
象棋机器人视觉系统设计
2008-07-15
作者:杜俊俐1,2 , 黄心汉1
摘 要: 视觉是象棋机器人软件的重要组成部分,其核心工作是棋盘图像二值化" title="二值化">二值化、棋子检测和棋子识别。并对棋盘全局二值化存在的问题,提出了基于相邻像素灰度差阈值的棋盘图像二值化方法" title="二值化方法">二值化方法;针对棋子文字方向任意的现象,提出了基于年轮统计的棋子文字识别方法。实践证明,该方法处理速度快、识别效果理想。
关键词: 棋盘识别 图像处理 灰度差阈值 年轮统计
中国象棋变化多端,趣味无穷,是流传了一千多年的优秀游戏,是中华文化的精粹之一。随着机器人技术的发展,机器人的功能越来越丰富,娱乐机器人的研究已经成为一个重要的方向。象棋机器人是娱乐机器人的一种,在CCD摄像机的监视下,使人机下棋过程非常类似于人与人之间的对弈,更具有人性化和亲切感。本文介绍的系统是象棋机器人的视觉部分,能识别出当前棋盘的状态,提供给机器人下棋软件进行进一步推理。
象棋棋盘识别中的关键问题是对捕捉的棋盘图像的二值化、棋子检测和棋子文字的识别。考虑光源变化和不良环境的影响,将图像做全局单阈值二值化无法有效地将棋盘背景和网格线" title="网格线">网格线及棋子分开;棋子检测是相对耗时的工作,棋子定位的准确性将直接影响后续识别的正确性;棋子文字识别的主要问题是文字方向的任意性。考虑到下棋软件搜索和推理比较费时(尤其是在较高级别时),为使系统具有较短的响应时间,该视觉部分应尽可能快,故很多计算量大的处理方法在此不太适用。本文针对这些问题,以处理有效和计算简单为目标,提出了基于像素差阈值的棋盘图像二值化" title="图像二值化">图像二值化方法、棋子的两趟检测法和基于年轮统计的棋子文字识别方法。
1 象棋机器人视觉系统整体设计
1.1棋盘设计与表示
棋盘的设计如图1(a)所示,棋盘由对弈棋盘和辅助棋位组成。相机位于棋盘正上方,且保持固定状态,静止拍摄。辅助棋位是位于棋盘的两侧用于放置吃掉的棋子。棋子正反两面带有凹槽外框及标识点,根据红、绿方棋子,槽内底色也分别为红、绿两种颜色;正反两面的字符也分为红、绿两色,黑棋上的字符为将、象、士、车、马、炮、卒,红棋上的字符为帅、相、仕、车、马、炮、兵。棋盘和棋子的底色为灰白,网格线为黑色。
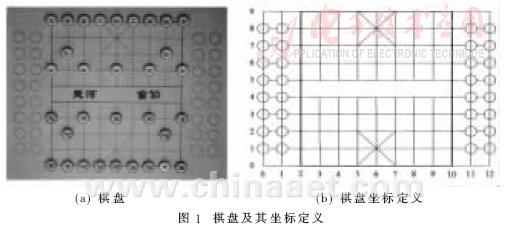
为表示棋子的位置,定义一个棋盘坐标系如图1(b)所示。用两维数组A(i,j)表示棋盘上各棋位的状态,其中,(i,j)为棋位的竖轴、横轴坐标。棋位的状态用一组代码表示,用“0”表示无棋子,一组大写字母表示红方棋子,一组小写字母表示绿方棋子,具体为“R”表示红车;“H”表示红马;“E”表示红相;“A”表示红仕;“K”表示红帅;“C”表示红炮;“P”表示红兵。“r”表示绿车;“h”表示绿马;“e”表示绿象;“a”表示绿士;“k”表示绿将;“c”表示绿炮;“p”表示绿卒。
1.2 象棋棋盘识别程序出口参数
程序被调用一次,将捕捉当前棋盘图像并对其进行预处理、二值化、棋盘状态检测、棋子文字识别等工作。程序处理结果为棋盘状态数组A(i,j)(i=0…9, j=0…12)和异常数组B(i)(i=0,1,…,6)(A(i,j)的定义如2.1中所述)。约定B(0)、B(1)、B(2)、B(3)、B(4)、B(5)、B(6)的值为0或1,分别表示图像模糊不清、有手臂遮挡棋盘、有异物、仅缺失一个棋子、棋子缺失两个或两个以上、棋子多余、棋子过于偏离位置这七种异常情况的无或有,供后续的控制程序和博弈程序判断使用。
