
摘 要: 针对传统MapReduce框架中任务节点和工作节点的失效问题,提出了在配置备份节点的分层主从式MapReduce框架中加入单元集群的处理方法。在改进框架中,任务处理的最小单位是单元集群,当单元集群中的某个工作节点失效或者超过时间阙值时,子任务节点则选择该单元集群中的空闲工作节点来分配任务,并且不需要重新传输任务文件分块,这既节省了工作节点重选择的时间,又降低了网络传输的压力。使用该框架针对不同数量的数据块进行实验,工作节点的灾难恢复时间均可以节省25 ms左右,证明了单元集群的处理方法可以有效解决工作节点的失效问题。
关键词: Hadoop架构;MapReduce框架;任务节点;工作节点;备份节点;节点失效;单元集群
随着互联网的迅猛发展,基于互联网的数据蕴含着丰富的信息,云计算[1]就是在这样一种对大规模计算能力的强烈需求环境下发展起来的。Hadoop[2]云计算平台是Apache的一个分布式计算开源框架,其核心是MapReduce[3]和Hadoop Distribute File System[4]。
1 MapReduce框架简介
MapReduce是一种处理海量数据的并行编程框架,其主要思想是将要执行的问题进行分割,数据被分割后通过Map函数的程序将数据映射到不同区块,分配给PC集群来处理,再通过Reduce函数的程序将结果汇总,输出要得到的结果。
1.1 算法流程
用户程序调用MapReduce函数时会引起如下操作:
(1)利用MapReduce函数库把输入文件分成M块,每块大概16 MB~64 MB,并在集群中的Worker节点上执行程序的备份;
(2)Master节点找出空闲的Worker节点并为它们分配子任务;
(3)被分配到Map任务的Worker节点读取已经分割好的文件块,计算生成中间结果,中间结果暂时缓冲到内存;
(4)中间结果周期性地写入本地,中间文件通过分区函数分成R个分区,并将它们在本地磁盘的位置信息发送给Master节点;
(5)被分配到Reduce任务的Worker节点根据Master提供的中间文件位置信息远程读取相应Worker节点的中间文件;
(6)执行Reduce,计算并输出结果。
1.2 Hadoop中的MapReduce
Hadoop中对MapReduce的处理是在原算法中加入了两个处理:Split(分割)和Shuffle(混合),框架如图1所示。
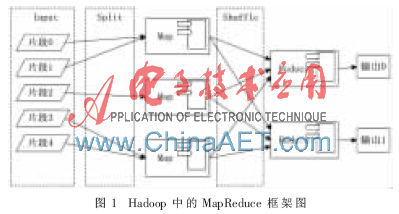
图1中,Split过程可以看作是Input的再次分割,用以控制分块的大小,Shuffle过程可以看作是在执行Map任务的Worker节点上执行本地的Reduce过程。
2 MapReduce框架的相关改进
2.1 MapReduce Online
MapReduce Online框架[5]将Map任务产生的中间数据在执行映射任务的Worker节点和执行规约任务的Worker节点间通过管道进行传输,使得下游数据元素可以在上游数据元素完成执行前开始消耗数据,增加了并行机会,提高了利用率,减少了响应时间。
2.2 Map-Balance-Reduce
Map-Balance-Reduce模型[6]针对MapReduce模型中存在的多个Reduce任务之间完成时间差别较大的问题而提出。通过添加Balance任务对Map任务处理完成的中间数据进行均衡操作,使分配到Reduce任务节点的数据比较均衡,从而确保Reduce任务的完成时间基本一致。
2.3 Shuffle阶段的优化与重构
该方案在执行Map任务的Worker节点上压缩产生的中间文件、重构远程数据拷贝传输协议(从Http协议到UDT协议)以及Reduce端内存分配优化3个方面[7]来优化和重构Shuffle阶段,从而达到提高MapReduce的计算性能。
3 传统MapReduce框架中节点失效的问题
MapReduce框架不同于其他传统系统框架设计的一点在于其将框架中的每个节点都当作一种不稳定的资源来对待,每个节点的失效都当作是一种系统常态并且有着相应的处理方式。
3.1 Master节点的失效问题
MapReduce框架中,唯一的Master节点管理数据分块、Worker节点分配、记录节点状态以及选择空闲节点等众多事务,一旦Master节点失效,“重新执行”的操作对之前的工作是一种极大的浪费并且大大延长了任务执行时间,这对需要进行海量数据计算的系统是不能接受的。参考文献[8]提出了“配置备份节点的分层主从式MapReduce框架”的解决方案,该方案可以在一定程度上缓解Master节点的任务压力并且提高了Master节点的安全性,具体框架如图2所示。
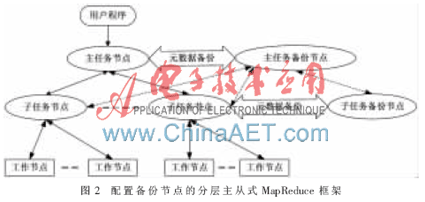
在这个MapReduce框架中,各个节点的工作职责是:
