[4] 陈小娟, 刘三阳. 一种新的模糊支持向量机算法[J].西安文理学院学报:自然科学版,2008,11(1):1-4.
[5] 汪延华,田盛丰. 样本属性重要度的支持向量机方法[J]. 北京交通大学学报,2007,10(5):43-46.
[6] 赵靖.基于SVM算法的垃圾邮件过滤研究与实现[D].北京:北京交通大学,2005.