
摘 要: 提出了一种基于WordNet和GVSM的文本相似度算法,通过语义的路径长度和路径深度计算两个词的语义相似度,结合改进的GVSM模型计算文本相似度,并对基于TFIDF-VSM模型和本文方法进行了比较。实验结果表明,该算法取得了更好的准确率和效率。
关键词: 文本相似度;语义相似度;词网;广义向量空间模型
文本相似度计算在文本信息处理相关领域有着广泛的应用。目前,文本相似度的研究主要有三种方式:(1)篇章与篇章之间的相似度计算[1];(2)短语与篇章之间的相似度计算;(3)短语与篇章中段落的相似度计算。文本相似度计算方法主要有隐性语义索引模型、向量空间模型、广义向量空间模型、基于属性论的方法、基于海明距离的计算方法、基于数字正文的重构方法等。基于语义的相似度计算方法相关的研究主要有:使用WordNet进行相似度计算的方法;使用同义词词林进行相似度计算的方法[2];使用知网《HowNet》知识结构进行相似度计算的方法[3]。广义向量空间模型(GVSM) 是20世纪80年代由Wong提出[4],在词语消歧研究[1]、文本检索研究[5]等方面得到了很好的应用。
本文使用WordNet进行相似度计算的方法,采用广义向量空间模型, 并对广义向量空间模型进行了扩展,得到了新的广义向量空间模型。通过WordNet计算两个词的语义相似度,把语义相似度应用到GVSM模型中来计算文本相似度。实验结果表明,该算法取得了较好的准确率和效率。
1 背景知识介绍
1.1 向量空间模型
向量空间模型(VSM)是20世纪70年代末由Salton等[6]提出的一种代数模型。在近30年内,向量空间模型(VSM)被广泛应用到信息检索、文本分类、文本聚类等领域,并取得了很好的效果。其基本思想是:假设词与词之间是不相关的,以向量表示文本,每个维度对应于一个单独的词,则(w1,w2,w3,…,wn)文档dk可以看成相互独立的词条(t1,t2,t3,…,tn),为了表示词条的重要程度,给每个词条赋予相应的权值wi,其中文档dk可用向量(w1,w2,w3,…,wn)表示。向量空间模型中的文档相似度计算方法为:
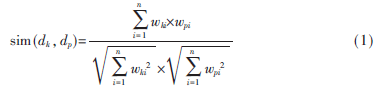
其中wki、wpi分别是词ti在dk和dp的权值,n是向量的维度。向量空间模型的前提是假设词与词之间是不相关的,但这种假设不现实,因为词与词之间往往存在语义相关。
1.2 广义向量空间模型
广义向量空间模型GVSM扩展的VSM模型,GVSM引入了词与词之间的相关度,并提出了一个新的向量空间,每个向量ti被表示成2n维向量mr,其中r=1,2,…,2n。文档相似度计算方法为:
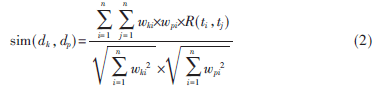
其中wki、wpi分别是词ti在dk和dp的权值,R(ti,tj)是词ti和tj的相关度。
1.3 WordNet介绍
WordNet由普林斯顿大学认知科学实验室在1985年建立,是一部在线词典数据库系统,采用了与传统词典不同的方式,即按照词义而不是词形来组织词汇信息。WordNet将英语的名词、动词、形容词、副词组织为Synsets,每一个Synset表示一个基本的词汇概念,并在这些概念之间建立了包括同义关系(synonymy)、反义关系(antonymy)、上下位关系(hypernymy & hyponymy)、部分关系(meronymy)等多种语义关系。不同的边代表不同的语义关系。
2 文档相似度计算
2.1 语义相似度计算
本文模型中使用WordNet衡量两个词的语义关系。分别考虑了路径长度SPC(Semantic Path Compactness)和路径深度SPE(Semantic Path Elaboration),给定两个词的语义相关度SR(Semantic Relatedness)由SPC和SPE合并得出。下面给出相关定义。