(1)主任务节点:主要对集群进行管理以及第一次任务的委派,在任务委派完之后不需要担心任务的完成情况,只需要专心地完成与子任务节点的联系,并对元数据进行管理,同时应对节点失效的问题。
(2)子任务节点:主要与用户程序进行通信,完成用户程序发出的任务并将结果返回给用户程序;它们直接受主任务节点的管理,也直接管理工作节点,起到承上启下的作用。
(3)工作节点:直接受子任务节点的管理,完成分配的任务。
3.2 Worker节点的失效问题
对于Worker节点的状态判定,MapReduce框架是让Master节点周期性地ping每个Worker节点,当无法得到Worker节点的应答时,Master节点就认为这个节点是失效的。可以将失效的Worker节点上的任务以及所处状态处理措施分为4类,如表 1 所示。

针对Worker节点的失效问题,采用引入单元集群的处理方法,该方案可以方便Master节点对Worker节点的管理并降低Worker节点失效的影响。
4 改进型MapReduce框架设计
4.1 单元集群
在传统MapReduce框架中,庞大的机器集群是进行Map任务和Reduce任务的计算资源,集群中除了Master节点之外的每个机器都可以是Worker节点。通常情况下,这个集群的数量是以万为计数单位的。为了让Master节点更好地管理这样一个庞大的机器集群,引入了“单元集群”的概念。
4.1.1 基本概念
单元集群就是拥有X个Worker节点的一个小机器集群,整个机器集群由多个单元集群组成,单元集群从Master节点处接受X个任务,该单元集群中Worker节点也都获取这X个任务所对应的文件分块并将其存储在自己的本地磁盘中,每个Worker节点执行这X个任务中其中一个,如节点1执行任务1,节点2执行任务2,…,节点X执行任务X。
Master节点对其管理的单元集群设置一个“任务执行时间阙值T”,单元集群中的Worker节点的3个状态以及处理措施如下:
(1)正常状态:正常执行完X个任务,然后开始向Mas-
ter节点请求新的任务或者接受其他单元集群的任务;
(2)超过时间阙值状态:当单元集群中的Worker节点i执行当前任务i的时间超过了T,则启动该单元集群中的空闲节点k执行任务i,因为该单元集群中的每个节点初始化时已经获取了任务i对应的文件分块,所以节点k可立即开始执行任务i。当节点k也超过时间阙值T时,处理方法一样,直到该任务在任一节点上执行完成;
(2)失效状态:当单元集群中的Worker节点j失效时,Master节点优先在该单元集群中寻找空闲节点(或已经执行完本身任务的节点)来执行这个失效节点j上的任务j,同样也不需要进行文件分块的重新获取,如果失效节点j所在的单元集群中没有空闲节点或已执行完任务的节点,Master节点就去寻找空闲的单元集群的Worker节点来执行该任务。
4.1.2 主要改进
单元集群的引入能够很好地解决Worker节点失效和工作效率不高的问题,单元集群所带来的优化如下:
(1)单元集群中的Worker节点失效或者执行时间超过阙值时,Master的处理方案是先从失效节点所在的单元集群中寻找合适的节点,节省了在整个机器集群中寻找合适节点的时间;
(2)单元集群中的节点在初始化时都获取了X个任务文件分块,正常工作的节点可以立即执行失效节点的任务而不需要重新获取文件分块,这降低了网络传输的压力,Worker节点失效或者执行时间超过阙值不会对系统效率有太大影响;
(3)Master节点的执行单位从单个节点变成单元集群,其只需要考虑单元集群的失效率和工作效率。只要单元集群中还有正常工作的Worker节点,Master节点就认为该单元集群仍然处于正常工作状态。
4.1.3 单元集群的X的取值
首先,X不宜偏大,单元集群中的每个节点都需要存储这个单元集群所要执行任务对应的文件分块,节点过多会在初始化时网络传输过多的文件分块给每个节点,将增加每个节点的网络传输压力并且延长初始化时间从而降低系统执行效率。单元集群在未执行完成分配的所有任务之前是不接受其他单元集群任务的,X偏大就有可能导致单元集群的节点不能得到充分利用;其次,X不宜偏小,单元集群节点偏少时,若单元集群中出现节点失效或者运行效率低下的情况,且该单元集群中其他的节点也在执行自己的任务,而这个任务又不能及时交给其他单元集群去执行,则失效节点所负责的任务执行就会成为系统效率的瓶颈,从而导致整个系统的效率偏低,而且单元集群节点偏少也在一定程度上增大了单元集群的失效率。
4.2 改进框架设计
改进型MapReduce框架结合了“配置备份节点的分层主从式MapReduce框架”和“单元集群”,能够同时解决Master节点和Worker节点失效问题,如图3所示。
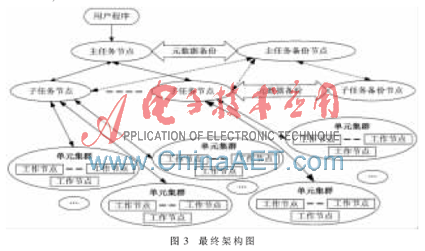
