
摘 要: 对Jean推理机的结构及推理规则的构造语法进行系统介绍,通过实例说明Jena在基于本体的信息检索中的应用。
关键词: 本体 Jena OWL RDF
随着因特网技术迅速发展,网上信息与知识急剧增长。所以,对信息检索技术的研究日显重要,信息检索已成为信息社会中不可或缺的一种重要工具。
当前的信息检索技术可分为三类:全文检索(Text Retrieval)、数据检索(Data Retrieval)和知识检索(Knowledge Retrieval)。全文检索和数据检索的本质都是直接基于关键字的检索技术,不能满足用户在语义和知识上的需求。知识检索强调的是基于知识的、语义上的匹配,因此在查全率和查准率上有更好的保证。
本体(Ontology)原本是一个哲学中的概念,被哲学家用来描述事物的本质。在计算机界,明确本体的定义经历了一个过程,最后Gruber关于本体的定义得到了业内同行的一致认同,即“本体是概念模型的明确的规范说明”。本体作为一种能在语义和知识层次上描述信息的概念模型建模工具,在信息检索,特别是在基于知识的信息检索中得到了广泛的应用。
OWL(Web Ontology Language)是W3C组织于2004年2月正式推出的一个专门用来描述本体的语言。它既有强大的语义表达能力,又可以实现描述逻辑的可判定推理。OWL可以用来存储本体中的概念和关系。
RDF(Resource Description Framework)是资源描述框架语言,用来描述元数据以及元数据与元数据之间的关系。其中元数据是“关于数据的数据”,是描述网络资源的数据。RDF可以用来存储本体中的实例。
1 Jena推理机简介
Jena是专门用来构建语义网的应用软件,它为RDF、RDFS和OWL提供了一个可编程实现的环境。推理功能是Jena中的一个子系统,它的目的就是把推理机制和推理器引入到Jena中。Jena推理机结构如图1所示。
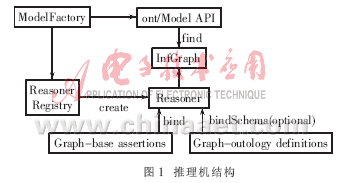
所有应用都是通过使用ModelFactory访问图1的推理机制,并为相关联的Reasoner建立一个新的Model。查询这个新的Model不但会返回对原来数据的描述信息,还会返回通过Reasoner中的规则执行后的附加描述信息。整个推理机制的核心部分是InfGraph,因为所有应用的执行都是在Graph SPI层进行。Ont/Model API为用户构建的本体提供了一种便利的方式与合适的推理器连接。推理结构中的Graph-base assertions指的是和Reasoner一起绑定的数据(XML数据-实例),而Graph-ontology definitions指的是和Reasoner一起绑定的数据结构的限制(也就是XML模式-概念和关系)。Reasoner Registry是一个静态类,它包含了当前用到的所有Reasoner。
2 Jena推理规则的构造语法
用户一方面可以利用上面的结构实现本体中的推理,另一方面,如果用户对Java很熟悉,则可以自己开发推理规则。规则的语法格式如下:
Rule := bare-rule
or [bare-rule]
or [ruleName:bare-rule]
bare-rule:= term,...term->hterm,...hterm//向前推理
or term,...term<-term,...term//向后推理
hterm := term
or [bare-rule]
term := (node,node,node)//三元组模式
or (node,node,functor)//扩展三元组模式
or builtin(node,...node)//调用处理元语
functor := functorName(node,...node)
//结构化的文字表述
node := uri-ref//例如 http://foo.com/eg
or prefix:localname//例如rdf:type
or ?varname//变量名
or ′a literal′//字符串
or number//例如42或25.5
用户根据上述语法格式写出针对特定问题的规则,就可以更加方便、快捷地查询各种信息了。
3 Jena推理机的应用
下面通过一个具体的实例讨论Jena推理机是如何在本体中进行推理的。
在现代企业管理中,人们越来越清楚地认识到知识、尤其是雇员的知识是企业非常重要的财富。如何组织、管理好这些知识财富已成为现代管理重要的研究课题。传统的做法是建立一个数据库系统对企业雇员进行管理。然而,基于关键词的查询有时是不能满足要求的。对于这个问题,文献[9]进行了研究并给出了示例。示例如下:查找一个懂得“数据库”的雇员来从事一个项目的开发工作,假设在建立的查询系统中找不到一个人懂得“数据库”,系统只能返回空记录给用户。而事实上存在某些人懂得“演绎数据库”或“面向对象数据库”,按常识,这些人应该懂得数据库的知识,他们可以作为候选人提交给用户。但传统的数据库做不到这一点。虽然可以通过进一步输入这些关键词达到查询目的,但是不能保证用户了解“数据库”所有的子领域。文献[9]借助于本体,可以实现这一目的。文中假设为企业建立了一个本体,其中一个部分如图2所示。
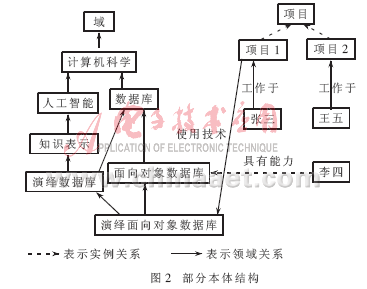
由图2可以看到,李四具有“面向对象数据库”的能力。一般认为,具有某领域的子领域能力的雇员,同样具备该领域的知识。进一步把问题推广到项目因素。现在要查询具备“演绎面向对象数据库”能力的雇员,同样没有结果。然而从图2中可以看到张三在做项目1,而项目1应用了“演绎面向对象数据库”技术。因此张三可以作为候选人输出。
文献[9]是根据本体的启发式算法实现查询功能的。启发式算法是先定义几个基本函数,然后利用函数的组合及函数之间的映射实现概念之间的联系。针对这个问题,在Jena推理机的基础上,加入自己设计的规则,只要输入限定条件,就可以输出满足该条件的雇员。由于可以根据实际环境加入相应的规则,从而使算法具有更好的灵活性和适应性。
