
基于FPGA的TCP粘合设计与实现
2008-03-31
作者:程文青,曾 鸣,黄 建
摘 要: 介绍了数据分流技术的发展状况,着重分析了TCP粘合技术目前的实现方式,并指出传统的TCP粘合的软件实现缺陷,提出一种基于FPGA技术TCP粘合的设计与实现,证明了其设计性能上的优势。
关键词: TCP粘合 URL重定向 数据分流
传统的数据分流一般基于三层、四层交换,不能在应用层解析数据,导致数据在后端服务器解析后还要相互重新分发,增加了服务器数据传输的开销。为解决该问题,可以在客户端" title="客户端">客户端与服务器之间采用应用级代理服务器,利用该服务器专门对数据包进行解析分发,但是该方式下,数据要进入TCP/IP协议栈,处理速度慢,同时代理服务器还需要与客户端、服务器双方通信,需要处理的数据量非常大,因此在集群应用中,特别是大规模负载平衡集群系统中很少使用应用级代理。
在应用级代理的基础上,为进一步提高数据处理的速度,提出了TCP粘合技术[1]。该技术在通信双方建立通信之初对双方的握手信号以及通信原语进行分析,获取必要的信息,决定数据的流向,一旦双方开始通信,该代理就不再对数据进行分析,而仅起到一个透明网关的作用,从而提高代理的系统性能。
TCP粘合技术采用软件处理方式时,由于大量数据包不需要上层解析,因此提高了系统性能,但是受软件处理速度的限制,该技术仍很难应用于大规模的集群系统。本文提出了一种基于FPGA的TCP粘合技术的高速实现机制,利用硬件的高速处理特性和流水线技术来适应高速网络传输的需要。
1 现存的TCP粘合技术
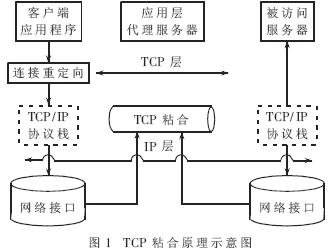
TCP粘合原理如下:(1)监听客户端的连接请求,并在客户端发出连接请求后(从SYN开始),建立客户端到均衡器之间的连接(通过TCP的三次握手协议完成)。(2)在随后的请求报文中分析数据并决定真正被访问的服务节点。(3)与服务节点建立另一个连接,将两个连接粘合在一起(Splicing)。其TCP粘合原理示意图如图1所示[2]。
2 TCP粘合技术的硬件实现
TCP粘合技术的关键在于,当客户端发起连接请求时,系统并不是立即将该请求发给后端服务器,而是伪装成服务器与客户端建立连接,取得用户的GET数据包。通过对URL的匹配来找到信息在后端服务器的位置,然后再在客户端与服务器之间建立连接通信。
2.1 系统架构
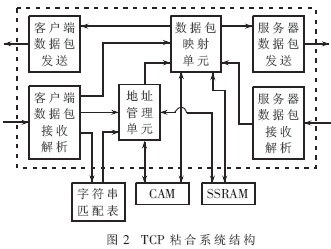
TCP粘合系统结构如图2所示。
该系统中首先由客户数据接收端对接收到的HTTP报文进行解析,发现数据包为一个发起连接的SYN数据包时,传给地址管理单元" title="管理单元">管理单元,地址管理就为该连接分配一个地址空间,同时通过映射单元告诉客户数据发送端与客户端完成三次握手,建立连接。
当客户数据接收端接收到GET数据包时,将该数据包发送给字符串匹配表,该表会将信息在后端服务器的位置返回给地址管理单元,地址管理单元将该信息送给数据包映射单元,映射单元将该信息写入相应的SSRAM空间中,同时通知服务器发送端与后端服务器建立连接。这样就完成了一个TCP的粘合过程。
在客户端与服务器的通信过程中,数据包映射单元通过双方SIP、DIP信息从SSRAM中查找出对应的替换信息,完成双方数据包的映射。
在双方通信结束时,由地址管理单元对双方使用的地址空间进行回收;同时为防止通信过程中的异常中断,地址管理单元内部还采用了定时器机制对地址空间进行监测,根据定时器返回结果回收过时地址,防止过时信息被查用。
2.2 设计实现
在该系统中,为完成TCP粘合并且保证TCP通信的可靠性,必须能够正确识别接收到的数据包类型;同时由于实际网络数据传输的延时,在一个客户端通信过程中可能会插入很多其他客户端发起的新的连接请求,系统内部根据对CAM查找返回的地址来区分不同的数据流,因此要对内部地址空间进行有效的释放回收,为处理网络通信异常中断而导致内部地址无法回收而引入定时器机制;在数据发送部分,客户端数据发送模块伪装成服务器与客户端完成TCP三次握手协议;服务器数据发送模块则伪装成客户端与服务器完成TCP三次握手协议。双方在通信过程中转发对方的数据包。
2.2.1 数据收发
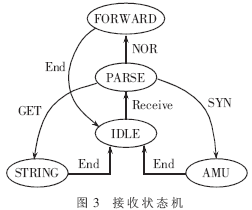
对于系统的发送接口来说,所有发送数据包的转发由数据包映射单元完成,因此发送接口仅完成简单的数据包转发功能。而当系统接收到数据包时,要对数据包进行协议解析,从而决定数据包后端处理的方式。在接收部分主要对三种数据包进行区分:(1)双方发起连接的SYN数据包。这表示一个新连接的发起,因此交给地址管理单元,为它分配一个新的地址空间,同时要求发送端返回一个ACK数据包;(2)客户端发来的GET数据包中含有客户端所需信息的URL地址,将该数据包送给字符串匹配表以获得该信息所在后端服务器的位置;(3)双方通信的普通数据包。该数据包交给数据包映射单元实现双发的通信。具体接收的状态转换图如图3所示。
2.2.2 地址管理单元
在地址管理的方式上,在此处利用一个地址链表进行管理,如图4所示。