1.3 象棋棋盘识别程序处理流程
程序的处理过程为先捕捉棋盘灰度图像并进行二值化,在此基础上进行棋盘检测并对分割出的棋子进行识别,同时应考虑光线、遮盖、异物、棋子偏离等异常情况。具体处理流程如图2所示。其中,对棋盘图像的二值化、棋子检测和棋子文字的识别是关键,下面分别介绍其中所存在的主要问题及所采取的解决方法。

2 基于像素差阈值的棋盘图像二值化
棋盘图像二值化的目的是将棋盘背景与棋子及网格线分离,以便进行棋子等的检测和识别。目前图像二值化方法很多,可划分为:全局阈值法" title="阈值法">阈值法、局部阈值法、动态阈值法[1-2]。全局阈值法实现简单、速度快,对于具有明显双峰直方图的图像效果明显,但对于光照不均匀的图像效果不佳,抗噪能力差。局部阈值法能处理较为复杂的情况,但往往忽略了图像的边缘特征,容易出现伪影现象,且窗口较大时,算法的速度将受到很大影响。动态阈值法充分考虑了像素的邻域特征,能够根据图像的不同背景情况自适应地改变阈值,可较精确地提取出二值图像,但它过渡地夸大了像元的邻域灰度的变化,会把不均匀灰度分布的背景分割到目标中去,带来许多不应出现的假目标。
在象棋机器人系统中装有照明灯,为图像捕捉提供光源。即使这样,由于光照不均匀有时所捕捉的图像仍存在一定的阴影、反光现象,致使图像灰度层次较多。灰度图像如图3(a)所示。若采用全局阈值法的二值化图像,结果出现某些背景变黑而一些棋子模糊和网格线断线的现象,如图3(b)所示。这直接影响了后续的棋子和异物检测。

分析灰度棋盘图像特征,发现虽然背景灰度不均匀,但图像清晰,网格线和棋子与邻域背景灰度反差较大,而背景灰度在邻域内变化缓慢。为此,综合全局阈值法的速度优势、局部阈值法和动态阈值法的邻域特征,提出一种基于邻像素差阈值的二值化方法。
2.1 基于邻像素差阈值的棋盘图像二值化算法思想
基于邻像素差阈值的棋盘图像二值化算法是将常规灰度阈值的像素灰度判断改为对邻像素差阈值进行相邻像素差的判断来分割图像。
邻像素差是指水平或垂直方向上的相邻两像素灰度的差。邻像素差阈值是指对整幅图像进行邻像素差的统计,利用灰度阈值自动求取方法求取邻像素差阈值。针对象棋棋盘图像,进行逐行或逐列扫描图像,求出水平或垂直相邻像素灰度差直方图。实验发现,该灰度差直方图呈现明显的双峰特征,故选择峰谷点作为阈值。
基于邻像素差阈值的棋盘图像二值化算法就是用邻像素差阈值二值化图像,即逐行或逐列扫描棋盘图像,若判相邻像素差小于阈值,则当前点的二值化值与前一个像素的二值化值相同,否则不同。
设灰度棋盘图像为A,二值棋盘图像为BW,邻像素差阈值为T,则水平方向的邻像素差阈值的二值化方法为:

垂直方向的邻像素差阈值的二值化的表达为:
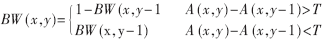
2.2 基于相邻像素灰度差的棋盘二值化算法描述
(1) 准备一个存放二值化图像的矩阵BW,并将第一个元素BW[1,1]的值赋为1(已知是白色背景),它是处理的起点。
(2) For i=1 to m //逐行扫描图像,m为棋盘图像行数
