
优化的RBF网络在特征选择中的应用研究
2009-08-31
作者:朱颢东1,2,钟 勇1,2
摘 要: 提出了一个自适应量子粒子群优化算法,用于训练RBF网络的基函数中心和宽度,并结合最小二乘法计算网络权值,对RBF网络的泛化能力进行改进并用于特征选择。实验结果表明,采用自适应量子粒子群优化算法获得的RBF网络模型不但具有很强的泛化能力,而且具有良好的稳定性,能够选择出较优秀的特征子集。
关键词: 特征选择;文本分类;RBF神经网络;量子粒子群优化;最小二乘法
在文本分类中,文本通常是以向量形式来表示的,其特点是高维性和稀疏性[1]。而在中文文本分类中,通常采用词条作为最小的独立语义载体,原始的特征空间可能由出现在文章中的全部词条构成。由于中文的词条总数有20多万条,这使得其高维性和稀疏性更加明显,这样就大大限制了分类算法的选择空间,降低了分类算法的效率和精度。为此,寻找一种高效的特征选择方法,以降低特征空间维数、避免维数灾难,提高文本分类的效率和精度,成为文本自动分类中亟待解决的重要问题[2-4]。
本文首先提出了一个自适应量子粒子群优化算法,用于训练RBF网络的基函数中心和宽度,并结合最小二乘法计算网络权值,对RBF网络的泛化能力进行改进。然后把该RBF神经网络用于特征选择。实验结果表明,采用自适应量子粒子群优化算法获得的RBF网络模型不但具有很强的泛化能力,而且具有良好的稳定性,能够选择出较优秀的特征子集。
1 RBF神经网络简介
RBF网络是一种3层前馈神经网络[5-7]。由输入层、隐层和输出层组成。网络输出层的输出计算公式为:
这里 是输入矢量;φk(·)是从正实数集合到实数集合的函数,此函数的给出形式较多,这里采用高斯函数:
是输入矢量;φk(·)是从正实数集合到实数集合的函数,此函数的给出形式较多,这里采用高斯函数:

 表示欧几里德范式;wik是输出层的权值;N表示隐含层神经元的个数;ck∈Rn×l表示输入向量空间的RBF网络的中心(简称中心)。对于隐含层的每一个神经元,要计算与其关联的中心和网络输入间的欧几里德距离。隐含层神经元的输出是该距离的非线性函数。隐含层输出的加权和是RBF网络的输出[5-7]。
表示欧几里德范式;wik是输出层的权值;N表示隐含层神经元的个数;ck∈Rn×l表示输入向量空间的RBF网络的中心(简称中心)。对于隐含层的每一个神经元,要计算与其关联的中心和网络输入间的欧几里德距离。隐含层神经元的输出是该距离的非线性函数。隐含层输出的加权和是RBF网络的输出[5-7]。
由公式(1)和(2)可见,如果知道了RBF网络的隐层节点数N、中心ck和δ宽度,RBF网络从输入到输出就成了一个线性方程组,此时连接权值的学习可采用最小二乘法求解。因此,只要确定了N、ck和δ,RBF网络模型也建立好了。而对RBF网络的隐层节点个数,本文采用了SOM(Self Organization Mapping)网络的聚类算法来确定。对中心ck和宽度?滓则由本文提出的自适应量子粒子群优化算法来确定。
2 优化的粒子群算法
2.1 量子粒子群优化算法(QPSO)
粒子群优化(PSO)算法是一种基于群体智能的随机搜索算法,其粒子在经典力学空间中飞行,由于飞行轨迹确定,因此搜索空间有限,易陷入局部极值[8]。为了避免这个缺陷参考文献[9]从量子力学的角度出发提出具有量子行为的粒子群优化算法(QPSO)。由于在量子空间中的粒子移动时没有确定的轨迹,使粒子可以在整个可能解空间中随机搜索全局最优解,因此QPSO算法的全局搜索能力远远优于PSO算法[9]。
由于在量子空间中,粒子的位置和速度不能同时确定,因此可以通过波函数(波函数的平方是粒子在空间中某一点出现的概率密度)来描述粒子的状态,并通过求解薛定谔方程得到粒子在空间某一点出现的概率密度函数,随后通过蒙特卡罗随机模拟的方式得到量子空间中粒子的位置方程,如下式所示[10]:
