
摘 要: 介绍了一种基于PCI总线和多片并行FPGA的高速计算平台。FPGA+PCI板卡利用普通PC机作为CPU,通过PCI总线互联,实现了一个并行高速的通用数字运算平台。利用VHDL语言编写各种算法,可用于加解密算法实现和高速数字信号处理等领域,而速度相当于数台PC机并行运算。
关键词: 并行计算 现场可编程门阵列 MD5
当前对于各种加密算法,除了有针对性的破解算法,最基本的思想就是穷举密钥进行匹配,通常称为暴力破解算法。由于暴力破解算法包含密钥个数较多,遍历的时间超过实际可接受的范围。如果计算速度提高到足够快,这种遍历的算法因结构设计简便而具有实际应用的前景。
PCI 总线(外设互联总线)与传统的总线标准——ISA总线(工业标准结构总线)相比, 具有更高的传输率(132MBps)、支持32位处理器及DMA和即插即用等优点,用于取代ISA总线而成为目前台式计算机的事实I/O总线标准,在普通PC机和工控机上有着广泛的应用。PCI总线为满足在插卡和系统存储器中高速传输数据的要求提供了很好的途径。
PCI总线是一种独立于处理器的局部总线,因此通过PCI总线插入扩展板,利用并提升普通PC机和工控机对大规模数字信号处理的运算能力和速度是一项非常具有实用意义的工作。
随着数字技术日益广泛的应用,以现场可编程门阵列(FPGA)为代表的ASIC器件得到了迅速普及和发展,器件集成度和速度都在高速增长。FPGA既具有门阵列的高逻辑密度和高可靠性,又具有可编程逻辑器件的用户可编程特性,可以减少系统设计和维护的风险,降低产品成本,缩短设计周期。FPGA与通用CPU相比又具有如下显著优点:
(1) FPGA一般均带有多个加法器和移位器,特别适合多步骤算法中相同运算的并行处理。通用CPU只能提供有限的多级流水线作业。
(2) 一块FPGA中可以集成数个算法并行运算。通用CPU一般只能对一个算法串行处理。
(3) 基于FPGA设计的板卡功耗小、体积小、成本低,特别适合板卡间的并联。
本文介绍的基于PCI总线的FPGA计算平台的系统实现:通过在PC机上插入扩展PCI卡,对算法进行针对并行运算的设计,提升普通PC机对大计算量数字信号的处理速度。本设计采用5片FPGA 芯片及相关周边芯片设计实现这一并行高速计算平台,并在该平台上完成了DES和MD5等算法的加密和解密。文中通过基于MD5算法设计的加密方案(仿Yahoo邮箱的密码校验)进行暴力破解,验证了本系统的可行性以及速度快、性价比高等显著优点。
1 系统结构
系统利用普通PC机或工控机进行控制、数据流下载和结果采集,大计算量的数字运算利用IP-CORE技术并行地在FPGA中进行。将数字信号处理的算法设计为一个单元模块,并根据芯片的结构对布局和布线进行优化,该单元模块重复利用的技术被称为IP-CORE技术。在本系统中利用IP-CORE的可重复利用性,通过仲裁逻辑调度数据的分配,从而实现算法的并行处理。
1.1 硬件结构
系统中采用5片ALTERA公司的STRATIX EP1S10 FPGA 芯片,其中4片作为数字信号处理算法CORE的载体(文中称为算法FPGA);1片作为连接PC机与运算CORE的桥接芯片、加载程序、并行总线裁决和中断判决等仲裁逻辑的载体。与PCI总线的接口使用PLX公司的 PCI9054芯片。系统硬件结构如图1所示。

1.2 逻辑结构
BRIDGE FPGA的程序采用自顶向下的设计方法,其逻辑结构如图2所示,按功能可分为以下部分:顶层模块 PCI_FPGA_PARALLEL;与PCI9054的接口模块PCI接口;数据缓存及仲裁部分:数据缓存模块 FIFO、寄存器模块 regpart、数据回传模块deserial、内部总线仲裁和流控模块 CORE接口等。

PCI接口部分实现与PCI9054 芯片的接口时序,使得复用的地址和数据分开,产生地址空间的选取及使能信号,便于后端处理。
仲裁逻辑部分:
(1)实现对地址空间内数据缓冲区、各种寄存器的读写,以及根据配置寄存器的内容对算法CORE和桥FPGA做相应的操作(配置、启动、停止、复位等)。
(2)利用缓冲区及FIFO的队列长度信号wrusedw、rdusedw、
full和empty进行数据流控制。数据由PC机下载时首先进入缓冲区,每一块算法CORE均对应一个数据下行FIFO,由FIFO当前状态来判定是否从缓冲区中取数。具体逻辑模型如图3所示。
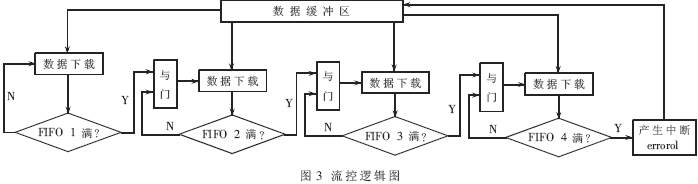
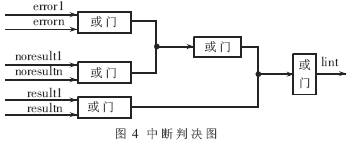
(3)返回结果引入本地中断机制,当有正确结果产生、或无正确结果但密钥匹配完成、或系统异常状态,均产生中断信号并填写中断类型寄存器,经级联后产生向PC机的中断。中断判决如图4所示。
(4)实现与算法core间的协议逻辑,控制多种数据流的下行以及结果的返回。
2 MD5算法简介
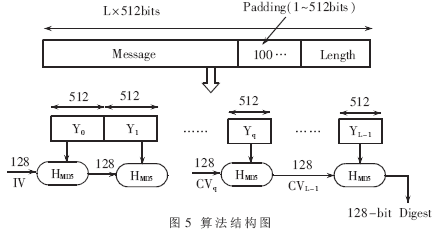