2.2 语义网络构建
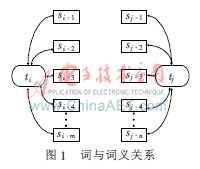
为了计算两个词的语义关联度,需要构建语义网络,采用了文献[7]的方法。相比较其他方法,它嵌入所有可用的WordNet的语义信息并提供了丰富的语义表达。根据所采用语义网络建设模式,每种类型的边将被赋予各自的权值,权重越高说明它们的语义关联度越高(如上位/下位边的权值定义为0.57)。词与词义的关系在语义网中如图1所示。
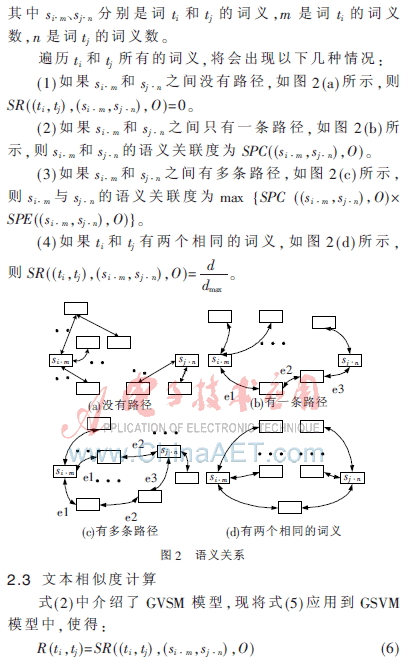

3 实验
利用上述方法,本文实现了基于WordNet的语义相似度计算程序模块。为了对相似度计算结果更好地进行分析,本文评价的方案放在文本分类系统中,以观察不同计算方法对文本分类系统性能的影响。
3.1 实验评价标准
评价标准是在测试过程中所使用的一些用来评价分类器分类准确度的量化标准。本文采用常用的三种标准,它们在不同的方面来评价一个分类器。
准确率(precision)= (分类正确的文本数)/(实际分类的文本数)
召回率(recall)= (分类正确的文本数)/(应有分类正确的文本数)

3.2 实验结果与分析
本文实验是在Windows XP操作系统、Eclipse开发环境下,通过Java语言实现。实验是在1 GB内存、P4 3.0 GHz CPU的PC机下进行的。实验数据集采用的是20-Newsgroups文本数据集。20-Newsgrops是在UseNet上下载的20个类的新闻组讨论英文文章。数据集共有20个类,每个类大约1 000篇。20-Newsgroups是一个比较常用的文本数据集。出于效率考虑,本实验选取其中的5个类别,针对不同数量的训练文本进行了实验,实验分别选取了200、400、600、1 000、2 000篇文本平均分配到编号为A、B、C、D、E的5个集合。分别对基于TFIDF-VSM[3]模型和本文提出的基于WordNet的GVSM模型进行了比较实验。本文采用KNN[8]分类器进行评价,测试结果记录了上述5种情况分类器的准确率、召回率、F1值。
实验结果表明,采用基于WordNet的GVSM模型比基于TFIDF-VSM模型具有更高的准确率、召回率、F1值。分析发现当文本数越多时,文本分类的准确率、召回率、F1值越高。
本文提出了一个新的文本相似度计算方法,将其成功地应用在文本分类当中,实验证明得到了很好的效果。首先基于WordNet构建了语义网,分别考虑路径长度SPC和路径深度SPE来计算两个词的语义关联度;然后将其应用在GVSM模型中计算文本相似度;最后应用在文本分类中,得到了较高的分类准确率和召回率。下一步准备将其应用到信息检索中,以提高信息检索的准确率与效率。
参考文献
[1] WILLETT P. Recent trends in hierarchical document clustering: a critical review. Inf Process and Manage, 1988:577-597.
[2] 夏天.汉语词语语义相似度计算研究[J].计算机工程,2007,33(6):191-194.
[3] 李峰,李芳.中文词语语义相似度计算——基于《知网》2000[J].中文信息学报,2007,21(3):99-105.
[4] WONG, S. K. M. Wojciech Ziarko, Patrick C. N. Wong. Generalized vector spaces model in information retrieval.SIGIR ACM, 1985.
[5] TSATSARONIS G, PANAGIOTOPOULOU V. A generalized vector space model for text retrieval based on semantic relatedness. Proceedings of the EACL 2009 Student Research Workshop, 2009:70-78.
[6] SALTON, MCGILL M J. Introduction to modern information retrieval. McGraw-Hill, 1983.
[7] VAZIRGIANNIS T M. Word sense disambiguation with spreadingactivation networks generated from thesauri[C]. In Proc. of the 20th IJCAI, 2007:1725-1730.
[8] HALL P, PARK B U, SAMWORTH R J. Choice of neighbor order in nearest-neighbor classification. Annals of Statistics: 2008:2135-2152.
[9] Qinglin Guo. The similarity computing of documents based on VSM. IEEE International Computer Software and Applications Conference. 2008:585-586.