通过引入两层Master节点来解决Master节点任务压力过大的问题,通过对Worker节点采取单元集群的处理来解决其失效和效率不高的问题,以下通过实验验证这样的改进框架设计是合理且有效的。
5 实验结果分析
实验所使用的测试系统是目前运用MapReduce最广泛的搜索领域,但实验中使用的测试数据相对于当前搜索网站所涉及的数据要简单。
5.1 实验环境
集群中主任务节点、子任务节点以及工作节点都使用相同的软硬件,Hadoop为0.22.1版本,任务文件块的数量设置为500、1 000、1 500,并且文件块的大小设置为64 MB。
针对传统框架,使用4台PC来模拟Master节点、Worker节点以及客户端,其中Master节点和客户端安装在一台计算机上,另外3台PC作为Worker节点使用。
针对改进框架,使用15台PC来模拟主任务节点、子任务节点、工作节点、备份节点以及客户端,取单元集群的X=5,主任务节点和客户端安装在一台PC上,2个子任务节点安装在2台PC上,2个备份节点分别安装在2台PC上,另外10台PC分别作为2个单元集群中的Worker节点。
5.2 实验数据及结果分析
首先,在客户端随机生成50 000个整数(0~49 999),在传统框架下,将这些整数文件分成多个文件块,并均分存储到3个Worker节点上;若在改进框架下,将这些整数文件分成多个文件块,并均分这些文件块到2个单元集群上;然后,客户端将一个MapReduce任务(搜索最大值)交给机器集群来进行实验。
在传统框架和改进框架下的运行结果如表2所示。
Worker节点的灾难恢复时间是实验重点关注的参数指标。节点的灾难恢复时间包括:重新选择节点、IP地址的迁移、网络传输时间以及数据块的迁移时间,在单元集群改进框架中,Worker节点的灾难恢复时间只包括重新选择节点和IP地址的迁移这两部分时间。从表2可以看出改进框架相比较传统框架,其Worker节点的灾难恢复时间降低了25 ms左右。
通过测试数据可以得出:单元集群的改进框架与传统框架相比,降低了Worker节点的灾难恢复时间,从而在一定程度上解决了Worker节点的失效问题。
针对传统MapReduce框架中存在的Master节点和Worker节点失效的问题,采用了在“配置备份节点的分层主从式MapReduce框架”中加入单元集群的方案,单元集群包括多个Worker节点,这些Worker节点上都备份了所在单元集群所要处理的所有任务文件分块,当Worker节点失效或超过时间阙值时,Master节点会选择其所在单元集群中的空闲节点来执行失效节点的任务,这不仅将单一Worker节点的失效问题转移到单元集群上,而且也解决了当出现节点失效时还需要重新传输任务文件分块的问题。单元集群的提出虽然在一定程度上解决了Master节点和Worker节点的失效问题,但是因为需要在初始化整个系统时多传输一部分任务文件分块,这样就牺牲了一部分的系统性能,并且在单元集群的X取值上并没有一个特定的方案,只能通过大量的实验测试才能得到合适的取值,这也是未来研究的一个方向。
参考文献
[1] 陈康,郑纬民.云计算:系统实例与研究现状[J].软件学报,2009,20(5):1337-1348.
[2] WHITE T.Hadoop:the definitive guide[M].California:O′Reilly Media,2012.
[3] DEAN J,GHEMAWAT S.MapReduce: simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[4] BORTHAKUR D.HDFS architecture guide[DB/OL].Hadoop apache project.(2008-02-14).[2013-04-22].http://hadoop.apache.org/common/docs/current/hdfsdesign.pdf.
[5] CONDIE T,CONWAY N,ALVARO P,et al.MapReduce online[C].Proceedings of the 7th USENIX Conference on Networked Systems Design and Implementation,2010:21-21.
[6] 李玉林,董晶.基于Hadoop的MapReduce模型的研究与改进[J].计算机工程与设计,2012,33(8):3110-3116.
[7] 彭辅权,金苍宏,吴明晖,等.MapReduce中shuffle优化与重构[J].中国科技论文,2012,7(4):241-245.
[8] 周一可.云计算下MapReduce编程模型可用性的研究与优化[D].上海:上海交通大学,2011.