
摘 要: 非均衡数据集的分类过程中,产生了向多数类偏斜、少数类识别率较低的问题。为了提高少数类的分类精度,提出了一种S-SMO-Boost方法。该方法基于Adaboost提升算法迭代过程中错分少数类样本,构造虚拟样本,以加强对易错分样本的训练;其中构造样本利用空间插值方法,即在错分少数类样本周围构造超几何体,在该超几何体内部空间随机插值产生有效虚拟样本。在实际数据集上进行实验验证,结果表明,S-SMO-Boost方法提高了非均衡数据集的分类性能。
关键词: 非均衡数据集;超几何体;样本生成;提升算法
非均衡数据集的分类问题是模式识别和机器学习的研究热点。所谓非均衡数据集是指数据集合中,某些类的数据样本较多,而其他类数据样本较少[1]。样本较少的为少数类,样本较多的为多数类。非均衡数据集分类问题可应用于风险管理、网络入侵检测、银行预测、医疗诊断等领域。例如,医生疾病诊断中错将癌症病人诊断为正常人,损失会很大。这种情况下少数类样本却是人们更加关注的。针对该特点,传统的分类算法不再适用,有必要寻求好的分类方法使其在类别不均衡条件下,提高对少数类的识别率。
目前,解决非均衡数据集分类问题主要通过两种途径:算法层面方法和数据层面方法。算法层面方法主要是对已有分类算法进行改进或提出新的算法,如李亚军等[2]提出的改进的Adaboost算法与SVM的组合分类器。数据层面的解决办法有欠抽样方法,随机去掉部分多数类样本使不同类别样本数量均衡,此方法缺点是丢失了多数类的一些重要信息,造成分类性能降低。改进的欠抽样方法有托梅克联系对(Tomek Link)[3]方法、压缩最近邻法(CNN)[4]。简单的过抽样方法随机复制少数类样本的缺点是易导致过学习。Chawla 等[5]提出了SMOTE(Synthetic Minority Over-sampling Technique)方法,人工合成少数类样本,但是生成样本范围受到极大限制。本文提出了S-SMO-Boost方法,利用Adaboost提升算法,每次迭代不仅仅增大错分样本权值,还从迭代过程中抽取错分少数类样本,并对该部分样本进行过抽样,过抽样过程采用SMOTE的改进方法——空间插值法,增强对错分少数类样本的训练,以训练出一个强分类器,提高分类性能。



空间插值法的基本思想如下:
(1)对少数类样本pi,利用欧式空间距离公式求其k(k=5)近邻。
(2)利用该少数类及其k近邻构造超几何体(三维空间中为四面体),在该超几何体内随机插值,产生虚拟少数类样本,相比SMOTE方法,生成样本范围变大。对于存在多数类近邻的少数类,更容易被错分,故在分类过程中贡献较大,因此构造部分边界虚拟少数类样本。图3表示利用空间插值法在超几何体内随机产生虚拟少数类样本。


其中,TP与TN分别表示正确分类的少数类与多数类数量,FP与FN分别表示错分为少数类与多数类的样本数量。G-mean值中TP/(TP+TN)指少数类精确度,TN/(TN+FP)指多数类精确度,只有两者的值都大时,几何均值才会大,因此几何均值能合理地评价非均衡数据集的整体分类性能。F-value值中Recall=TP/(TP+FN)与Precision=TP/(TP+FP)分别表示少数类查全率和查准率,两者值都大时F-value值才会大,因此F-value值能正确反映少数类的分类性能。
图5表示分别用四种方法对4个数据集分类时得到的少数类F-value值。同种方法得到的F-value值点用线连起可清晰显示,利用S-SMO-Boost方法得到的F-value值相比其他方法均有一定程度的提高。
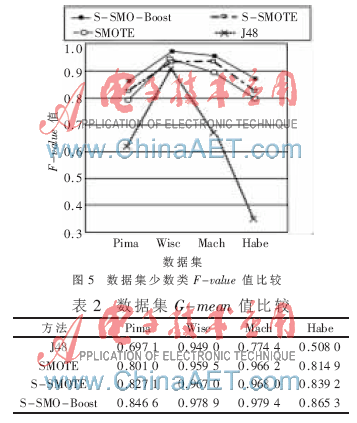
表2对不同方法,分别比较了4个数据集的G-mean值,由实验结果可知,直接用J48进行分类得到的值最小,因为数据集严重不均衡。相比SMOTE方法,S-SMOTE在少数类邻域空间内插值产生有效虚拟样本,并加强靠近边界少数类样本的训练,故分类性能相对较好。S-SMO-Boost将空间插值法融入提升算法,在迭代过程中利用错分样本产生虚拟样本,增强对错分少数类样本的训练,且增大错分样本的权值,加大迭代中作训练集的概率,并将弱分类器组合成强分类器。由表2知,用S-SMO-Boost方法得到的G-mean值最大,提高了非均衡数据集的整体分类性能。
为了解决非均衡数据集中少数类识别率较低的问题,本文提出了S-SMO-Boost 方法,利用空间插值方法,产生有效虚拟样本,并将其与提升算法融合,加强对错分少数类样本的训练。经实验验证,该方法提高了少数类识别率和数据集整体分类性能。
参考文献
[1] WEISS G.Mining with rarity:an unifying framework[J].Sigkdd Explorations,2004,6(7):7-19.
[2] 李亚军,刘晓霞,陈平.改进的AdaBoost算法与SVM的组合分类器[J].计算机工程与应用,2008,44(32):140-142.
[3] TOMEK I.Two modi-cations of CNN[J].IEEE Transactions on Systems Man and Communications,1976,SMC-6:769-772.
[4] MANNILA,LIU,MOTODA.Adavances in instance selection for instance-based leaning algorithms[J].Data Mining and Knowledge Discovery,2002(6):153-172.
[5] CHAWLA N,BOWYER K,HALL L,et al.SMOTE:synthetic minority over-sampling echnique[J].Journal of Artificial Intelligence Research,2002(16):321-357.
[6] BLAKE C,MERZ C.UCI repository of machine learning databases[DB/OL].1998.http://archive.ics.uci.edu/ml/.