使用Jena推理机制实现这种查询功能,必须做好两方面的工作。第一,把图2中所有与数据库相关的概念、关系和实例用OWL和RDF表示出来,存储成XML文档。这又分两个步骤:(1)把图2中本体的概念用OWL表示出来,存储成CONCEPT.owl文件。这里的概念有计算机科学(CS)、数据库(DB)、演绎数据库(DDB)、面向对象数据库(OODB)、演绎面向对象数据库(DOODB)和项目(P);(2)把图1中本体的实例用RDF存储成INSTANCE.rdf 文件。一共有两个项目,分别是项目1和项目2,有三个雇员:张三、李四和王五。其中张三工作于项目1,王五工作于项目2,李四有“面向对象数据库”的能力。第二,根据查询条件构造两条规则实现查询功能:
Rule1:(?x has competence ?y),(?y subclass of ?z)->(?x has competence ?z)
Rule2:(?x work in ?y),(?y use tech ?z)->(?x has competence ?z)
Rule1说明如果某个雇员x有能力y,而y属于z,则x拥有能力z。
Rule2说明如果某个雇员x工作于项目y,而y使用了z技术,则x拥有能力z。
把这两条规则放入Jena推理机中,然后基于上面两个相关联的XML文档进行推理。代码如下:
Model schema=
ModelLoader.loadModel(″file:data/CONCEPT.owl″);
//把本体中的概念文件CONCEPT.owl读入推理机
Model data=
ModelLoader.loadModel(″file:data/INSTANCE.rdf″);
//把本体中的实例文件INSTANCE.rdf读入推理机
String rules=
″[Rule1:(?x has competence ?y)(?y subclass of ?z)
->(?x has competence ?z)]″+″[Rule 2:(?x work in ?y)
(?y use tech ?z)->(?x has competence ?z)]″;
Reasoner reasoner=new GenericRuleReasoner
(Rule.parseRules(rules));
//把编写的规则加入到已有的推理规则中
reasoner=reasoner.bindSchema(schema);
InfModel infmodel=ModelFactory.createInfModel(reasoner,data);
Resource DB=infmodel.getResource(″urn:x-hp:eg/DB″);
System.out.println(″DB*:″);
printStatements(infmodel,null,null,DB);
//利用printStatements函数输出所有
//与数据库有关的推理结果
printStatements定义如下:
public void printStatements(Model m,
Resource s,Property p, Resource o)
{
for (StmtIterator i=
m.listStatements(s,p,o);i.hasnext( );)
{
Statement stmt=i.nextStatement( );
System.out.println(″-″ +
PrintUtil.print(stmt));
}
}
上面操作的输出结果是:
DB*:
-(eg:DOODB owl:subclassof eg:DB) //演绎面向对象数据库是数据库的子集
-(eg:DDB owl:subclassof eg:DB) //演绎数据库是数据库的子集
-(eg:OODB owl:subclassof eg:DB) //面向对象数据库是数据库的子集
-(eg:李四 eg:hascompetence eg:DB) //李四具有数据库的能力
-(eg:张三 eg:hascompetence eg:DB) //张三具有数据库的能力
-(eg:project1 eg:usetech eg:DB) //项目1使用了数据库的技术
因为RDF是用三元组表示的,所以在结果中张三、李四都以这样的形式作为候选人输出了。最后使用针对RDF格式的数据库查询技术RDQL把雇员的姓名选择出来,此工作便完成了。
4 结 论
随着科学技术的发展,信息检索技术也在发展,本体的引入提高了信息检索的效率。Jena作为一种支持本体的工具,在今后本体的研究过程中,必将会有重要的作用。
参考文献
1 邓志鸿,唐世渭,张铭等.Ontology研究综述.北京大学学报, 2002;38(5)
2 Gruber T.Ontolingua:A translation approach to portable ontology specifications.Knowledge Acquisition,1993;5(2)
3 McGuinness D L,Harmelen F V.OWL Web Ontology Language Overview.W3C Recommendation,2004,2.http:// www.w3.org/TR/owl-features
4 Manola F,Miller E.RDF Primer.W3C Recommendation, 2004,2.http://www.w3.org/TR/rdf-primer
5 Verzulli J.Using the Jena API to Process RDF.O′Reilly Xml.com,2001;(5).http://www.w3.org/TR/rdf-Primer
6 Reynolds D.Jena 2 Inference support.HP United States, 2004;(2).http://www.hpl.hp.co.uk/people/bwm/rdf/jena
7 宋炜,张铭.语义网简明教程.北京:高等教育出版社,2004
8 廖明宏.本体论与信息检索.计算机工程,2000;(2)
9 Dauiel E.Knowledge management System:Converting and Connecting.IEEE Intellsyst,1998;(5)~(6)