其中p为pb与gb之间的随机位置;mb是所有粒子个体最佳位置pb的平均值;N为粒子个数;b为收缩扩张系数,在QPSO算法收敛的过程中线性减小;it为当前迭代次数;it max为设定的最大迭代次数;ppos是粒子的当前位置;a和u都是0~1之间的随机数,当u>=0.5时,公式(5)取“—”号,当0
在QPSO算法中,当pb和gb很接近时意味着粒子的参数P很小,于是粒子的搜索范围也变得很小。这样,粒子群的进化就会停滞;如果这个时候粒子群的当前最佳位置处于一个局部最优解,那么整个粒子群就会趋于早熟收敛[10]。
在QPSO算法中,只有一个收缩扩张系数b,对这个参数的选择和控制是非常重要的,它关系到整个算法的收敛性能[10]。在参考文献[10]中已经证明,当b<1.7时,粒子收敛,靠近粒子群的当前最佳位置;当b>1.8时,粒子发散,远离粒子群的当前最佳位置。从公式(5)可以看出收缩扩张系数b在粒子进化过程随着进化代数的增加而线性减小,这种固定的变化并不能自适应避免早熟趋势。对此,本文做出如下改进:
其中fbfit2为上一代群体获得最佳位置gb的适应度;ffitness(i)为第i个粒子的当前适应度。h为两者的比值,h越小,说明粒子越远离粒子群的当前最佳位置;h越大,说明粒子越靠近粒子群的当前最佳位置。本文以h的值是否小于0.5为分界,如果h<0.5,说明粒子远离群体最佳位置gb,收缩扩张系数b应该小于1.7,使它收敛。因此将b值设为2×h,使它不超过1;h≥0.5,说明粒子靠近群体的当前最佳位置gb,因此将b值设为1+h,增加其大于1.8的概率,使它尽量发散,扩大搜索范围。
3 AQPSO算法对RBF网络的优化
用AQPSO算法训练RBF神经网络时,首先要用向量形式表示RBF网络的学习过程中需要调整的2个训练参数:(1)径向基函数的数据中心c。(2)径向基函数的扩展常数,即宽度?滓。假设采用SOM聚类算法得到RBF网络有个隐层节点,粒子群的规模,即粒子的个数为N,则对粒子参数编码格式如表1所示,粒子群编码格式如表2所示。粒子参数维数D=2m,每个粒子用1个2m维的向量来表示对应的m个径向基函数的数据中心和宽度,则粒子在N×D维的解空间POP中搜索群体的最佳位置,粒子群体的最佳位置对应RBF网络中的最优的数据中心值和宽度。

计算粒子群体的最佳位置需要比较粒子的适应度,本文以每个粒子对应的网络参数在训练集上产生的均方差EMS作为粒子的适应度的目标函数,则适应度越小,EMS就越小,网络对数据的拟合程度就越高。粒子的适应度ffitness可用下面的公式计算:

其中yi为第i个粒子的实际输出值;ti为第i个粒子的期望输出值。一旦粒子搜索完成,找到的粒子群中适应度最小者,即拥有最佳位置gb,则对应的隐层节点的最优的数据中心和宽度也就确定了。对于RBF网络隐层到输出层网络连接权值向量则可以使用最小二乘法(LMS)直接计算得到。
具体的优化RBF网络模型实现如下:
(1)初始化粒子群体POP、每个粒子的最佳位置pb(0)=Φ、粒子群最佳位置gb=Φ、粒子的适应度ffitness(0)=0、当前粒子群的最佳适应度fbfit1=0、上一代粒子群的最佳适应度fbfit2=0和预设精度ε=0.09、最大迭代次数it max=200,i=1。
(2)根据当前粒子i的位置(得到网络的中心和宽度),结合最小二乘法(得到网络的连接权值)计算出粒子i对所有训练样本的适应度;并比较粒子i的适应ffitness(i)和整个粒子群体的适应度fbfit1,如果ffitness(i)
(3)判断所有粒子是否完成搜索,是则转(4),否则返回(2)。
(4)比较当前群体的最佳适应度fbfit1和上一代群体的最佳适应度fbfit2,若fbfit1
(5)判断粒子群中最佳的适应度即最小EMS,是否小于预设精度ε,是则转(8),否则转(6)。
(6)i=i+1,如果i≥it max,则转(8),否则返回(7)。
(7)根据公式(8)至(9)更新每个粒子的位置,生成新的粒子群,返回(2)。