{
For j=1 to n //逐列扫描像素行,n为棋盘
图像列数
If P(i,j)-P(i,j-1)
//它是下一行二值化的起点
}
以上为基于水平像素差阈值的二值化算法。若基于垂直像素差阈值,则二值化算法中将行列扫描顺序调整即可。
3 棋子及异常检测
在二值化图像上进行棋子和异物的检测,以便进行下一步的识别或异常报警。检测采用两趟检测法。
第一趟:正常棋位棋子检测
沿网格线逐线水平扫描,在棋位处进行十字网格线的检测,若有十字网格线则该棋位为空,否则通过一个模板圆进行匹配确认是否为棋子。将匹配成功的棋子分割下来传给识别函数,并以1值(白色)填充棋位。
模板圆匹配方法:模板圆圆心在以十字点为中心以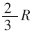 为边长的正方形内进行试探,若圆周匹配率达95%则认为匹配成功。
为边长的正方形内进行试探,若圆周匹配率达95%则认为匹配成功。
若采用逐行逐列顺序匹配,一个1028×1024的盘棋的检测时间约为2秒。在正常情况下,由于棋盘棋位和棋子吸铁石的相互作用,棋子的位置偏离很少。为提高匹配速度,以十字交叉点为起点以螺旋线为移动路径进行匹配,实测检测速度提高约20倍。
第二趟:异物和棋子超偏等异常检测
以网格为单位进行棋盘扫描,进行网格内的异物和棋子超偏等异常检测。具体步骤如下:
(1)对当前网格内黑像素数进行统计,若统计值为0,则当前网格区中无物体,判下一个网格区;否则进入第2步。
(2)求当前网格区的水平投影和垂直投影,若水平或垂直投影宽度大于棋子直径,则为异物退出,否则进入第3步。
(3)投影拼接:当前网格区中物体小于棋子则判物体水平邻接关系,宽度大于棋子为异物退出;否则判物体垂直邻接关系。若高度大于棋子,为异物退出;否则进行棋子检测,是棋子置B(5),不是棋子则置B(1)。
(4)当前网格区中有物体且无物体邻接关系同时投影宽度接近棋子大小,则进行棋子检测,若是棋子,则为棋子超偏置B(5),否则棋子置B(1)。
4 基于年轮统计的棋子文字识别方法
如图4(a)所示的以棋子的圆形凹槽外框为特征,从上面二值化图像中通过模板圆匹配法很容易检测并分割出棋子,然后对棋子文字进行识别。由于棋子放置方向的随意性,识别的关键问题是文字的方向。
基于统计决策论的统计特征可以丢失方向信息,是适合识别棋子的方法。统计决策论其要点是提取待识别模式的一组统计特征, 然后按照一定准则所确定的决策函数进行分类判决。汉字的统计模式识别是将字符点阵看作一个整体, 从该整体上经过大量统计得到所用特征, 用尽可能少的特征模式来描述尽可能多的信息。所采用的方法有: 特征统计方法、整体变换分析法、几何矩特征、笔划密度特征、字符投影特征、外围特征、微结构特征和特征点特征等。在这里,因文字方向任意,这些方法都不适用。由于棋子字符共有将、象、士、车、马、炮、卒、帅、相、仕、车、马、炮、兵14个,且系统要求视觉处理速度要快,所以不能采用计算量大的方法,故需要寻找针对这14个字的简单、快速、有效的识别方法。受参考文献[3]中过线数特征的启发,本文提出一种基于统计特征的、与方向无关的、简单快速的象棋棋子识别方法——年轮统计法。
4.1 有关定义
所谓年轮,是指以字符中心为圆心,以小于棋子半径的若干整数为半径所做的一组同心圆,因其形状而命名。如图4(b)所示。

