
模式识别方法在入侵检测中的应用
2008-07-17
作者:姜 楠
摘 要: 将模式识别方法应用到入侵检测" title="入侵检测">入侵检测领域,用以区分正常和异常的用户或主机行为。采用KDD99作为实验数据集,通过计算信息增益,从原始数据中选取对分类结果影响较大的特征属性;再分别选取两种带监督的模式识别方法支持向量机" title="支持向量机">支持向量机(SVM)和多层神经网络(MNN)以及两种不带监督的聚类" title="聚类">聚类方法Single-Linkage和 K-Means进行实验。实验结果表明,上述方法在入侵检测领域中具有很好的应用前景。
关键词: 模式识别 入侵检测 支持向量机 聚类
入侵监测系统在信息安全领域具有重要的应用价值。入侵检测系统需要以较高的检测率和较低的误报率区分正常和异常的用户或主机行为。从某种意义上讲,入侵检测问题可以看作是一个分类问题,因此笔者将模式识别中的分类和聚类方法应用到入侵检测领域。并且在应用中基于以下三个直观假设: (1)正常和异常行为具有较大差异;(2)属于同一种类型的异常行为有较大的相似性; (3)某种特定的异常行为在不同的环境中可能通过修改参数而产生很大变化。同时选取模式识别中两种带监督的分类方法:支持向量机(SVM)和多层神经网络(MNN),训练它们识别正常行为和异常行为以及识别每种不同的异常行为。由于在实际的应用中,通常没有标识好的训练数据,不能直接使用带监督的方法,因此选取两种不带监督的聚类方法:Single-Linkage和K-Means[1],作为带监督方法的有效补充。
1 实验数据
本文采用MIT Lincoln实验室在仿真环境下获取的KDD99[2]数据集,记录9个星期内的原始网络数据包,并转化为大约7百万条记录。每条记录包含42个字段,其中第1到第41字段为特征属性。特征属性描述网络会话(session)信息,包括:连接时间、端口、源地址、目的地址等。第42字段为标记字段。每条记录都被标记为正常或者是以下四种特定类型的异常行为之一:(1)DoS——拒绝服务攻击;(2)R2L——非授权远程访问;(3)U2R——非授权使用本地超级用户特权;(4)probing——扫描攻击。
在实验中,加入了两种新的标记取代原始标记。(1)二元标记(L2):如果一条记录是异常行为,标记为1;如果一条记录是正常行为,标记为-1。(2)异常行为类型标记(L5):根据异常行为类型标记数据集(正常:-1,probeing:1,DoS:2,U2R:3,R2L:4)。
2 特征属性的选取
由于记录中有些特征属性与分类结果无关,在分类过程中采用这些特征属性将增加时间复杂度,同时很可能降低检测率。因此,为获得更高效的分类和聚类,利用信息增益的方法,选取对分类结果影响较大的特征属性。具体方法如下:
(1) 计算具有N个不同值的标记字段X的熵:
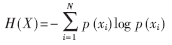
(2) 计算标记字段X对每个特征属性Yj的条件熵:
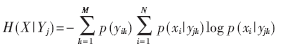
(3) 计算X对每个Yj的信息增益:
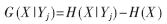
较大的G(X|Yj)值,表示Yj对分类的贡献较大。实验中采取保守估计,设定信息增益的阈值为0.2,即选取信息增益大于0.2的特征属性用于实验。最终,针对L2标记,共选取了10个特征属性;而针对L5标记,选取了12个特征属性。
3 带监督的方法
在所有带监督的模式识别方法中,选取具有广泛应用的支持向量机和多层神经网络方法,训练它们识别正常行为和异常行为以及识别不同类型的异常行为。
3.1 支持向量机(SVM)
作为较优秀的线性分类器" title="分类器">分类器之一,支持向量机的重要特性是分类器只与支持向量的数目相关,这些支持向量有助于分析和了解最有效划分的不同类别的特征属性的值。与此同时,支持向量机还支持核函数(kernel),在不增加计算量的前提下将原特征属性空间投影到高维空间,使其可以应对非线性可分的数据集。