MD5(Message Digest 5)报文摘要算法是一种应用广泛的提取数字指纹的算法标准,它由MIT的密码学专家、RSA算法的发明人之一Rivest设计发明。MD5算法结构如图5所示。
对任意长度的信息输入,MD5都将产生一个长度为128bit的输出,这一输出可以被看作是原输入报文的“报文摘要值(Message Digest)”。
MD5的特点:
(1)两条不同的报文具有相同的报文摘要值的可能 性极小。
(2)对于预先给定的报文摘要值,要想寻找到一条报文,使得其报文摘要值与某个给定的报文摘要值相等,在计算上是不可能的。
(3)根据报文的摘要值,要
想推测出原来的报文是极端困难的。
MD5算法被广泛地应用于网络数据完整性检查以及各种数据加密技术中。Yahoo邮箱密码算法是基于两次MD5算法。共算法步骤如下:
step1: 对一个密码字段(例如:'dfertgrhyt'),用MD5算法加密:h=md5('dfertgrhyt')。
step2: 将step1所得结果转换为32Bytes的hex值:hex(h)。
step3: 将step2所得结果与一个yahoo提供的chanllenge值简单级联:string=hex(h)+chanllenge
step4:将step3所得结果再进行一次MD5运算:hash=md5(string)。
由于未得到实际Yahoo邮箱密码生成参数(例如challenge码),本文构造了相近算法以测试本系统性能。测试方案如下:
提供一个已知的challenge值与相应的Hash值,从提供的字典中提取合适密码,由生成算法计算出对应的Hash值与提供的Hash值匹配来校验匹配的密码。密钥字典的产生有两种方式:人为构造字典及系统自加、穷举产生密钥。
3 实测性能分析
实际系统中算法CORE运算时钟为20MHz,64bit数据宽度输入;采用多级流水线设计及运算速度就是系统运行时钟的速度。除运算初期流水线建立过程和运算结束时流水线完成过程,运算速度均可视为20MHz;实际制成的系统为四片算法FPGA并行运算,实际吞吐量为4×20M×16bit=1.28Gb;经Altera Quartus 4.1 综合,实际仲裁逻辑占用3 725个逻辑单元。综合频率最高为156.2MHz,单算法逻辑占用7 718个逻辑单元,综合频率最高为37.10MHz。
典型的普通PC机定点运算需要多个指令周期,包括取指令、取数据、计算、保存数据等指令周期,而一个x86指令周期又由多个CPU时钟周期组成,大大降低了实际运算速度。由于单个CORE以20MHz时钟流水线运算,相当于一台普通PC机的运算速度,因此多个CORE并行运算即可达到多台PC机并行运算的效率。
采取密钥字典自FPGA穷举产生方式,可发挥算法CORE的最大效能。若采取密钥字典自PC机下载方式,则实际速率由PCI总线最高速率决定。但由于字典可以人为选取,大大降低了密钥选取的盲目性。本系统接入普通PC机上32bit、32MHz的PCI总线,单算法CORE连续运算(64bit×20MHz)即可满足PCI总线全速下载。若使用64bit、66MHz的PCI总线或 PCI EXPRESS,将进一步提高系统的实际吞吐量。
本文提出了一种基于FPGA的适合大规模数字信号处理的并行处理结构,利用CORE的可置换性,可以针对不同应用的数字运算设计不同的CORE,系统通用性的特点非常显著。一台普通PC机中可以同时插入数块PCI卡,每块卡上的任意一块算法FPGA都可提供相当或超过一台普通PC机的运算速度。而每增加一块算法FPGA,在效率提高一倍的前提下,功耗增加不超过10W,而体积几乎不变,成本也只是比普通PC机增加了五分之一。因此,本文提出的并行结构具有极高的性价比。
如果将PCI总线接口模块集成到FPGA中以取代PCI9054芯片,将进一步降低硬件成本,减少硬件设计的复杂度;因实际运算速度与算法的并行度和优化有密切的关系,因此,设计不同应用的CORE以及相关算法的优化是下一步要进行的重要工作。
参考文献
1 Rivest R L. The MD5 message-digest algorithm. RFC 1321,MIT Laboratory for Computer Science and RSA Data Security,Inc.,April 1992
2 Jarvinen K, Tommiska M, Skytta J. Hardware implementation analysis of the MD5 hash algorithm. System Sciences, 2005. HICSS ′05. Proceedings of the 38th Annual Hawaii International Conference on 03-06 Jan. 2005:298
3 Shanley T. Anderson D. PCI系统结构.北京:电子工业出版社, 2000
4 侯伯亨,顾 新. VHDL硬件描述语言与数字逻辑电路设计.西安:西安电子科技大学出版社, 1999