
摘要:本文首先采用了soft cascade结构的头结点分类器检测出大量的背景图像;然后,通过一个贪婪搜索算法构建分叉树分类器,将不同的台标分类到正确的检测线路中;最后,使用普通cascade结构来得到更加准确的识别结果。实验结果,本文的检测器可以获得较高的识别准确度。
关键词:soft cascade,joint boosting,canny算子
0 引言
自动的电视台标检测和识别已经在多媒体领域获得非常高的关注度。如今,多数的手机都具备了摄像头功能,所以人们可以随心所欲地拍摄各种事物,然后利用各种算法去分析处理获得的图像。本文中,展示一个系统一利用手机内置摄像头帮助人们识别电视频道信息。日常观看的电视频道就有几十个不同的台标,所以可以把这个问题看作是一个多类检测问题,而单类的检测即识别,最终就实现了多类识别。
对于单类检测问题,Viola和Jones给出了state-of-the-art算法。他们先训练了一系列节点分类器去检测图像里的每一个子窗口,只有那些能够通过所有节点分类器的子窗口图像才被认为是正样本。吴将Voila的工作简单地拓展到了多视角人脸检测" title="人脸检测" target="_blank">人脸检测上,为每个独立的人脸视角训练了一个不同的 cascade结构,并且并行地运用它们进行检测。但是当正样本的类型数量增加时,这个方案所花费的检测时间也是线性增长的,而这个代价是我们无法负担的。Torrobla提出了一种新的boosting框架,命名为jointboosting。他将N类分类问题转化为N-1个两类分类问题,然后自动地共享相同的弱分类器。尽管它的检测器可以共享特征,但是当检测目标时,它仍然需要计算全部特征,所以它并不是一个快速检测框架。
近些年来,树形检测器被引入了多视角人脸检测应用中。许多研究者更加偏爱于这种树形结构,例如,Fleuret和Geman的scalar tree,Li等人的金字塔结构,还有Huang chang的广度优先搜索树。在他们的工作里,Huang的工作最有新意,他提出来一种新的输出一个布尔矢量的boosting算法,取名为vector boosting。由于它具有良好的性能,本文选用它作为分叉树的部分。有别于多视角人脸的并行结构,经验证明直接构建一个由粗到精的树是比较困难的。故此,本文设计了一种根据不同组合的误报率来构建分叉树的方法。详细的方案会在1.3中阐述。
本文的其他部分是这样组织的:在1.1小节中,本文介绍所采用的特征集,然后简要地描述下普通cascade结构和soft cascade结构。在实验过程中,作者测试了本文算法的精确度和检测所需的平均特征数。
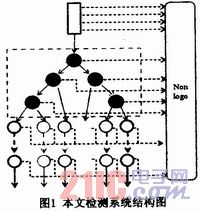
1 检测器框架
在实验中,本文采用了一架摄像机来拍摄电视节目的全屏幕图像。考虑到此方法的通用性,不假设关于台标位置的先验信息(尽管台标通常会出现在屏幕的上部)。为了可以检测出台标,本文先使用了一个分类器对大量的不同尺度和位置的子窗口进行扫描。因为多数的子窗
口都是背景,而背景的轮廓特征不明显,所以可以将任务分割成两个部分:首先是尽可能早的拒判掉非台标的子窗口,然后是区别每个台标属于哪个频道。接下来描述下算法的第一部分。
1.1 通用检测器
Viola在他的人脸检测中成功地运用了adaboost结构和由haar特征构成的弱分类器。OpenCV也给出了该算法的代码。许多目标检测的问题也经常用到Viola的检测框架,有时也只是用别的特征集替换了haar特征。
如图2所示,电视台标的主要属性就是它的轮廓特征。在行人检测中,基于梯度方向直方图(HOG)的特征是一种描述轮廓的十分有效的特征。这个特征的缺点是它的输出是一个矢量,所以需要用一个基于支持向量机的弱分类器,但是它要花费大量的计算时间。文献提出了一个EHOG特征,它只输出一个值,并可以很容易地被Adaboost算法使用。

