
摘 要: 给出了数据仓库的概念和特征。结合大型超市的实际情况,描述了数据仓库的构建过程及需要注意的问题。
关键词: 数据仓库 决策支持 数据挖掘 超级市场
现代社会的发展在某种意义上取决于信息的获取与处理技术。信息的价值在于用户通过使用这些信息从中得到收益。信息工作者所面对的问题不是简单地处理数据,而是如何使用数据,即从数据中挖掘出有用的信息。就超市而言,各种商品的销售情况实际上蕴藏着某种规律性。如果能够把它挖掘出来,无疑对今后的工作有很大的帮助。
1 数据仓库的概念和特征
数据仓库指的是在关系数据库中存储数据和处理数据,并且使得数据更加有力地支持决策分析。其目标是通过收集、过滤和存储数据,寻找数据的趋势,帮助企业制定有关经营方面的决策。
这里给数据仓库一个比较完整的定义:数据仓库是面向主题的、一致的、不同时间的、稳定的数据集合,用于支持经营管理中的决策支持过程。也就是说,数据仓库是一个处理过程,该过程从历史的角度组织和存储数据,并能集成地进行数据分析。数据仓库有以下四个特征。
(1)数据仓库是面向主题的。传统的数据仓库是面向应用设计的,而主题是在一个较高层次将数据归类的标准。例如,在一个大型超市里,如果只记录原始的销售数据,则使用原始的数据库技术即可。但是如果希望对这些数据加以分析,找出哪些年龄段的人喜欢某类产品,什么时间段某类产品销量最好以及产品与销量的关系,则需要借助于数据仓库技术。
(2)数据仓库是一致的数据的集合。应用程序常常以不同的格式使用类似的数据。例如:超级市场可能表示为“超市”、“超级市场”、“supper market”等。这些数据的值必须统一才能更好地使用。
(3)存储在OLTP系统中的数据可以正确地表示任何时间的任何值。它一般表示过了一段比较长的时间的数据,通常是5~10年。这些数据一般是不改变的。而数据库通常只把有用的数据保存30~90天。
(4)数据仓库是比较稳定的。当数据移动到数据仓库后,就不再改变,除非存储的数据不正确。一般情况下,在数据仓库中发生的操作是建立数据仓库时的加载数据和查询数据。
2 建立数据仓库的过程
建立数据仓库的过程实际上是从传统的以数据库为中心的操作型系统结构转移到以数据仓库为中心的体系结构的过程。具体实现过程如下。
(1)建立企业模型,并且选取主题。企业模型是从企业用户的角度对企业所需数据的内容以及数据间关系的抽象。企业模型对大型企业是有重要意义的。有了企业模型,可以比较完整地了解企业中各方面、各阶层人员对数据的需要程度。这对建立数据仓库有很好的指导作用。图1为大型超市企业模型。
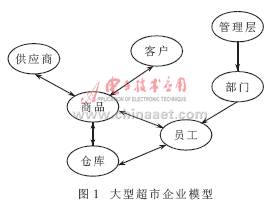
企业模型建立后,可以根据企业模型和用户需求确定系统中存在的主题。大型数据仓库涉及的系统众多、功能复杂,因此往往采取螺旋式的开发方式。将庞大的目标划分成若干个实施阶段,实际上是将一个复杂、困难的问题转化为多个比较简单明确的小问题,然后分而治之。主题选取的原则包括:优先实施企业管理者最关心的问题,优先选择在短时间内能见效的决策,优先实施投资风险低的决策。例如,管理者关心的是某一时期的销售额、利润额、市场份额等。
(2)选择数据颗粒度。对于不同的数据量,将选择不同的数据颗粒度策略。小数据量可以采用单一的数据粒度,即直接存储细节数据并定期在细节数据基础上进行数据综合。而大数据量需要采用双重粒度,数据仓库只保留在细节数据保留周期之内的数据,对于该周期之后的信息只保留其综合信息。就超市而言,可以保存最近一个月中每天的营业额数据。对于更早时间段内的营业额数据,可以只保存周营业额之和,或者月营业额之和。典型的粒度定义包括:顾客的购物券上扫描设备一次拾取的分列项内容,仓库中每种产品库存水平的日快照,每个银行帐号的月快照。
(3)表的分割与划分。通常按照时间进行分割。细节数据时间短,而综合数据的时间稍长。分割表之后要为各个表增加合适的时间字段,同时去掉分析过程中不会用到的字段。在实际应用中,字段被访问的频率有差别。将所有的字段放在一起会影响访问的效率。所以有必要对表中的内容进行合理的划分。通常按照数据稳定性进行划分,这样就避免了整张表的记录数迅速增长的现象,节约了存储空间。
(4)数据抽取和数据加载。将数据资源从外部抽取到数据仓库中,在此过程中应该依据元数据中定义的标准数据格式处理数据。在数据被抽取后,对准备进行加载的数据进行清理,然后就可以把它们加载到数据仓库中。
(5)OLAP模型设计。OLAP是针对某个特定的主题进行的联机数据访问、处理和分析,通过直观的方式从多个维度、多种数据综合程度将系统的运营情况展现给使用者。OLAP模型设计包括维表设计和事实表设计。维表通过记录因素的属性描述事件中包含的诸多因素,例如,员工维表中通过员工标识号、姓名、电话、年龄、地址等信息用来刻画员工的属性。维表属性有星型模型和雪花型模型二种类型。通常,星型模型用来处理一对一和一对多关系,雪花型模型用来处理多对多关系。雪花型模型用中间表连接事实表和维表,使事实表不至于迅速膨胀。在设计事实表时要着重考虑数据的粒度。如果决策者不断向下观察细节数据,则事实表会记录很多的细节,其长度会增大。反之其长度会减小。图2为销售主题的星型模型和雪花模型。
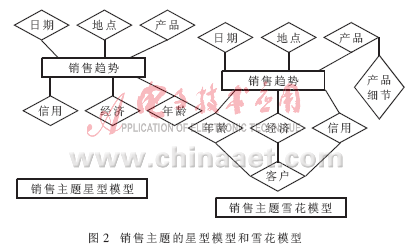
(6)数据挖掘模型设计。在进行数据挖掘的时候,将数据宽表划分成训练集合和验证集合。在没有挖掘模型时可以使用训练集合对数据进行训练,逐渐确定模型中的参数。在模型建立后,利用验证集合对模型进行评价。
在模型确定后,需要将进行预测的数据输入挖掘引擎,挖掘引擎将利用模型得到预测结果。数据挖掘的部分预测结果输入到OLAP子系统中,另一些结果输入界面子系统,以便将数据挖掘的结果呈现给最终用户。
(7)同客户交流。以上工作完成以后,需要同用户进行深入的交流,使用户对以上系统有更加深入的认识,获取用户的想法,以便于下一步工作的开展。
(8)重新开始循环。重新进入以上循环,直到取得满意的结果。
3 结束语
大型超市每天都要进行成千上万笔交易。对这些交易进行分析,找出它们之间的关联关系,有利于超市管理层进行正确决策,及时调整经营策略,更好地适应市场的挑战。
参考文献
1 Agosta L著,潇湘工作室译.数据仓库技术指南.北京:人民 邮电出版社,2000
2 谢榕.基于数据仓库的决策支持系统框架.系统工程理论与实践,2000;(4)
3 高洪深.决策支持系统(DSS).北京:清华大学出版社,2000
4 林宇.数据仓库原理与实践.北京:人民邮电出版社,2003
5 Han J,Kamber M著,范明,孟小峰译.数据挖掘:概念与技术.北京:机械工业出版社,2001