过轮数定义为每个年轮穿越字符的次数,即每条年轮穿过黑像素区域的次数即为该年轮上的过轮数。
年轮统计法是根据过轮数特征构造编码器对文字进行识别。该方法结合了一定的棋子文字结构且与方向无关。
4.2 过轮数的计算方法
过轮数的计算方法是:若圆心坐标为(x,y),半径为r,则从(x,y+r)开始逆时针沿年轮线走一圈,像素值从白到黑变化一次则累计一次数。
4.3 年轮像素位置的确定
计算过轮数的关键问题是确定年轮线上的像素位置。为减少统计时间,根据圆的八路对称性,只需计算(x,y+r)-(x+r/sqr(2.0),y+r/sqr(2.0))这1/8圆即可。在此可应用著名的Bresenham画圆算法[4]来确定年轮上的像素。
Bresenham画圆算法的基本思想是,在算法的每一步都选择距离圆周最近的点。设Pi(xi, yi)是已经选取的一个像素点,根据该段圆的特点,可以判定下一个像素将从Hi(xi+1, yi)和Di(xi+1, yi+1)两点中选取。
判据d的初始值为:d0=3-2R
如果di<0,应选择Hi,则下一点(xi+1,yi)的判别式是: di+1=di+4xi+6
若di>0,应选择Di,则下一点(xi+1,yi+1)的判别式是: di+1=di+4(xi-yi)+10
4.4 编码器的构造
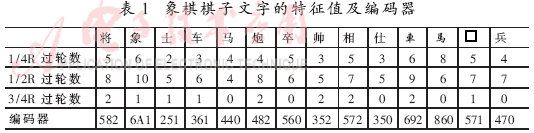
若将棋子圆形外框半径记为r,则对半径从0~r 的每条年轮的过轮数进行计算,构成一个字符串。然后对字符串进行分析和筛减,以寻求一个能区分各文字的最短字符串,并将其作为编码器进行棋子文字的识别。
筛减方法:若某过轮数删除后每个文字的过轮数串均不相同即不出现重码,则将该过轮数删除;否则,将该过轮数保留。
针对本系统中的棋子,筛减的结果是(1/4)R、(1/2)R、(3/4)R三条年轮的过轮数,任意删除一个即出现重码,则将这三个过轮数进行组合作为棋子文字的识别码。表1给出了象棋棋子文字的特征值及编码器。
本软件是郑州市科技馆象棋机器人系统的视觉部分,其中所采用的基于邻像素差阈值的棋盘图像二值化方法计算量小、二值化效果好,能使用较宽的光线条件。但它要求边缘灰度有突变的使用前提,否则会造成累计误差。基于年轮统计的棋子文字识别方法具有方向无关性,能很好地适应棋子方向随意的情况。为提高处理速度,可先做相邻灰度图像的差分,在二值差分图上检测变化位置,在当前二值图上只对变化部分进行处理,可大大缩短处理时间。在具体应用中由于棋子文字的字体不同,以上方法的具体特征值可能不能直接拿来使用,但方法的思想是可借鉴的。
参考文献
[1] OTSU N. A threshold selection method from gray-level histograms[J]. IEEE Transactions on Systems,1979,9(1):62-66.
[2] 赵雪松,陈淑珍.综合全局二值化与边缘检测的图像分割方法[J].计算机辅助设计与图形学学报,2001,13(2): 118-121.
[3] 严国莉,黄山,李岱漳,等.印刷体数字快速识别算法在身份证编码数字识别中的应用[J]. 计算机工程, 2003,(1):178-179.
[4] 张曦煌,杜俊俐.计算机图形学[M].北京:北京邮电大学出版社,2006.