因此在本文的台标检测器中,使用了EHOG特征。对于一副训练图像,计算一个块Rb里的梯度直方图,然后在n个方向分别统计梯度幅度的总和。
![]()
n是HOG特征的维数(在中,n=9),本文中设置为6。
然后,本文使用了中定义的主方向梯度D概念,D是上述区间集的一个子集,即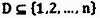 ,并计算对应D方向的EHOG特征:
,并计算对应D方向的EHOG特征:
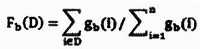
为了快速地计算特征,本文也应用了积分直方图方法。
本文采用了EHOG特征和gentle adaboost训练了一个普通cascade结构,然后在所有桩分类器中收集全部的弱分类器,并用校正算法重新排序它们,得到一个新的“soft cascade”检测器。
![]()
本文定义为前t个弱分类器的响应值的和。运用了校正算法后,可以得到一个迹数组trace=(r1,r2,…,rN)。当对一个样本x做决策时,加上每一个弱分类器的响应值ht(x),然后就将ht(x)和rt进行比较,如果低于,就立刻拒绝该样本。Soft cascade结构的性能要优于Viola的Cascade,在获得相当的检测性能时,它需要较少的特征数。这些将会在后面的实验中展示。
第一层的普通检测器可以拒判大量的背景图像,却还不能区别不同类的台标。为了做进一步处理,仍需要一个可以解决多类别分类问题的算法结构。
1.2 分叉树
在Huang的工作里,他构建了一棵由粗到精标注了人脸的不同视角的树。分叉树上的每个节点分类器采用了矢量boosting算法训练得到,依靠假设输出空间的矢量化来解决多类问题。举例说明,在一个节点分类器上,有四个可能的输出矢量((0,O),(0,1),(1,0),(1,1)):(0,0)代表着该样本的检测将终止于当前节点。(0,1),(1,0),(1,1)代表着该样本将会通过哪个孩子节点。
在文献中,相邻的视角在分叉树里的距离也很近。全部15个不同视角是根据旋转角度平分成15份得到的。由于在本文的多台标检测中没有关于某两个台标是近邻的先验知识,所以不能依靠经验来构建一棵由粗到精的分叉树。例如,当面对图2中的6类台标时,在分叉树的根节点上,不知道该如何将它们划分成两个子节点。如果将明显不同的台标放在同一个节点里,训练算法将会耗费更多的特征才能获得一个相对较好的分类。基于这样的想法,作者认为一个较好的划分应该是在固定的迭代次数上利用矢量boosting训练得到一个更好的分类结果。
假设有N类正样本集,在第一层分叉节点上,就有2N-1-1种组合数可以将一个包含N类的集合划分成两个正样本子集。
如果盲目地寻找一个合适的树,总的时间复杂度会是log(N)*2N,这是无法实现的。为了解决这个问题,以下本文将引入一个贪婪搜索算法。
在一个二维矢量boosting算法里,正样本数据被标示为(O,1)或者(1,0),负样本数据被标示为(-1,-1)。本文用{S1,S2,…,SN}来表示所有的数据,那么左边子节点的数据集就是,右边子节点的数据集就是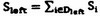 ,这里Dleft和Dright是(1,2,…,N)的子集。
,这里Dleft和Dright是(1,2,…,N)的子集。
本文设置检测率为O.995,迭代次数为10。误报率被用来评估算法性能。在矢量boosting算法中,判决准则如下:

对于本文的6类台标数据集,将给出节点划分的算法流程,这里一个二进制串001001表示一种划分模式,0代表进入左子节点,1代表进入右子节点。
算法1划分节点集合的贪婪搜索算法
输入:{S1,S2,…,SN}
输出:划分模式p
初始化p:p={00,…,0};
初始化一个包含比特串的空列表;
外层循环i=1:N-1

