
摘 要: 动态时间规整DTW是语音识别中的一种经典算法。对此算法提出了一种改进的端点检测算法,特征提取采用了Mel频率倒谱系数MFCC,并采用计算量相对较小的改进的动态时间规整算法实现语音参数模板匹配,能够实现孤立词、特定人、小词汇量的语音识别,并用Matlab进行了算法仿真。试验结果表明,改进后的算法能够有效地提高系统对语音的识别率。
关键词: 语音识别;端点检测;Mel倒谱参数;动态时间规整
在孤立词语音识别中,最为简单有效的方法是采用动态时间规整DTW(Dynamic Time Warping)算法,该算法基于动态规划(DP)的思想,解决了发音长短不一的模板匹配问题,是语音识别中出现较早、较为经典的一种算法。DTW是把时间规整和距离测度计算结合起来的一种非线性规整技术,算法较为简洁,正确率也较高,在语音识别系统中有较广泛的应用。
本文对DTW算法提出了一种改进的端点检测算法,对提高系统的识别率有很好的实用价值[1]。
1 语音识别系统与DTW算法原理
本质上讲,语音识别就是语音信号模式识别[2],它由训练和识别两个过程完成。训练过程是从某一说话人大量语音信号中提取出该说话人的语音特征,并形成参考模式。识别过程是从待识语音中提取特征形成待识模式,与参考模式进行模式匹配、比较和判决,从而得出识别结果。本系统的结构如图1所示。

假设测试和参考模板分别用T和R表示,它们之间的相似度用其之间的距离D[T,R]来度量,距离越小相似度越高[3]。为了计算这一失真距离,要从T、R中各个对应帧之间的距离算起。设n、m分别是T、R中任意选择的帧号,d[T(n),R(m)]表示这两帧特征矢量之间的距离(在DTW算法中通常采用欧式距离)。
如图2所示,横轴上标出的是测试模板T的各个帧号n=1~N,纵轴上是参考模板R的各个帧号m=1~M,N≠M。网格中的每一个交叉点(n,m)表示测试模式中某一帧与训练模式中某一帧的交汇点。DP算法就是寻找一条通过此网格中若干个格点的路径。路径不是随意选择的,首先任何一种语音的发音快慢都有可能变化,但是其各部分的先后次序不可能改变,因此所选的路径必定是从左下角出发,在右上角结束。


式中,sgn[ ]是符号函数。
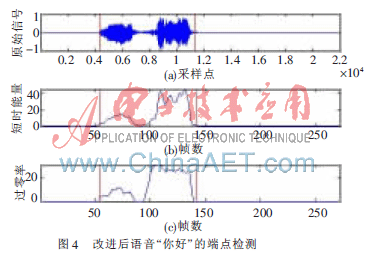
为了提高端点检测的精度,采用短时能量和过零率进行端点检测[4]。语音采样频率为8 kHz,量化精度为16 bit。数字PCM码首先经过预加重滤波器H(z)=1-0.95z-1,再进行分帧和加窗处理。在实验中发现,双门限端点检测算法对于两个汉字和三个汉字的语音命令端点检测效果不好。以语音“你好”为例,如图3语音波形图中,端点检测只能检测到第1个字。

