
数据库远程数据上报策略及实现
2009-10-15
作者:邓其军1, 牛晓太1, 余小鹏1
摘 要: 提出了一种数据库远程数据上报的策略,并对该策略的程序实现过程作了介绍。
关键词: 远程数据 上报 数据压缩
在很多数据库应用程序中,都要用到数据远程上报的功能,如人口普查、城市危险源及事故普查、各种考试数据上报等。这些应用程序都需要将各下级部门的特定数据提取出来,通过各种方式上报到上级部门,再由上级部门进行汇总。上级部门在进行数据汇总时,有时候只需要考虑新数据的插入问题。如养路费征收IC卡网络管理系统,此时下级的每条数据记录是一次输入的,在数据上报之后不会发生已经输入的数据记录在下级被修改,从而上级也要发生相应修改的情况。此时,用该文提到的用BulkCopy方法就可以满足其需要。但是有的情况下,上级部门的数据汇总必须考虑下级数据所有的变化情况(新数据的插入、已有数据记录的修改、已有数据记录的删除)。此时,用BulkCopy方法就无法对数据进行修改与删除了。除非在数据上报时,下级部门将其所有数据都拷贝一份上传;上级部门在数据接收时,将该下级部门的历史数据全部删除,再导入其数据,才能保证与下级的数据的一致性。显然,这样的处理方式,必然导致数据的传输及处理量大增,而且很多都是做无用功,特别是在很多情况下需要用电话拨号网络进行数据传输的时候,其效率非常低。
1 总体策略
在作者参与开发的“城市重大危险源普查及事故管理系统”中,其下级部门为各企业,上级部门为政府安全生产管理部门。在该系统中,企业定期向政府部门上报相关的危险源及事故信息。其中危险源是指企业各种锅炉压力容器、加油站等可能发生危险的地点分布情况。这些危险源信息可能被增加、修改或删除。系统开发语言为VC++6.0,企业端数据库为Access或SQL Server,政府端数据库为SQL Server,用OLE DB方式连接数据库,用嵌入式SQL Server语言直接操作数据库数据。上下级之间的数据传输方式为软盘、邮件和FTP三种方案。本系统主要采用了数据库日志及数据压缩技术,尽可能地减少数据传送量。
数据库日志就是在用VC的嵌入式SQL Server语言进行数据库操作时,将SQL Server脚本经过适当的转换后记录在一个数据库日志表(pubTbDBLog)中。上报数据时只需要提取pubTbDBLog表的部分内容。政府端接收后,按顺序执行上报的SQL Server脚本,即能实现与企业端的数据完全一致。
数据上报与接收的流程如图1所示。
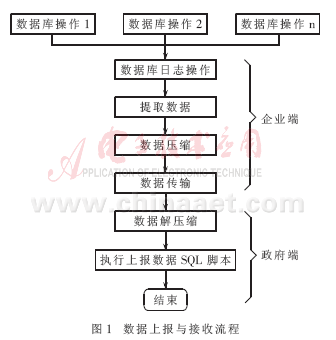
2 数据库日志操作
数据库日志操作的目的是保存SQL脚本,即将企业端对数据库的操作记录下来,存放在数据库日志记录表pubTbDBLog(nId,strTable,strSQL,strOperType,strGuid,dtOper,beUped)中。其中nId为主键,自动增量;strTable为SQL操作的数据库表名;strSQL为对数据库进行操作的脚本;strOperType为操作类型,包括插入、修改、删除三种;strGuid为一个GUID值(全球惟一ID号,长度为32位字符),用来惟一标识一条记录;dtOper为操作时间,取每条记录生成(即对数据库的每一次操作)的当前时间;beUped标识当前记录是否已经上报过。
2.1 数据库操作的要求
在本系统中,当对需要上报数据的表进行操作时,必须满足如下要求:
(1)数据库记录的修改(包括添加、删除、修改)必须在程序中直接用嵌入式SQL脚本实现。
(2)执行数据库操作必须使用一个全局函数ExecuteSQLCmd(CString strCmd),其中strCmd为执行数据库操作的SQL脚本。该函数将脚本写入pubTbDBLog表。
2.2 保存SQL脚本的过程说明
下面以企业端用户向危险源记录表rsiTbSource(nID,strEnNo,strName,strSite,strRank,strType,dtSetUp)中插入一条危险源记录为例,说明保存SQL脚本的操作过程。
(1)用户通过对话界面输入危险源信息,其中strEnNo表示企业编号,strName表示危险源名称,strSite表示危险源位置,strRank表示危险源等级,strType表示危险源类型,dtSetUp表示危险源建立日期。另外nID是一个自动增量,作为主键标识,没有具体意义。rsiTbSource表除了以上字段外,还有其他字段,本处为简化而省略。
(2)用户输入信息完毕,点击“保存”命令按钮,系统将用户输入的信息拼成一条SQL脚本,如:CString strCmd=INSERT INTO rsiTbSource(strEnNo,strName,strSite,strRank,strType,dtSetUp)VALUES(‘420124098987001’,‘热水锅炉’,‘武汉市武昌区武汉大学二区’,‘二级’,‘锅炉压力容器’,‘2003-7-21’)。