(8)RBF网络训练完成,输出粒子群最佳位置gb。其中,gb(1:m)对应RBF网络最优的m个数据中心,gb(m+1:2×m)对应RBF网络最优的m个宽度。用LMS计算出网络连接权值,建立基于AQPSO算法的RBF网络预测模型。
4 本文特征选择方法
本文特征选择方法使用了本文提出的基于AQPSO算法优化的RBF神经网络。简单过程如下:
训练样本首先经过分词、特征提取得到原始特征集;然后利用参考文献[2]提出的优化的文档频方法先过滤掉一些词条(最小词频数阈值n=2,最小文档数阈值m=5, 这时的特征集为初选特征集),来降低特征空间维数,从而降低RBF网络的输入层的单元数,以减少该网络的训练耗时。最后用本文所给的优化的RBF网络进行特征优选,从而选择出较优的特征子集。
使用优化的RBF网络进行特征优选的方法如下:把每个训练样本表示成向量的形式,每个初选特征(经过优化的文档频方法筛选的特征)在这个向量中对应一个权值。本文取该特征在这个文本中出现的次数和这个文本所属类的总训练文本中包含该特征的文本数的乘积为权值。将所有文本向量(相当于初始粒子群)作为训练样本,RBF网络的输入层神经元个数等于初选特征数;输出层神经元个数等于训练文本的类别个数;隐含层神经元个数相对固定(以网络的泛化性和训练效率确定)。经过训练后,存在一些较大权值对应的隐含层神经元,与其相连接的输入层神经元所代表的特征即为特征,它们的并集就是优选的特征子集。
5 实验例证
5.1 实验语料库
在中文文本分类方面,经过分析和比较,本文选用的分类语料库是复旦大学中文文本分类语料库。该语料库由复旦大学计算机信息与技术系国际数据库中心自然语言处理小组构建,语料文档全部采自互联网,可以免费下载,网址为:http://www.nlp.org.cn/categories/default.php?cat_id=16。
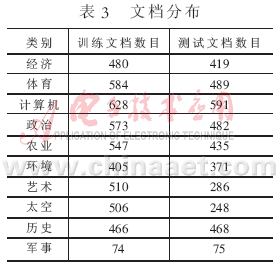
复旦大学中文文本分类语料库中包含20个类别,分为训练文档集和测试文档集2个部分。每个部分都包括20个的子目录,相同类别的文档存放在一个对应的子目录下;每个存储文件只包含1篇文档,所有文档均以文件名作为唯一编号。共有19 637篇文档,其中训练文档9 804篇,测试文档9 833篇;训练文档和测试文档基本按照1:1的比例来划分。去除部分重复文档和损坏文档后,共保留文档14 378篇,其中训练文档8 214篇,测试文档6 164篇,跨类别的重复文档没有考虑,即1篇文档只属于1个类别。该语料库中的文档的类别分布情况是不均匀的。其中,训练文档最多的类Economy有1 369篇训练文档,而训练文档最少的类Communication有25篇训练文档;同时,训练文档数少于100篇的稀有类别共有11个。训练文档集和测试文档集之间互不重叠。本文只取前10个类的部分文档,其类别文档分布如表3所示。
5.2 实验环境及参数设置
实验设备是1台普通计算机:操作系统为Microsoft Windows XP Professional(SP2),CPU规格为Intel(R) Celeron(R) CPU 2.40 GHz,内存512 MB,硬盘80 GB。
进行中文分词处理时,采用的是中科院计算所开源项目“汉语词法分析系统ICTCLAS”系统。
实验使用的软件工具是Weka,这是纽西兰的Waikato大学开发的数据挖掘相关的一系列机器学习算法。实现语言是Java,可以直接调用,也可以在代码中调用。Weka包括数据预处理、分类、回归分析、聚类、关联规则、可视化等工具,对机器学习和数据挖掘的研究工作很有帮助,是开源项目,网址为:http://www.cs.waikato.ac.nz/ml/weka/。实验使用的计算工具为MATLAB 7.0。
5.3 实验所用分类器及其评价标准
本实验旨在比较本文方法与信息增益(IG)、x2统计量(CHI)、互信息(MI)等3种特征选择方法对后续文本分类精度的影响,因此本实验在各种特征选择方法后采用相同的分类器对文本进行分类。本实验中使用KNN分类器来比较这几种特征选择方法(K设置为10)。