每次地址管理单元接收到新的请求连接就从链表的头部取出该可用地址空间,将新请求的SIP、DIP信息写入该地址的CAM中,同时在该地址对应的SSRAM的页面中写入相关的信息,假设链表中取出地址为n,页面大小为m,则SSRAM中对应的页面起始地址l为:
l=n×m
当地址管理单元接收到字符串匹配表返回的后端服务器位置信息时,首先通过该数据包的SIP、DIP从CAM中查找该数据流对应的地址,通过上述计算公式找出SSRAM中对应的页面,写入返回信息。
对于地址空间的回收,为防止通信异常中断而无法回收地址,在系统中采用定时器机制,即在一段时间后对SSRAM中的定时器标志位进行检测,一旦发现该标志位过时则通知地址管理单元回收地址。地址管理单元收到某一地址过时的信息后,将该地址挂在地址管理链表尾部,同时清除该地址CAM中的SIP、DIP信息。这样当同一IP发起新的连接时就不会查找到过时信息。
2.2.3 数据包映射单元
为完成数据包的映射,该部分需要实现两个功能:ACK序列号转换和双方转换信息的存储。
在TCP粘合过程中,由于TCP粘合系统送给客户端的ACK序列号和后端服务器送给客户端的ACK序列号不相同,因此要进行ACK序列号的转换,同时要重新计算数据包的TCP/IP校验和。
现假设客户端发送了请求连接的SYN数据包,而客户端返回给客户端的SYN序列号为地址管理单元分配给该连接的地址A0,而当系统和服务器建立链接时服务器端返回的SYN序列号为A1,则根据这两个序列号可计算差值A为:A=A0-A1。
以后通信的过程中,只要将服务器发送给系统的序列号加上A就能够转换成为系统送给客户端的序列号,这样就完成了服务器端向客户端发送数据的转换,反之就可以完成客户端向服务器发送数据的转换。
对于数据包的校验和转换而言,由于校验和本质上是加法运算,所以只需要在原来的校验和基础上加上序列号之差(或减去一个差值)即可完成校验和的转换。
在同一个通信过程中,ACK序列号转换、校验和的转换、发起连接的SYN、GET数据包和定时器标志位等信息都需要存储,由于每个数据流需要存储的内容较多,单一的地址已经无法满足存储要求。此处存储管理采用页面式的管理方式。将整个存储空间分为若干页面,每个数据流信息存入一个页面中。SSRAM的存储格式如图5所示。

3 性能分析
该架构已在试验系统上实现,接收端为两个GE口。相对于采用TCP粘合的应用代理服务器来说(其中代理服务器CPU Pentium IV 2GHz),具体的性能对比如表1所示。
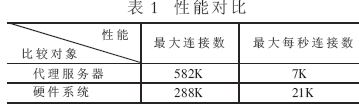
从上表可以看出在最大" title="最大">最大连接数" title="连接数">连接数方面,在本系统中采用一个18Mbit的CAM,它能够提供的最大地址空间为288K×144bit,只能支持288K的连接数。对于服务器的最大连接数来说,SYN和GET数据包需要经过软件协议解析。因此当最大连接数达到582K时CPU的利用率将达到90%以上[3],无法再处理新的连接。从上述分析中可以看出,由于受硬件资源的限制,硬件系统" title="硬件系统">硬件系统可以支持的最大连接数小于代理服务器。但是在实际的网络传输过程中,一个HTTP连接持续的时间一般为几百个毫秒,在硬件系统达到每秒21K的连接数时,能够承受的一个HTTP最大持续时间为13秒,远远大于实际HTTP连接的持续时间,因此硬件系统支持的最大连接数是够用的。当代理服务器采用千兆网卡来接收数据时,由于数据需要经过上层协议解析,因此实际能够接收的数据量只能够达到300Mbps。假设每次平均请求512B,则代理服务器能够支持的最大每秒连接数大约为7K;而当硬件系统工作在133MHz,内部采用32bit总线传输时,整个系统的带宽达到4Gbit,同时系统内部采用流水线方式,能够线速处理1Gbps数据的接收,假设平均每次请求512B,则硬件系统能够处理的每秒最大连接数达到21K,因此在单位时间内能够处理的连接数量会高于代理服务器。
随着HTTP访问量的不断增大,对于访问数据包的分流粒度要求越来越细。本文提出的基于硬件实现的TCP粘合系统,在TCP粘合技术的基础上,利用硬件的高速处理特性,可以达到2个GE口收发(2Gbps)的线速处理性能。同时能够较好地基于内容来区分数据流,从而避免了后端服务器数据的重新分发。
参考文献
1 Cohen A,Rangarajan S,Slye H.On the performance of TCP splicing for URL-aware redirection.In:USENIX symposium on Internet technologies and systems,1999
2 Rosu M,Ros D.An evaluation of TCP splice benefits in web proxy servers.In:International world wide web conference,2002
3 Jacobson V.A high-Performance TCP/IP implementation gigabit per second TCP workshop.Corporation for National Research Initiatives(CNRI),1993
4 谢希仁.计算机网络.北京:电子工业出版社,2003