(3)系统调用ExecuteSQLCmd函数,包括以下(4)、(5)、(6)的内容。
(4)对strCmd进行解析,同时生成一个32位的GUID值,将strCmd修改为strCmd=INSERT INTO rsiTbSource(strEnNo,strName,strSite,strRank,strType,dtSetUp,strGuid)VALUES(‘420124098987001’,‘热水锅炉’,‘武汉市武昌区武汉大学二区’,‘二级’,‘锅炉压力容器’,‘2003-7-21’,‘ed32wq3ddvervgjl6tgj8fjFFVBfgwgw’)。
(5)执行脚本命令(不使用ExecuteSQLCmd函数)。
(6)如果第(5)步执行成功,则向pubDBLog表插入一条记录(strTbSource,strCmd,i,ed32wq3ddvervgjl6tgj8fjFFVBfgwgw,2003-7-21,0),其中的strCmd是第(4)步中strCmd的所有字符。
3 数据上报
数据上报是将pubTbDBLog中符合条件的记录提取出来,进行压缩后传给上级。
3.1 上报数据提取
在提取数据前要对pubTbDBLog表中的记录进行一些预处理。由于每次对需要上报的数据库表的操作都被记录在了pubTbDBLog表中,有些记录(为了方便,称pubTbDBLog表中的一条记录为“记录”,称需要上报的数据表中的一条记录为“数据”)是不必要的,上报之前需要进行简化。例如:向数据库表中插入一条数据,后来对该数据进行了若干次修改,最后删除该条数据。此时,pubTbDBLog中有三个以上与这条数据相关的记录(它们在pubTbDBLog表中的strGuid字段值相同),其strOperType值分别是“i”、“u”、“d”。如果这三个记录都被上报,并在政府端被先后执行,其结果还是没有该条数据,白白浪费了执行三次SQL命令的时间。
因此,如果与某个strGuid值相关的数据最后被删除,则在政府端只需要执行一次删除操作,即与该strGuid值相关的pubTbDBLog表中的记录只需要上报一条删除的操作即可。实现对这种情况的pubTbDBLog表简化的SQL脚本如下:
DELETE FROM pubTbDBLog WHERE strOperType <> ′d′
AND strGuid IN(SELECT DISTINCT a.strGuid
FROM pubTbDBLog a WHERE a.strOperType=′d′)
完成简化后,即可将pubTbDBLog中符合条件(提取数据的条件是:未曾上报过的数据或指定时间范围内的数据)的数据提取出来放入一个文件中。存放导出数据的文件可以是Access 数据库表,或者是文本文件。作者用的是Access数据库表,它经过压缩解压缩后能在政府端直接取Access表中的SQL脚本执行;也可以用文本文件,但上报时需要将符合条件的pubTbDBLog表记录放入一个临时文件,再用bulkCopy的方法存入文本文件。在政府端用bulkInsert的方法向一个与pubTbDBLog相同结构的表导入数据,再执行该表的记录中的SQL脚本。
3.2 数据文件压缩
通常情况下,企业端向政府端报送数据是经过电话拨号网络进行的,其传输速率较低。因此,有必要对存放导出数据的Access文件或文本文件进行压缩后再传递。本系统使用了WinZip的数据压缩与解压缩接口。其过程如下(假定字符串filepathname指向需要压缩的文件):
(1)获取文件路径及文件名信息。
int nPos,length,div;
CString filepathtitle,filename;
nPos=filepathname.ReverseFind(′.′);
filepathtitle=filepathname.Left(nPos)
/*去掉扩展名后的文件名,带路径*/
length=filepathname.GetLength( );
div=filepathname.ReverseFind(′\\′);
filename=filepathname.Right(length-div-1);/*文件名,不带路径*/
(2)创建压缩文件实例。
CZipFile zf(filepathtitle+″.cmp″,0);
char buf[BUF_SIZE];//BUF_SIZE=2048
CFile f(filepathname,CFile∷modeRead);
zip_fileinfo zi;
zf.UpdateZipInfo(zi,f);
(3)向压缩文件实例读入数据。
zf.OpenNewFileInZip(filename,zi,Z_BEST_COMPRESSION);
int size_read;