为了评价实验效果,实验中选择分类正确率和召回率作为评价标准:准确率(Precision)=a/(a+b),它是所判断的文本与人工分类文本吻合的文本所占的比率;召回率(Recall)=a/(a+c),是人工分类结果应有的文本与分类系统吻合的文本所占的比率。在实际中,查准率比查全率重要。其中a、b、c代表相应的文档数,它们的含义如表4所示。

5.4 实验结果
表5总结了四种方法在所选数据集上的分类准确率和召回率,从总体上看,本文方法>IG>CHI>MI。由于本文方法使用了优化的RBF网络对特征进行优选,使得选择出的特征子集较优秀,所以效果最佳;由于IG方法受样本分布影响,在样本分布不均匀的情况下,它的效果就会大大降低,但从整体上看本文所选样本分布相对均匀,只有极个别相差较大,所以总体效果次之;由于MI方法仅考虑了特征发生的概率,而CHI方法同时考虑了特征存在与不存在时的情况,所以CHI方法比MI方法效果要好。总的来说,本文所提的方法是有效的,在文本挖掘中有一定的实用价值。

本文首先提出了一个自适应量子粒子群优化算法,用于训练RBF网络的基函数中心和宽度,并结合最小二乘法计算网络权值,对RBF网络的泛化能力进行改进。然后把该RBF神经网络用于特征选择。实验结果表明,采用自适应量子粒子群优化算法获得的RBF网络模型不但具有很强的泛化能力,而且具有良好的稳定性,能够选择出较优秀的特征子集。特征选择方法与3种经典特征选择方法“信息增益”和“统计量”以及“互信息”相比有较高的准确率和召回率,为后续的知识发现算法减少了时间与空间复杂性,从而使得本文方法在文本分类中有一定的使用价值。
参考文献
[1] DELGADO M, MARTIN-BAUTISTA M J, SANCHEZ D, et al. Mining text data: special features and patterns [C]//In Proceedings of ESF Exploratory Workshop. London: U.K, Sept, 2002:32-38.
[2] 朱颢东,钟勇.一种新的基于多启发式的特征选择算法[J].计算机应用,2009,29(3):849-851.
[3] FRIEDMAN N, GEIGER D, GOLDSZMIDT M. Bayesian network classifiers[J]. machineIearning,1997,29(2):131-163.
[4] 张海龙,王莲芝.自动文本分类特征选择方法研究[J].计算机工程与设计,2006,27(20):3838-3841.
[5] 蒋华刚,吴耿锋.基于人工免疫原理的RBF网络预测模型[J].计算机工程,2008,34(2):202-205.
[6] 颜声远,于晓洋,张志俭,等.基于RBF网络的显示设计主观评价方法[J].哈尔滨工程大学学报,2007,28(10):1150-1155.
[7] 臧小刚,宫新保,常成,等.一种基于免疫系统的RBF网络在线训练方法[J].电子学报,2008,36(7):1396-1400.
[8] 刘鑫朝,颜宏文.一种改进的粒子群优化RBF网络学习算法[J].计算机技术与发展,2006,16(2):185-187.
[9] 陈伟,冯斌,孙俊.基于QPSO算法的RBF神经网络参数优化优化仿真研究[J].计算机应用,2006,26(8):19-28.
[10] SUN Jun, FENG Bin, XU Wen Bo. Particle swarm pptimization with particles having quantum behavior[A] Proceeding of 2004 Congress on Evolutionary Computation[C].Piscataway CA: IEEE Press, 2004:325-330.