
引言
PPT(Microsoft Office PowerPoint),是微软公司开发的编辑演示文稿的办公软件。该格式相对于txt、chm等,信息量更大,结构也更加复杂,导致其对硬件配置要求较高。然而,目前嵌入式终端配置低,因此本文聚焦于满足人们对于移动阅读的基本需求,暂不考虑视频、音频和外部对象等特性支持。本解析器在开源环境下,基于Linux操作系统实现。基于嵌入式多格式解析引擎系统架构和中间格式理论,具有平台无关性、高效性的特点。
1 系统特点
该解析引擎兼容版本多,包括Microsoft PowerPoint 972003等版本。下面介绍一下系统特点。
① 不依赖于图形服务器。解析引擎拥有自己的专用的矢量图形绘制器。不依赖于特定的底层图形服务器。例如,我们的实验系统的图形服务器由nanoX改为Qt时,该解析引擎不需要修改。
② 高效性。对于一般的格式解析器,样本文件越大,打开速度越慢,而该解析器可以做到文件打开速度与文件大小基本无关。
③ 平台无关性。解析引擎并不是直接在显示设备上绘制图形和文字,而是把各种格式元素绘制在一段内存区域上,然后把这段内存数据映射到物理设备上。即输入是文件,输出是屏幕大小的位图。
④ 配置灵活。解析引擎的模块化设计便于移植和裁剪。所有数据类型采用宏定义,便于根据平台配置。
⑤ 支持手写批注。 解析器只做内容抽取和显示,不支持编辑和保存,支持手写批注。手写批注不改变原文档,而是新建xml描述文件。
⑥ 个性化交互方式。利用电子纸控制器的16通道和黑白刷,实现动画切换效果。
2 格式分析
2.1 总体结构
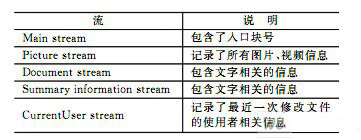
Microsoft PowerPoint使用OLE2组合文档存储。和文件系统结构类似,它包含容器和流,并组成的树状结构。各种流独立存储,便于载入和快速保存。如表1所列,PPT文件包括以下5种流式数据。
表1 PowerPoint文件结构
PPT存储格式采用十六进制,small endian字节序,分为若干个大数据块和小数据块,大小分别为512字节和64字节,第一个数据块为初始数据块,存储了数据块索引表。
2.2 图像流结构
PPT中包含矩形、图片框、文本框、线、椭圆等204种形式的元素,统称为Shape。每种Shape有一个唯一的实例码与之相应。
多媒体数据的层次结构如图1所示。

图1 容器层次结构
Drawing GROUP为组合图形存储结构,它包含了一组图形对象。Drawing为图形存储结构,Shape和Solver为两组图形属性元数据。Blip Store为插入的图片对象。Property Table为缺省属性表。Client Data为一组元数据信息,包含坐标,文本和OLE数据和用户自定义属性表。
属性项采用idvalue结构,自定义属性表的长度可变。各项属性相对位置不变。自定义属性表中出现的属性将覆盖默认属性。
Drawing为一组描述来管理容器中的图形对象的规则集合,包括对齐方式、标尺等。
摘要: 根据目前主流电子纸阅读器硬件资源有限、要求功耗小、灰阶显示等特点,提出了一种PPT格式文档解析方案。聚焦于满足人们对于移动阅读的基本需求,选取了文字、图形、图像作为基本解析对象,设计并实现了一个适合电子纸阅读器的PPT格式引擎,并进行了多重优化以提升性能体验,在低端的硬件配置和有限的运行时间内完成格式解析。
引言
PPT(Microsoft Office PowerPoint),是微软公司开发的编辑演示文稿的办公软件。该格式相对于txt、chm等,信息量更大,结构也更加复杂,导致其对硬件配置要求较高。然而,目前嵌入式终端配置低,因此本文聚焦于满足人们对于移动阅读的基本需求,暂不考虑视频、音频和外部对象等特性支持。本解析器在开源环境下,基于Linux操作系统实现。基于嵌入式多格式解析引擎系统架构和中间格式理论,具有平台无关性、高效性的特点。
1 系统特点
该解析引擎兼容版本多,包括Microsoft PowerPoint 972003等版本。下面介绍一下系统特点。