在实验中,采用LIBSVM函数库[3]构建支持向量机分类器,并分别对加入L2标记和加入L5标记的数据集进行实验。实验数据选取原始41个特征属性和缩减后的10个特征属性或者12个特征属性,停止阈值为0.01。因为支持向量机只能区分两个数据类,故将加入L5标记的数据集按照异常行为类型分成4个子数据集进行测试,每个数据集包含惟一一种异常行为以及所有的正常数据。结果如表1所示,其中#SV代表支持向量的数目。
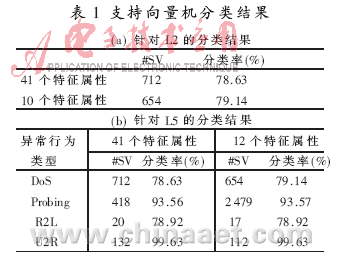
可见,通过信息增益方法选取特征属性的操作在提高训练效率的同时还有效地提高了分类准确率。针对扫描(probing)以及U2R攻击,支持向量机能够达到90%的分类率,而DoS和R2L攻击也有接近80%的分类率。此外,通过分析支持向量,能够总结出区分各种异常行为的最有效特征属性。从f2(协议类型)特征属性可以发现,扫描攻击倾向于使用ICMP协议;从f3(服务类型)特征属性可以发现,扫描攻击经常访问eco I(ping)服务;从f6(目的字节)特征属性可以发现,探测攻击传输较少的字节数;从f12(登陆)特征属性可以发现,U2R和R2L攻击发生在登陆之后;从f24(srv数目)特征属性可以发现,被探测攻击的服务器倾向于初始化更多的连接数。
3.2 多层神经网络
一个多层的神经网络由一定数目的节点组成,所有节点被分成输入层、输出层和若干个隐藏层。不同层中的节点通过不同权重的链接关联起来。实验中,将选取的特征属性的值作为输入,通过基于梯度下降的反向传播算法迭代计算权重值,直至达到规定的迭代次数" title="迭代次数">迭代次数。
实验中,使用原始41个特征属性的数据进行实验。对加入L2标记的数据集,统计不同隐藏节点数目的神经网络的分类率。对加入L5标记的数据集,统计10个隐藏节点的神经网络给出的分类结果。具体参数设置如下:输入节点数41,输出节点数2或5, 迭代次数1000。分类结果如表2所示。当隐藏节点数目为8时可以达到较优的分类率,继续增加隐藏节点的数目不会进一步优化分类结果。

4 不带监督的方法
通过实验可以看出,带监督的方法可以通过训练达到较高的检测率。然而,在实际应用过程中,目前没有可靠的方法来获取正确标识的训练数据。因此在实验中同时选取了不带监督的模式识别方法中的两种聚类算法,Single-Linkage和K-Means。
在现实网络环境中,正常数据的数量通常远远大于异常数据的数量,而且二者之间通常有比较大的距离。因此通过聚类算法将正常数据分成几个大的类,同时将所有无法划分到这几个大类的数据认定为异常,从而区分出正常行为和异常行为。
4.1 数据过滤
在KDD99训练数据集中,异常数据数目超过了正常数据,为了满足前提假设,需要过滤掉一部分异常数据,使得最终的数据集有超过98%的正常数据,而异常数据量小于2%。
4.2 数据标准化
由于没有足够可靠的先验知识来确定特征属性的相对重要程度,所以全部的特征属性都被同等考虑。然而,如果对于不同特征属性使用相同权重,则那些取值较大的特征属性会过分影响聚类的过程,大数量级的特征属性将占统治地位,而小数量级的特征属性在整个分类过程中的作用将被忽略。因此实验中将每个特征属性按如下方法进行标准化:
(1) 计算每个特征属性的均值和标准差:
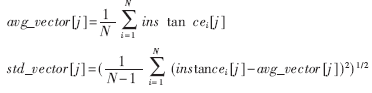
式中,vector[j]是每条记录的第j个特征属性。
(2)将每条记录中连续的特征属性值j进行如下转换:
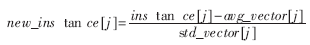
对于离散的特征属性,如果两条记录对于该离散特征属性具有相同的取值,则它们之间的距离为0,否则为1。
4.3 Single-Linkage
Single-Linkage算法以标准化后的数据集和常量参数W(类半径)为输入,计算输出聚类结果。它初始化的类集合为空集。对于每条记录,如果类集合为空,则将此记录作为一个类中心填入类集合中,否则计算它与现存每个类中心的距离,选出最短的距离。如果这个距离小于一个指定的参数常量W,则将此记录归于距离最小的类,否则增加一个新的类并将该记录作为类中心。
