
摘 要: 使用Intel Parallel Amplifier高性能工具,针对模糊C均值聚类算法在多核平台的性能问题,找出串行程序的热点和并发性,提出并行化设计方案。基于Intel并行库TBB(线程构建模块)和OpenMP运行时库函数,对多核平台下的串行程序进行循环并行化和任务分配的并行化设计。
关键词: 多核;并行化;模糊C均值算法;Intel Parallel Amplifier;OpenMP
多核处理器的迅速发展,使得多核化不断全面普及。为了应对计算机硬件的发展要求,尽可能利用多核资源,就要设计出相应的并行化应用程序。多核平台下的并行化有多种方案,利用英特尔推出的高性能分析工具Intel Parallel Amplifier对串行应用程序进行性能分析,寻出热点实现并行化是其中的一种方法。
模糊C均值聚类算法(FCM)是一种常用的聚类算法,在大规模数据分析、数据挖掘、模式识别、图像处理等领域有着非常广泛的应用。它是给定分类数,通过优化目标函数得到样本点对聚类中心的隶属度,寻找样本点的最佳分类方案。本文将多核技术应用到模糊C均值聚类并行算法的设计中,把目标函数迭代的过程和处理数据的过程并行化,提高聚类过程的效率及多核处理器的利用率。实验结果表明,本方法减少了程序的运行时间,显示了多核编程的高效性。
1 模糊C均值聚类算法(FCM)
模糊C均值聚类算法[1]的基本思想是确定每个样本数据隶属于某个聚类的程度,把隶属程度相似的样本数据归为一个聚类。FCM把n个样本集合X={x1,x2,...,xn}分为c个模糊组,并且求每组的聚类中心Ci(i=1,2,…c),使得目标函数最小,该算法是优化目标函数的迭代过程。这个过程从一个随机的隶属度矩阵开始,确定聚类中心计算目标函数,通过迭代过程达到样本分类。
初始化:给定样本数n,聚类数c∈[2,n],模糊度m=2,迭代停止阈值?棕。