① 不依赖于图形服务器。解析引擎拥有自己的专用的矢量图形绘制器。不依赖于特定的底层图形服务器。例如,我们的实验系统的图形服务器由nanoX改为Qt时,该解析引擎不需要修改。
② 高效性。对于一般的格式解析器,样本文件越大,打开速度越慢,而该解析器可以做到文件打开速度与文件大小基本无关。
③ 平台无关性。解析引擎并不是直接在显示设备上绘制图形和文字,而是把各种格式元素绘制在一段内存区域上,然后把这段内存数据映射到物理设备上。即输入是文件,输出是屏幕大小的位图。
④ 配置灵活。解析引擎的模块化设计便于移植和裁剪。所有数据类型采用宏定义,便于根据平台配置。
⑤ 支持手写批注。 解析器只做内容抽取和显示,不支持编辑和保存,支持手写批注。手写批注不改变原文档,而是新建xml描述文件。
⑥ 个性化交互方式。利用电子纸控制器的16通道和黑白刷,实现动画切换效果。
2 格式分析
2.1 总体结构
Microsoft PowerPoint使用OLE2组合文档存储。和文件系统结构类似,它包含容器和流,并组成的树状结构。各种流独立存储,便于载入和快速保存。如表1所列,PPT文件包括以下5种流式数据。
表1 PowerPoint文件结构
PPT存储格式采用十六进制,small endian字节序,分为若干个大数据块和小数据块,大小分别为512字节和64字节,第一个数据块为初始数据块,存储了数据块索引表。
2.2 图像流结构
PPT中包含矩形、图片框、文本框、线、椭圆等204种形式的元素,统称为Shape。每种Shape有一个唯一的实例码与之相应。
多媒体数据的层次结构如图1所示。
图1 容器层次结构
Drawing GROUP为组合图形存储结构,它包含了一组图形对象。Drawing为图形存储结构,Shape和Solver为两组图形属性元数据。Blip Store为插入的图片对象。Property Table为缺省属性表。Client Data为一组元数据信息,包含坐标,文本和OLE数据和用户自定义属性表。
属性项采用idvalue结构,自定义属性表的长度可变。各项属性相对位置不变。自定义属性表中出现的属性将覆盖默认属性。
Drawing为一组描述来管理容器中的图形对象的规则集合,包括对齐方式、标尺等。
3 软件设计
本设计以嵌入式多格式解析引擎系统架构为基础。解析引擎是负责对源文件进行解析,生成中间格式需要的数据的模块。
解析引擎的内部架构如图2所示。

图2 解析引擎架构
3.1 语法分析器
语法分析器为输入流数据,输出为结构化数据供各模块使用。PPT格式的记录采用idvalue结构,id和value占据规定的字节数,语法分析器负责识别记录id,并抽取value。
3.2 导航器
负责把数据从文件系统调入内存,并把I/O流转换成结构化数据,即用DOM结构描述文件的整体架构。
该模块具有页面导航作用。PPT使用OLE2组合文档存储。容器和结点只存储粗粒度索引信息,对于不需要立即显示的页,只存储容器结点,暂时不展开,需要显示该页时,再从该结点向下展开,从而减少了不必要的文件读取。这种分层装载方法,提高了打开速度,并且对于大文档,进入速度只和第一页的复杂程度有关。
此外,为了更好地索引,建立了一系列的链表结构。如:数据块索引表、根目录表、图像数据流链表、用户反向链表、文本链、母板链表等。
文件长度、版本号、进行文件合法性等信息通过读取初始化块获得。除此之外还需要初始化几个重要的全局链表。
① 数据块索引表。文件以块为单位存储,且不连续,数据所属块号和块内偏移量可以方便地进行寻址操作。
② 构建根目录表,包括存储内容的起始块号和大小,用于寻址操作。读操作只在当前块范围内,当超出当前块可读长度时,通过查询块索引表找到下一块的块号。
③ 构建图像数据流链表。
④ 构建用户反向链表。为了快速保存,PPT采用增量式存储,即每次保存时,直接生成页面副本并追加到文档末尾。增量式存储的缺点是冗余量大。例如,有的文件只有几页,但文件大小几MB甚至几十MB,文件实际大小和修改次数有关。
⑤ 幻灯片文本链,流信息到排版元数据独立存储。纯文本存储在文本流中,存储以及排版信息存储在页数据区。页数据区还存储了纯文本在文本流中的位置。
