
摘 要: 针对目前主题爬虫采用“启发式”搜索策略出现的“近视”缺点,提出了一种基于蚁群算法的主题爬虫搜索策略。该方法将蚁群算法引入到主题爬虫的搜索策略中,并对蚁群算法中信息素的更新计算进行了改进,使其具有一定的自适应性。通过与其他搜索策略的比较实验,结果表明该算法能够更好地提高爬虫的全局搜索能力。
关键词: 主题爬虫;蚁群算法;搜索策略;信息素
主题网络爬虫是根据一定的网页分析算法,过滤与主题无关的链接,保留主题相关的链接并将其放入待抓取的超链接队列中,然后根据一定的搜索策略从队列中选择下一步要抓取的网页链接,并重复上述过程,直到达到系统的某一条件时停止。所有网络爬虫抓取的网页将会被系统存储,进行一定的分析、过滤,并建立索引[1]。相对于通用爬虫,主题爬虫搜索的内容只限于特定主题或专门领域,因而被通用网络爬虫广泛采用的基于广度或深度优先算法已不再适用。目前,主题网络爬虫通常采用启发式搜索策略,每次选择“最有价值”链接进行优先访问,但是这类策略容易过早陷入Web搜索空间中局部最优子空间的陷阱,缺乏全局性,从而导致整体回报率不高[2]。
蚁群算法不仅能够智能搜索和全局优化,而且还具有鲁棒性、正反馈、分布式计算、易于与其他算法结合等特点。利用正反馈原理,可以加快进化过程。分布式计算使该算法易于并行实现,个体之间不断进行信息交流和传递,有利于找到较好的解,不容易陷入局部最优。易与多种启发式算法结合,可改善算法的性能。稳健性强,故在基本蚁群算法模型的基础上进行修改,便可用于其他问题。
结合蚁群算法,本文针对主题爬虫搜索策略上的不足,提出了一种基于蚁群算法的主题爬虫搜索策略。由于对蚁群算法进行了改进,所以提出的算法还具有一定的自适应性。
1 蚁群算法模型
蚁群算法是群集智能体现的一个典型例子,该算法是意大利学者Marco Dorigo[3]等人在1991年受蚂蚁觅食行为的启发而提出的。
蚁群算法借鉴和吸收了现实世界中蚁群的行为特征:蚂蚁属于群居昆虫,个体行为极其简单,而群体行为却很复杂。相互协作的一群蚂蚁很容易找到从蚁巢到食物源的最短路径。此外,蚂蚁还能够适应环境的变化,例如在蚁群的运动路线突然出现障碍物时,它们能够很快地重新找到最优路径。蚂蚁个体之间在觅食过程中通过信息素来进行信息传递,信息素随着时间的推移会逐渐挥发。蚂蚁在觅食过程中能够感知信息素的存在及其强度,并以此来指导自己的运动方向,倾向于朝着信息素强度高的方向移动,即选择该路径的概率与当时这条路径上信息素强度成正比。信息素强度越高的路径,选择它的蚂蚁就越多,则在该路径上留下的信息素的强度就更大,而强度大的信息素又吸引更多的蚂蚁,从而形成一种正反馈。通过这种反馈,使得大部分蚂蚁都会走这个最佳路径。
正反馈的副作用就是当许多蚂蚁都选中同一条路径时,该路径中的信息素量会迅速增大,从而使得多只蚂蚁集中到某一条路径上,造成一种堵塞和停滞现象,表现在使用蚁群算法解决问题时就容易导致早熟和局部收敛。
2 基于蚁群算法的搜索策略
2.1 算法思想
本文提出了一种基于蚁群算法的主题爬虫搜索策略,其基本思想是:在Web页面中存在超文本页面wi和wj,如果wi中有一个链接指向wj,那么处于wi的蚂蚁自身将根据一定的条件决定是否从wi移动到wj。每个链接序列代表了一个可能的蚂蚁移动路线。蚂蚁个体之间在移动过程中通过信息素来进行信息传递。信息素在蚂蚁爬行过程中会随着时间的推移逐渐挥发。蚂蚁在页面之间的爬行被分为多个循环周期,在每个周期中,一个蚂蚁在Web页面间进行一系列的移动,直到探寻到目标资源并返回到源点为止。每完成一次爬行周期,蚁群对各路线上的信息素量进行更新。为解决蚁群算法的“早熟”和“局部收敛”问题,本文借鉴了参考文献[4]中动态自适应的调整信息素的思想。
假设V代表全体页面集合,E代表由链接构成的路径集合,则Web页面(链接)构成有向图G={V,E}。因为蚂蚁在选择下一个Web页面时必须考虑其主题相关度,所以有向图G中页面Pk的主题相关度值可以参考PageRank算法公式。
为方便表述,作如下定义[5]:


其中c为常数。这样,根据解的分布情况自适应地进行信息素量的更新,从而动态地调整各路径上的信息素量强度,使蚂蚁既不过分集中也不过分分散,从而避免了早熟和局部收敛,提高全局搜索能力[5]。
2.3 算法流程
提出的基于蚁群算法的爬虫搜索策略执行过程如下:

2.4 算法参数分析
在蚁群算法的实现过程中,多个参数需要初始化设定。由蚁群算法的原理可知,不同参数的选择能够对蚁群算法的性能产生至关重要的影响[5]。目前对蚁群算法中参数的确定还没有严格的理论基础,所以以上诸式中出现的参数ηij、α、β和ρ通常用试验方法来确定其最优组合。ηij表示由城市i转移到城市j的期望程度,可根据某种启发算法而定,例如可以取ηij=1/dij。α表示蚂蚁在行进过程中所积累的信息素对它选择路径所起的作用程度。β是一个表示信息素重要程度的参数。信息激素的保留系数为ρ(0<ρ<1),它体现了信息素强度的持久性,而1-ρ则表示信息素的消逝程度。
参考文献[6]通过大量的实验数值分析表明,当满足0.01≤α≤0.3、3≤β≤6、0.1≤ρ≤0.3时,算法总体上有较好性能,达到的最优解与全局最优较接近,同时,所需的迭代次数也较少,不易陷入局部最优而导致算法停滞。
3 实验
3.1 实验说明
为了验证基于蚁群算法的主题爬虫搜索策略比传统的广度优先算法和基于最佳优先搜索策略具有更好的全局搜索能力和自适应性,本文在Nutch爬虫的基础上构建了一个主题爬虫。Nutch爬虫具有可扩展和定制性。通过定义一个ACOCrawler插件来抓取特定主题的网页[8]。实现以“物理教学资源”为主题,选取了国内三个教育网站为种子集(如表1所示),算法参变量设定如表2所示。

3.2 结果分析
系统运行12个小时,共抓取3 360 000个网页及资源。为了便于比较,分别对基于广度优先算法和最佳优先搜索算法的搜索结果进行测试,统计三种搜索算法实现的爬虫所搜索的关于物理教学资源的网页及资源数,采用“相对回报率”来评价爬虫的性能。相对回报率R的计算公式为:

通过计算,可以得到三种算法性能比较图,如图1所示。
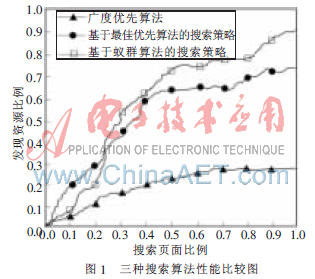
由图1可以看出,在三种搜索策略中,广度优先算法的性能低于其他两种“启发式”算法。这两种搜索策略在访问了50%的页面后,已经找到了70%以上的相关物理资源,这表明基于“启发式”搜索策略具有优越性。
基于蚁群算法的搜索策略性能比较显著,除了在搜索初期其发现能力略低于基于最佳优先策略的搜索算法外,在其后的搜索中,新算法的性能明显高于基于最佳优先策略的搜索算法。其原因在于,基于蚁群算法的搜索策略采用了一种最优选择机制,一旦蚁群发现有好的全局最优个体,动态地更新路径上的信息素,作为最优选择路径,从而避免了局部最优,因而整体回报率较高。
本文针对现有主题爬虫所采用搜索策略出现的一些问题,将蚁群搜索模型引入主题爬虫搜索策略。实验结果表明,基于蚁群算法的搜索策略与基于广度优先搜索策略和基于最佳优先搜索策略相比,其在主题相关性上有比较明显的优势。通过对蚁群算法进行改进,能够动态地调整信息素,从而也能够较好地解决局部最优问题,提高了全局搜索的能力。但由于蚁群算法本身的一些缺陷,使得主题爬虫在搜索效率上还有待提高,这是下一步要做的工作。
参考文献
[1] 刘金红,陆余良.主题网络爬虫研究综述[J].计算机应用研究,2007(10):26-29.
[2] 李学勇,田立军,谭义红,等.一种基于非贪婪策略的网络蜘蛛搜索算法[J].计算机与自动化,2004,23(2).
[3] DORIGO M, MANIEZZO V, COLORNI A. The ant system: optimization by a colony of cooperating agents[J]. IEEE Transactions on Systems, Man and Cybernetics—Part B, 1996, 26(1): 29-41.
[4] 李开荣,陈宏建,陈崚.一种动态自适应蚁群算法[J].计算机与自动化,2004,40(29):149-152.
[5] 陶剑文.基于蚁群计算的自适应Web检索算法设计[J]. 计算机工程与应用,2007(15):163-165.
[6] 蒋玲艳,张军,钟树鸿.蚁群算法的参数分析[J].计算机工程与应用,2006(13):31-35.
[7] MENCZER F, PANT G, SRINIVASAN N P. Topical Web crawler: evaluating adaptive algorithms[J]. ACM Transactions on Internet Technology, 2004(4): 378-419.
[8] 荣光,张化祥.一种DeepWeb爬虫的设计与实现[J].计算机与现代化,2009(3):32-34.