假设98%的数据都是正常数据,设置了一个阈值N。任何包含大于总记录数据量N%的类都被认为是正常类(实验中选取N=7)。这里应用入侵检测领域常用的ROC曲线描述检测结果。
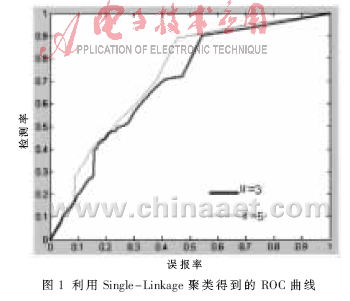
改变参数W的取值,ROC曲线如图1所示。结果表明,在误报率小于20%的前提下,Single-Linkage算法的检测率超过50%。
4.4 K-Means
K-Means算法根据输入参数k,将含有n条记录的数据集分配到k个类中,使得同一类中的记录具有较高的相似性。其中,每个类由该类中所有记录的平均值(类中心)进行标识。算法首先随机选取k条记录,每条记录代表一个初始类。对其余的记录,则按照它们同k个类中心的距离进行聚类,选取最近的作为该记录的分类。然后根据现有的聚类更新各个类的中心,再根据新的类中心进行下一次聚类,直到聚类结果稳定。
实验中,对不同参数k和初始的类中心进行测试。首先固定参数k,采用不同的随机记录进行初始化,得到的结果最终无较大差异。因此选取前k条记录作为初始的类中心。通过改变k的取值,得到如图2所示的ROC曲线。
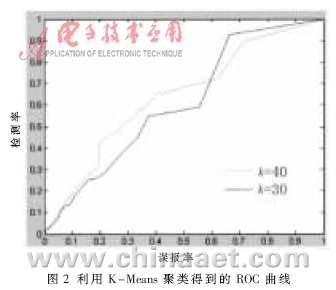
从图1和图2可见,聚类算法在检测率高时误报率也较高,但由于其时间复杂度相对较低,可以将其应用于数据预处理。方法如下:通过设置不同的阈值提高检测率,当检测率达到90%时,误报率在60%左右(见图1和图2)。此时聚类算法检测出来的异常数据集,保留了原始数据集中超过90%的异常数据,同时过滤掉了大约一半的原始数据集中的正常数据,从而得到了一个可以应用带监督的方法进行进一步检测的小数据集。而且由于异常数据在原始数据集中占的比例很小,通过上述预处理方法得到的数据集的数据量约为没处理之前的一半。
本文利用模式识别中带监督的支持向量机和神经网络方法以及不带监督的Single-Linkage和K-Means方法分析网络数据记录,进行入侵检测。实验证明,利用信息增益的方法,只选取对分类结果影响较大的特征属性进行实验,不会降低检测的准确度;同时两种带监督的方法具有很高的检测率,可以直接用于检测入侵行为,而两种不带监督的方法检测率相对较低,且当检测率高时误报率也高。但是,由于这些聚类方法的时间复杂度都相对较低,因此可以将其应用于对原始数据的预处理,在不对检测结果产生过大影响的基础上,过滤掉大量的正常数据,得到一个相对较小但基本上包含了所有原有入侵的数据集,能够大大压缩下一步检测的输入数据量。对于过滤后的数据,采用支持向量机或者多层神经网络分类器进行检测,能够达到更高的检测效率。
参考文献
[1] MACQUEEN J B. Some methods for classification and analysis of multivariate observations. Proceedings of 5-th Berkeley Symposium on Mathematical Statistics and Probability. Berkeley: University of California Press,1967:281-297.
[2] UCI Knowledge Discovery in Databases Archive.http://kdd.ics.uci.edu /databases/kddcup99/kddcup99.html,1999
[3] CHANG Chih Chung, LIN Chih Jen. LIBSVM——A library for support vector machines.http://www.csie.ntu.
edu.tw/~cjlin/libsvm/, 2007.
[4] BISHOP C M. Neural networks for pattern recognition[M]. Oxford:Oxford University Press,1996.