
基于MAP算法和高阶倒谱归整的电话语音识别方法
2008-07-21
作者:徐 洁, 杨鼎才
摘 要:介绍一种融合最大" title="最大">最大后验概率算法和改进的高阶" title="高阶">高阶倒谱归整的抗噪声语音识别" title="语音识别">语音识别方法。将最大后验概率算法用于特征空间来估计电话通道特性(通道差的估计),用分段高阶倒谱归整进行后续补偿,可以同时减少电话语音中卷积噪声和加性噪声的影响。实验结果验证了该方法的有效性,与传统的倒谱均值减相比,训练库中识别率从46.3%提高到87.5%。
关键词: 电话语音识别 高阶倒谱规整 最大后验概率估计 分段
电话语音识别借助通信平台,实现了语音技术的更广泛应用,人们通过最便捷的电话方式可以查询到远端数据库中的所需信息,给日常生活带来了极大的方便。然而由于电话网络中各种噪声的影响,使得语音识别系统的性能大幅度下降。电话语音的噪声主要分为两部分:背景噪声和电噪声的影响为加性噪声;由电话话筒和传输线引起的通道影响,即卷积噪声。尽可能地减少这两种噪声在电话语音中的影响,提高电话语音的鲁棒性" title="鲁棒性">鲁棒性是系统达到实用化的关键。
针对电话语音鲁棒性的研究,前人已经作了很多工作,提出的一些方法如倒谱均值减[1](CMS)、CDCN[2](Codeword-Dependent Cepstral Normalization)、相对谱RASTA[3](RelAtive SpecTral)处理技术等,对减少测试环境与训练环境的失配都有一定的效果。但随着噪声的增强,以上方法对系统性能的提高都非常有限。
基于最大后验概率(MAP)算法的自适应方法利用Bayes理论,通过对模型参数进行修正,显示了相当好的性能。为了减小模型计算的复杂度,该文也将MAP算法用于特征空间,用该算法估计电话通道影响。高阶倒谱归整是将倒谱均值减的均值归一扩展到更高阶阶矩归一。研究发现,当归一化较高阶数的阶矩时,失配进一步减少,带噪语音信号的概率密度函数更接近干净语音的概率密度函数,特征参数更具有鲁棒性。
本文提出了一种基于最大后验概率算法的估计通道影响方法,并用改进的高阶倒谱归整作后续补偿,将两者结合同时提高系统对加性噪声和卷积噪声的鲁棒性。实验表明这种方法能有效地提高电话语音识别系统的识别率。
1 算法描述
1.1 通道估计理论
假设Y(n)表示实际的电话语音倒谱矢量,X(n)表示纯净语音的倒谱矢量,h表示通道响应的倒谱失量。在不考虑背景噪声的情况下有:
Y(n)=X(n)+h (1)
1.2 MAP算法[4~5]
在MAP算法中,后验概率由似然函数和先验概率组成。由于引入了通道的先验统计特性" title="统计特性">统计特性,理论上MAP算法比最大似然估计算法(ML)估计得要准确。因此,用MAP估计通道向量与均值的差,把(4)式中的△ 表示为△MAP,同时,为了表示方便,将Y(n)-
表示为△MAP,同时,为了表示方便,将Y(n)-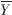 用Z来表示。
用Z来表示。
运用MAP算法求△MAP,用公式表示为:

其中P(△h|Z)是后验概率,直接从(5)式中估计△MAP是很困难的,然而(5)式等价为:
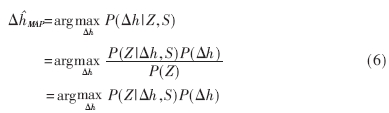
为计算方便,将(6)式取对数,得到: 
1.3 分段高阶倒谱归整
研究发现,加性噪声对语音的影响不仅表现在均值的增加、方差的减少上,它还改变了倒谱的更高阶阶矩。为了更好地补偿带噪语音的统计特性,Yong Ho Suk等人提出了三阶倒谱归整[6]CTN(Cepstrum Third-order Normalisation),将归一化的阶矩提高到三阶。在此基础上,提出了分段三阶倒谱归整SCTN(Segmental Cepstrum Third-order Normalization),通过一个一定帧长的滑动窗的作用,使倒谱特征在不同的噪声环境下具有相同的分段统计特性。设滑动窗帧长为N,具体计算方法为:
(1)计算一阶倒谱归整,即每帧特征向量减去N帧的均值,若当前处于第n帧,则计算以下N帧的均值:
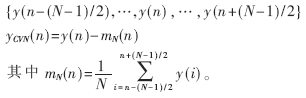
(2)除以N帧的均方差,使归一化后倒谱矢量有相同的方差。
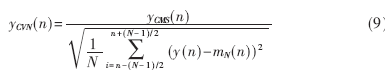
(3)根据三阶倒谱归整的定义,将(9)式代入(10)式:
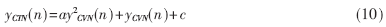
其中a、c可以根据(10)式的一阶矩为零、二阶矩为一常数、三阶矩为零来确定。因为笔者认为语音信号倒谱系数的概率密度函数是准高斯分布的,根据随机信号的知识,倒谱的奇数阶矩为零,而偶数阶矩为某个特定的常数。最后得到:

1.4 融合算法
将MAP算法与分段三阶倒谱归整进行融合,融合过程如图1所示。

电话语音Y(n)首先进行倒谱均值减得到Y(n)-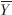 ,然后通过Viterbi译码得到最优状态序列,同时根据通道的先验概率,用(8)式计算△MAP,代入(4)式,再进行(10)式运算得到最后的特征矢量,由第二次Viterbi译码得到识别结果。其中△h的先验统计特性由训练库数据得到。
,然后通过Viterbi译码得到最优状态序列,同时根据通道的先验概率,用(8)式计算△MAP,代入(4)式,再进行(10)式运算得到最后的特征矢量,由第二次Viterbi译码得到识别结果。其中△h的先验统计特性由训练库数据得到。
2 实验结果与分析
本实验的训练数据和识别数据采用PKU-SRSC语音数据库中的窄带电话语音,内容为5s的数字串,包括训练集和测试集。系统采用自左向右的连续隐马尔可夫模型。模型用4个状态来表示,每个状态由3个高斯混和元组成。系统的前端提取特征为MFCC及其一阶差分,帧长256点,帧移80点,信号的采样频率8000Hz,每帧14维MFCC及其一阶差分共28维。基线系统的特征在前端提取后进行倒谱均值减得到。
表1列出了基线系统,以及采用RASTA、三阶倒谱归整、MAP方法和MAP分别与三阶倒谱归整、分段三阶倒谱归整相结合的方法的识别率比较。其中分段三阶倒谱归整滑动窗长度为80帧。
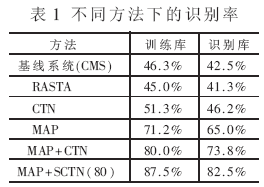
从表1中可以看出,将MAP算法用于特征空间对电话通道影响进行补偿,可大幅度提高电话语音识别系统的识别率,同时与通常的MAP用于模型空间相比,大大减少了运算量和复杂度。采用MAP与三阶倒谱归整相结合的方法比单独采用各种补偿算法时的识别率都高,在训练库中识别率达到80.0%,在识别库中识别率为73.8%。进一步研究,MAP与分段三阶倒谱归整相结合时,与基线系统的CMS方法相比,在训练库中识别率提高了47.1%,在识别库中识别率提高了48.5%。
用实验选择了分段归整时的滑动窗长度,图2给出了在不同N值时系统的识别率,其中横轴的500帧表示整句语音的长度。可以看出当N=80时具有较高的识别率。
参考文献
1 Furui S. Cepstral analysis technique for automatic speaker verification. IEEE Trans on Acoustics, Speech and Signal Processing, 1981;29(4):254~272
2 Alejandro Acero, Richard M.Stern. Environmental robustness in automatic speech recognition. IEEE International Confer-ence on Acoustics, Speech and Signal Processing,1990;2:849~852
3 Hermansky H, Morgan H. RASTA processing of speech. IEEE Trans on Speech and Audio Processing, 1994;2(4):578~589
4 Jen-Tzung Chien, Hsiao-Chuan Wang, Lee-Min Lee. Esti-mation of channel bias for telephone speech recognition. International Conference on Spoken Language Processing, ICSLP, 1996;3:1840~1843
5 R.A Bates, M.Ostendorf. Reducing the effects of linear channel distortion on continuous speech recognition. IEEE Transactions on Speech and Audio Processing,1999;7(5):594~597
6 Yong Ho Suk, Seung Ho Choi, Hwang Soo Lee. Cepstrum third-order normalization method for noisy speech recogni-tion. Electronics Letters, 1999;35(7):527~528