⑥ 母板链表,母板一般作为背景,以页为单位顺次存储。因为电子纸显示灰度图像,背景和正文叠加以后看不清楚,用户阅读时可以去除背景,而不会影响到文件本身。
增量式存储的基本思想是:每次修改产生一个用户信息,存储修改的块号,当前用户信息反向指向上一个用户信息,从而构成一个用户反向链。遍历用户反向链可以找到最后一次修改。冗余数据可以直接丢弃。
3.3 布局管理器
负责屏幕划分和图层管理,布局管理器划为不同的矩形区域,并标识该区域的类型。然后分别将解析得到的文字,图形,图像缓冲区映射到屏幕位图上。
3.4 文字处理器
PPT格式的文字种类和布局相对复杂,可以分为正文和图形内嵌文字两种,各级标题正文的布局也有要求。文字处理器针对各种文本的排版格式多样性进行解析和布局,完整再现原文档的版式信息。
文字处理过程分为预排版和页面排版两部分,预排版负责填充字模缓冲区,抽取字符编码和字体信息作为FreeType的输入,用生成的单个字模位图填充缓冲区。然后结合标尺和对其方式把映射到页面显示缓冲区。文字解析原理图如图3所示。

图3 文字解析原理图
3.5 图形渲染
负责图形绘制和组合图形坐标空间转换。本解析引擎不依赖于图形服务器,拥有专用的矢量图形绘制库。能够将图形直接绘制到页面位图中,与物理显示无关。
绘制直线,曲线和多边形填充分别采用了经典的Breshman算法,三次贝塞尔曲线画线算法,列扫描多边形填充算法3种成熟算法。为了提高了运算效率,对于浮点数作取整运算。经验证,在浮点数运算效率不佳的嵌入式系统上也能到达较好的渲染效果。
组合图形(Drawing GROUP)包含了一组图形对象,采用了Dom结构。子结点使用相对于父结点的坐标空间。因此,图形处理能够递归地进行坐标转化,并把图形绘制在其父结点的坐标空间内。
3.6 图像渲染
图像渲染器采用Cximage图像库把图像数据重构,并进一步转化成灰度图像放入屏幕缓冲区。
文件中图像和多媒体信息存储在图像流中,通过FBSE (File Blip Store Entry)描述。于是定义了结构体:
typedef struct _FBSE{
MSOBLIPTYPE imageType;
ULONG id;
ULONG size;
ULONG cRef;
ULONG offsetInDelayStream;
}FBSE;
4 优化提速
用户总是希望系统越快越好,但是嵌入式系统受主频较低、内存较小的限制,对于一些计算量比较大的工作,很难达到理想的效果。于是本解析引擎在应用了多页面缓冲机制和异步并行机制的优化策略。
各渲染器异步并行地工作,第一个完成任务的渲染器立即把数据提交给屏幕显示。电子纸整屏刷新速度为1 s,利用这个刷屏间歇,其余渲染器完成任务,再采用局部刷屏的方式把增量部分刷新到屏幕上。这样整体速度取决于渲染速度最慢的那一个。此外,异步执行不阻塞输入,如果这时用户翻页,未完成解析线程会被终止,并建立新线程来解析下一页。例如:打开一页图文混排的幻灯片,打开时先显示文字,随后显示出图像,并且不会阻塞用户输入,假如用户快速连续翻若干页后停止,中间页解析会被终止。
5 验证
在主频200 MHz的电子纸阅读器上实现效果如图4所示。

图4 在电子纸阅读器上解析效果图
随机选择60个样本文件,进入书籍最短时间2.82 s,最长11.92 s.如图5所示。
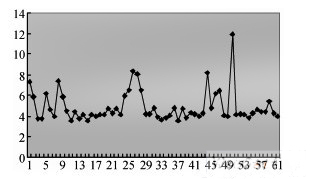
图5 在电子纸阅读器上解析速度统计图
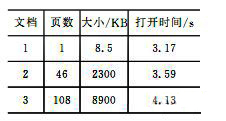
解析引擎采用分层装载方法,提高了打开书籍速度,这里选择了3个第一页完全相同但是大小差别较大的PPT文档。实验表明,虽然文档大小差别很大,但是打开速度差异不大。如表2所列。
表2 启动速度对比
结语
由于电子纸的特性和嵌入式设备的资源限制,本文仅仅聚焦在常用元素的解析上,如文字、图形、图像、表格等,而对于嵌入对象(如视频、音频等)没有支持。对于未知元素的解析将成为未来的主要工作。本文模块化的设计架构,有利于下一步进行功能扩展,另外,随着Office开放文档格式(OOXML)的诞生并成为国际标准,未来将开发支持OOXML的嵌入式解析器。