(4)如果目标函数的改变量小于?棕,停止算法,否者重复(2)直到改变量小于?棕。为了确保FMC得到一个最优解,要不断调整隶属度矩阵,需多次运行该算法。
2 多核技术与工具软件
2.1 Intel Parallel Amplifier高性能工具
Intel Parallel Amplifier是英特尔在2009年发布的高性能工具[2],界面设计友好,操作简单方便。开发人员只需要运行工具就可对串行程序进行分析,研究分析结果进行并行化设计,确保多核的完全利用。IPA(Intel Parallel Amplifier)有以下三种类型的性能分析。
(1)热点(Hotspot)分析:运行热点分析可收集到不同类型的数据,确定应用程序运行消耗的时间,以及识别出最耗时的函数。在执行程序时,IPA通过数据收集器定期采样,并在操作系统的协作下中断程序收集数据。它通过获取整个程序各个CPU核心的指令指针(IP)采样,计算出每个函数的运行时间,再用调用栈采样为程序创建调用关系树。
(2)并发性(Concurrency)分析:运行并发性分析可确定应用程序是否有效地利用了所有可执行核,识别出最有可能并行化的串行代码。它与热点分析一样收集数据信息,但是要比热点分析多,除了一般的程序运行数据,还有所有可执行核的工作情况。最理想的情况是执行程序的线程数等于处理器的可执行核数,也就是完全利用(Fully Utilized)。
(3)锁定和等待(Locks and Waits)分析:在前两种分析的基础上,运行锁定和等待分析,可获得更多的程序运行数据。
为了测试程序并行优化的效果,IPA提供了“比较结果(Compare Results)”的功能,用来比较串行程序和并行程序性能差别。
2.2 TBB线程构建模块
TBB线程构建模块(Intel Thread Building Blocks)是基于GPLv2开源的、用来实现并行语义的C++模板库[3]。TBB提供了高性能可扩展的算法,面向任务编程,支持任何ISO C++编译器,具有很好的可移植性。本文将Intel并行库TBB的tbb_block_rang2d和tbb_parallel_for配合使用,前者的作用是对一个二维的半开区间进行可递归的粒度划分;后者的作用可以实现负载均衡的并行执行固定数目独立循环迭代体。
2.3 OpenMP并行编程模型
OpenMP是为共享内存以及分布式共享内存设计的多线程并行编程应用接口,包含了一套编译语句以及一个函数库,是一个编译指令和库函数的集合[4]。OpenMP也可以用于多核处理器并行程序设计中。在OpenMP中线程的创建是通过编译指导语句实现的,本文采用sections和section命令。sections被称作工作分区编码,它定义了一个工作分区,然后由section将工作区划分成几个不同的工作段,每个工作段都由多核处理器的每个执行核并行执行。
3 C均值聚类算法的并行优化设计
3.1 基本流程
C均值聚类算法串行程序的并行化设计可分为以下几个阶段:首先用IPA高性能工具得到热点函数的花费时间和并行情况,分析串行程序的可并行性[5];然后运用TBB和OpenMP进行并行优化设计;最后使用IPA的Compare Results功能进行比较,测试并行程序的性能效果。基本流程如图1所示。
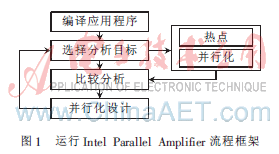
3.2 热点定位
通过“Hotspot”可以获得热点函数所花费的时间,调用栈信息可以得到它被不同函数调用花费的时间。IPA采集的数据为程序段花费的总时间、CPU运行的时间、CPU空闲时间、处理器的核数、执行程序的线程数等。找到热点函数后,打开源代码,分析哪些代码花费处理器时间最多。
3.3 并发性分析
Concurrency分析可以得到热点函数在执行过程中各个其他任务并行执行的情况,以及各个线程的任务分配情况。IPA并发性分析不仅包含热点采集的时间数据,更重要的是程序的并发状态。它用5种不同状态(Idle、Poor、Ok、Ideal、Over)表示并发性的情况。在多核平台下,理想的状态应该达到Ok以上,也就是说当热点函数运行时,其他线程同时工作在处理器上,这样可以提高多核资源的利用率。
3.4 串行程序优化
通过分析源代码,可以对串行程序进行如图2所示的并行优化。
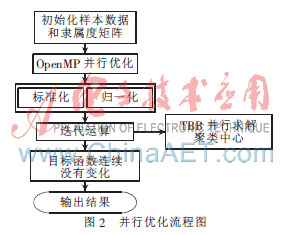
(1)因为隶属度矩阵的归一化和样本矩阵的标准化没有数据相关性,所以可以利用OpenMP的工作分区功能在两个线程中同时执行运算,提高多核的利用率,节省程序运行时间。使用OpenMP的优化设计:
#include <omp.h>
初始化数据
#pragma omp parallel sections//工作分区
{#pragma omp setion
样本数据标准化
#pragma omp section
隶属度矩阵归一化}
(2)归一化后的隶属度矩阵和标准化的样本数据做矩阵乘法的运算,可以使用TBB并行库进行优化设计[6-7]。TBB::block_range2d表示的是二维迭代空间的模板类,它包含在头文件TBB/blocked_range.h中,作用是根据需求对并行任务正确的划分。因为矩阵相乘是二维空间的运算,因此采用block_range2d模板类。迭代空间划分好后,就可以使用TBB::parallel_for执行并行操作。parallel_for包含在头文件TBB/parallel_for.h中,作用是对循环体进行并行化处理。使用TBB的优化设计:
#include “tbb/taske_scheduler_init.h”
# include ”tbb/parallel_for.h”
#include ”tbb/blocked_range2d.h”
task_scheduler_init init;//初始化对象
{//矩阵相乘的tbb并行化
parallelMul()double c, double a,double b}{parallel _for(blocked_range2d<size_t> (0,k,0,n),MatrixlMul(c,a,b));}
}
4 实验结果测试
本文采用UCI标准数据集中的Wine数据集作为测试实例,该数据集包含有178个样本,每个样本有13个属性特征,分为3类,每类分别为59,71,48,数据为178×13的矩阵。设定加权指数m=2,停止阈值ω=le-4。
(1)实验平台
硬件:Intel Pentium Dual T3400 @2.16 GHz 2.16 GHz,2 GB内存。
软件:Microsoft Windows XP professional service pack3操作系统;Visual.Studio.2008英文专业版;parallel_studio_ sp1_setup(评估版);tbb22_009oss_win(TBB2.2版本)[8]。
为了检测并行优化的效果,要对测试结果、热点、并发性和串行程序进行对比。
(2)实验结果
经过实验测试获得Wine数据集3个分类的样本数,分别为59、64、48,与标准分类相比误差很小。本文通过5次运行FMC得到的实验结果相同,说明模糊C均值算法的并行优化设计是可行的。
(3)热点对比
从图3可以看到并行后热点函数Update执行时间减少为15.321 ms,这是由于Update函数中有二维矩阵的并行化设计。在双核平台下,串行程序的线程数为1,而并行程序的线程数为3。

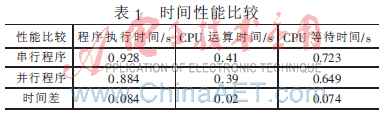
表1是IPA中Compare Results功能的比较结果,各项时间的差值都为正数,表明性能提高。
(4)并发性对比
从图4可以看到并行程序的并发效果。热点函数Update并行后不仅时间减少了,状态也由Poor变为Ideal。说明当热点函数运行时,其他线程同时运行在多核处理器上,多核利用率得到提高。

本文将Intel多核高性能工具应用到FMC串行程序的并行优化设计中,提出并行优化设计方案,把TBB和OpenMP引入到聚类算法的并行化设计中。并行聚类算法在处理海量数据时将大大节省时间,并且提高多核资源的利用率。下一步的工作是从并行算法的可扩展性进行探究,并在众核处理器上做进一步测试,以便更好地提高聚类算法效率。
参考文献
[1] 齐淼,张化祥.改进的模糊c均值聚类算法研究[J].计算机工程与应用,2009,45(20):133-135.
[2] 英特尔@软件网络[EB/OL].http://software.intel.com/en-us/intel-parallel-studio-home.
[3] REINDERS J. Intel threading building blocks[M]. O’REILLY出版社, 2007.
[4] 周伟明.多核计算与程序设计[M].武汉:华中科技大学出版社,2009.
[5] Peter Wang.使用Intel parallel Amplifier:一站式解决最佳方案[EB/OL]. http://software.intel.com/zh-cn/blogs2010-2-22.
[6] 曹婷婷.基于多核处理器串行程序并行化改造和性能分析[D].成都:西南交通大学,2009.
[7] 胡斌,袁道华.TBB多核编程及其混合编程模型的研究[J].计算机技术与发展,2009,19(2):89-101.
[8] Intel公司. Intel threading building blocks reference manual[EB/OL]. 2007. http: //threadingbuildingblocks. org/.