内层循环结束
p(Selectedidx)=1
将p和其局部最小fp值插入列表;
外层循环结束
输出列表中最小fp值对应的比特串。
有了生成的二叉树和soft cascade结构,本文基本上完成了多类台标的检测和识别。其中一个重要参数是soft cascade的长度,如果选择较短的cascade,检测器看上去更接近并行cascade结构的检测器;如果选择较长的cascade,分叉树可能要面对很难区分的负样本,从而降
低检测性能。本文中,尝试了很多种不同长度的soft cascade,然后挑选性能最好的一个。算法2如下:
算法2混合分叉树分类器
输入:训练好的soft cascade结构,查询树,N类正样本数据集S,还有一个数量很大的背景图像集B;
输出:一个混合分叉树分类器
(1)初始化:分叉树的根节点用soft cascade结构替代;
(2)树的节点训练:
a.从S集和B集中,挑选出所有可以通过分叉树当前节点E的父节点的样本,确保正负样本集p和n的规模相当;
b.如果背景图像集规模不够,终止该节点E的分叉,将E设为叶子节点;
(3)在查询树中搜索当前节点:
a.如果找到了,就根据查询节点集合将正样本集分成两部分,然后用Vector Boosting训练一个节点分类器。
b.否则,就用Gentle Adaboost训练一个强分类器。
(4)对于当前节点E的每个孩子节点,循环使用步骤(2)和(3)进行训练生成。
3 实验方案和结果
本文收集了6类台标集合,每一类包含了200张图像。而台标图像就是从这些图像中裁剪出来的,然后缩放成24×24像素大小的块,作为正样本集。负样本集则是从将台标区域掩盖掉后的图像上收集的。首先进行了一个实验,来解释WFS树的不同设计方案将会对算法性能带来怎样的影响,然后研究了soft cascade长度带来的影响,最后拿随机生成的树与本文的树进行对比。
本文首先使用了文献中提到的方法训练一个普通检测器,然后将其791个弱分类器组成了soft cascade。本文用这个soft cascade对一组测试图像进行了测试,统计结果表示每幅图像通过的平均特征数约为8。在实验中,作者发现这个长度值设置在平均特征数的1倍和2倍之间比较合适。
本文使用了上述正样本数据集和规模为1200的负样本数据集来构建查询树。最终生成的分叉树如图3所示。
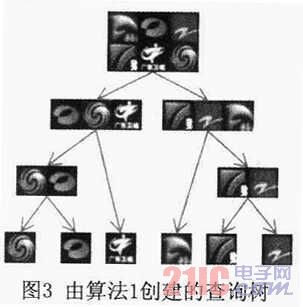
正如分叉树所示的,越相似的台标,它们在树里的位置越近。同时,本文也随机地生成了另一个查询树。使用这两棵树和同样的训练数据集,本文训练了两个WFS树检测器。
3.1 soft cascade的长度
当选择好查询树,本文就可以开始训练检测器了。作者尝试了不同的soft cascade的长度。本文调整叶子节点上分类器的阈值,确保两个检测器拥有相同的分类结果。
3.2 检测器的精确度
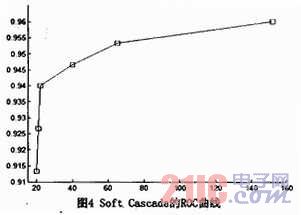
在本文的框架里,第一部分是整个结构的核心。在soft cascade中设置不同的alpha参数值,然后对将作为根节点分类器的soft casca-de尝试不同的长度。接着,调整每个叶子节点分类器上的阈值,可以得到如图4的ROC曲线。本文的soft cascade加WFS树结构的台标检测精确度要优于Huang的WFS树。与此同时,本文框架使用的特征数也比Huang的要少。

对于识别同一家电视台的不同频道,本文也采用了改进后的WFS结构。本文收集了9个不同的CCTV频道中央一至中央九,训练了一个CCTV系列检测器,它可以检测并识别出CCTV标志及其右侧区域里的数字符号。本文实验的结果数据如表1:

4 结语
本文实现了一个基于多层树形分类器结构的多台标识别方法,此方法具有对多类别标志识别的通用性。本文虽然在检测样本的平均特征数上有进一步减少,提高了算法的速度,并且在分叉树的叶子每个节点上增加了一个单类别cascade,降低了误检率。但是这种查询树结构在增加新类型台标时,需要重新生成和训练,花费大量时间。如果能找到一种增量学习算法,在增加新类别时,只需要对原有的查询树做局部修改,而不用全盘推翻重新计算,则该框架将更具实用性。