do
{
size_read=f.Read(buf,BUF_SIZE);
if (size_read)
zf.WriteInFileInZip(buf,size_read);
}
while (size_read==BUF_SIZE);
zf.Close( );//关闭压缩文件实例
经测试,压缩文件的大小约为原文件大小的1/5~1/10,效果较好。
4 数据接收
政府端数据接收的工作包括三个步骤:选择文件、解压缩、导入数据。
4.1 选择数据文件
对应于企业端通过磁盘和邮件上报的数据,政府端首先需要将其存放到本地计算机的硬盘上,再进行数据文件选择和接收。
选择文件时,调用打开文件对话框,再由用户选定一个或多个指定类型(*.cmp)的文件。对于每一个选中的文件,系统对其执行解压缩和导入数据的操作。
4.2 解压缩
与前面所述的文件压缩一样,解压缩与采用了WinZip提供的接口。其过程如下:
(1)创建解压缩文件实例,并用选定的压缩文件初始化。
CUnzipFile uf(m_strCmpFile);/*m_strCmpFile为选定的压缩文件名*/
(2)获取压缩文件中被压缩前的文件信息。
/*指向压缩文件中的第一个文件(一个压缩文件可以由多个文件压缩而成,本系统只有一个)*/
uf.GoToFirstFile( )
unz_file_info ui;/*用于管理解压缩文件信息的一个结构*/
/*获取压缩文件中当前文件被压缩前的信息,如文件名大小*/
uf.GetCurrentFileInfo(&ui);
int iNameSize=ui.size_filename+1;
char*pName=new char[iNameSize];
uf.GetCurrentFileInfo(NULL,pName,iNameSize);//获取文件名
TCHAR szDir[_MAX_DIR];
TCHAR szDrive[_MAX_DRIVE];
_tsplitpath(m_strUnCmpFile,szDrive,szDir,NULL,NULL);
CString szPath=CString(szDrive)+szDir;
m_strMovedDB=szPath+pName;/*解压缩后,存放文件的路径与文件名*/
CFile f(m_strMovedDB,CFile∷modeWrite | CFile∷modeCreate);
delete[ ] pName;
(3)解压缩。
uf.OpenCurrentFile( );
char buf[BUF_SIZE];
int size_read;
do
{
size_read=uf.ReadCurrentFile(buf,BUF_SIZE);
if(size_read>0)
f.Write(buf,size_read);
}
while(size_read==BUF_SIZE);
uf.UpdateFileStatus(f,ui); /*还原文件的原来的日期和其他属性*/
uf.Close( );
4.3 导入数据
从一个被解压缩后生成的Access数据库向政府端数据库导入数据的过程为:连接该Access数据库;按先后顺序从该数据库表pubTbDBLog中提取记录;执行该条记录的SQL脚本。下面只对SQL脚本的执行进行说明。
对于删除和修改操作,SQL脚本可以直接执行。因为如果上报了重复的数据,即使某条记录已经被删除或修改,再执行一次同样的删除或修改操作,SQL命令的执行也不会造成语法错误或数据错误。
对于插入操作,SQL脚本则不能直接执行。因为如果上报了重复的数据,则直接执行插入会使数据库中存在二条同样的数据。因此,先要执行一次删除操作,将对应的数据删除(由于pubTbDBLog表中有二个字段记录了SQL脚本对应的表名和GUID值,删除操作很容量执行)。即使该数据不存在,SQL命令的执行也不会造成语法错误或数据错误。
5 结 论
本文讨论的基于数据库操作日志和数据压缩的数据上报与接收技术,有着很强的通用性。对于任何一个应用系统,只要在数据库中建立一个数据库日志表,并且下级端执行数据库操作时满足2.1中提及的二个条件,就能使用。特别是对于需要上传的数据涉及的表较多、下级端对数据经常需要修改、上下级数据要求较高度的一致性的情况,其优点更加明显。
本系统的数据上报与接收策略也有一些不足之处。例如,企业端pubTbDBLog表中数据的导出,可能用bulkCopy效率更高;数据导出与接收时,暂时还没有使用多线程技术等。这些都需要在以后的工作中进一步完善。
参考文献
1 阎宇驰,倪津.SQL Server数据库远程数据上报策略及其应用研究.山西交通科技,2002;(2)
2 罗琨,陈奇.连锁店MIS中多数据库数据通信的设计和实现.计算机应用研究,2000;(6)
3 萨师宣,王珊.数据库系统概论.北京:高等教育出版社,1999