如果语音命令中两个字的间隔过长,使用双门限端点检测法会发生只检测到第一个字的情况,从而可能造成语音匹配错误。为避免该错误,把可容忍的静音区间扩大到15帧,如15帧内一直没有能量和过零率超过最低门限,则认为语音结束;如发现仍然有话音,则把能量和过零率计算在内[5]。
整个语音信号的端点检测流程设计为四个阶段:静音段、过渡段、语音段和语音结束。在静音段,如果能量或过零率超越低门限,就开始标记起始点,进入过渡段。在过渡段,由于参数的数值较小,不能确信是否处于语音段,因此只要两个参数的数值都回落到低门限以下,就将当前状态恢复到静音状态;而如果在过渡段中两个参数中的任何一个超过了高门限,就可以确信进入语音段。在语音段,如果两个参数的数值降低到低门限以下,且一直持续15帧,则语音进入停止;如果两个参数的数值降低到低门限以下,但并没有持续到15帧,后续又有语音超越过低门限,则认为还没有结束;如果检测出的这段语音总长度小于可接受的最小的语音帧数(设为15帧),则认为是一段噪音而放弃。
采用改进后的端点检测算法,对单个汉字或多个汉字的语音命令均识别正常。图4为语音“你好”的端点检测图。
2.2 语音识别的DTW高效算法
通常,路径函数Φ(ni)被限制在一个平行四边形内,平行四边形的一条边斜率为2,另一条边的斜率为1/2。路径函数的起点为(1,1),终止点为(N,M)。Φ(ni)的斜率为0、1或2。这是一种简单的路径限制,如图5所示。
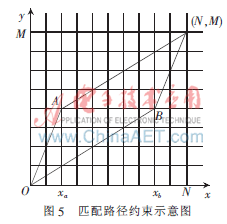
本文的目的是寻找一个路径函数,在平行四边形内由点(1,1)到点(N,M)具有最小代价函数。由于对路径进行了限制,在匹配过程中许多格点实际上是到达不了的,因此,平行四边形之外的格点对应的帧匹配距离是不需要计算的。另外,也没有必要保存所有的帧匹配距离矩阵和累积距离矩阵,因为每一列各格点上的匹配计算只用到了前一列的3个网格。利用这两个特点可以减少计算量和存储空间的需求。

如果出现Xa>Xb的情况,此时弯折匹配的三段为(1,Xb)、(Xb+1,Xa)和(Xa+1,N)。沿X轴上每前进一帧,虽然所要比较的Y轴上的帧数不同,但弯折特性是一样的,累积距离的更新都是用下式实现:
D(x,y)=d(x,y)+min[D(x-1,y),D(x-1,y-1),D(x-1,y-2)]
由于X轴上每前进一帧,只需要用到前一列的累积距离,所以只需要两个列矢量D和d分别保存前一列的累积距离和计算当前列的累积距离,而不用保存整个距离矩阵,这样可达到减少存储量和存储空间的目的。
2.3 试验结果
本系统采用改进的端点检测方法,采用MFCC(Mel Frequene Cepstrum Coeffiients)特征提取和DTW算法来实现语音识别。语音采样频率为8 kHz,16 bit量化精度,预加重系数a=0.95,语音每帧为30 ms,240点为一帧,帧移为80,窗函数采用Hamming窗。采集5个女生,10个男生的数据。共分为两组,第一组是对0~9十个数字的识别,第二组是对孤立词的识别,试验数据如表1所示。
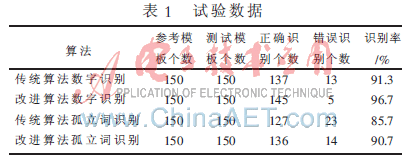
本文研究了语音识别DTW算法和理论,在应用中对双门限端点检测算法作了延长可容忍静音的改进,在说话语音识别算法上对DTW进行了改进和设计,实验结果表明,该算法可以有效地提高系统的识别率。
参考文献
[1] 何强,何英.MATLAB 扩展编程 [M].北京:清华大学出 版社,2002.
[2] CHANWOO K, KWANG D S. Robust DTW-based recognition algorithm for hand-held consumer devices[J]. IEEE Transactions on Consumer Electronics, 2005, 51(2):699-709.
[3] MIZUHARA Y, HAYASHI A, SUEMATSU N. Embedding of time series data by using dynamic time warping distances[J]. Systems and Computers in Japan, 2006, 37(3):1-9.
[4] BDULLA A, CHOW W H, SIN D, G. Cross-words reference template for DTW-based speech recognition systems[C]. Conference on Convergent Technologies for the Asia-Pacific Region,TENCON, 2003, 2003:1576-1579.
[5] 刘金伟,黄樟钦,侯义斌.基于片上系统的孤立词语音识别算法设计[J]计算机工程,2007,33(13):25-27.