
文献标识码: A
文章编号: 0258-7998(2011)05-0042-03
现代电子技术的发展,使得越来越多的车载电器加入到汽车电子行列中,在改善汽车性能的同时,也增加了汽车驾驶操作的复杂度,给行车过程带来了不安全隐患。随着语音识别算法的改进和新一代专用语音处理芯片的问世,使得语音控制代替了手动控制车载电器,从而减轻了驾驶员手动操作负担,大大提高了行车安全性。
目前我国的车身电子语音控制主要集中在汽车导航系统的应用上,语音识别技术在车身电子中的应用没有充分发挥。本文首次提出了一种以专用语音处理芯片UniSpeech-SDA80D51为核心组成的非特定人车载音响语音控制系统的设计方案,并实现了系统样机的研制。
1 车载音响语音控制系统
系统由语音采集、语音识别、控制驱动和车载音响等模块构成,系统完成的主要功能是:语音采集模块用于采集驾驶员发出的语音命令信号,由语音识别模块实现信号的A/D转换, 并对转换的数字信号进行语音识别处理,最终输出与语音命令相对应的词条编码信号,控制模块对接收的词条编码信号进行逻辑分析与处理并产生对应的控制信号驱动车载音响动作,代替驾驶员的手动操作。
1.1 语音识别模块
语音识别模块主要由UniSpeech-SDA80D51芯片及外围电路组成。
SDA80D51是德国Infineon公司专为语音识别和语音处理应用领域新推出的高集成度SoC专用芯片,其基本结构如图1所示。
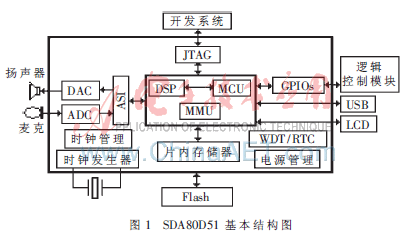
由图1可知,SDA80D51片内集成了直接双访问快速SRAM、2路ADC和2路DAC、多种通信接口和通用GPIO等部件。SDA80D51工作方式以M8051为主控制芯片,主要完成系统配置和SPI、PWM、I2C、GPIO等接口的控制以及语音数据的传输工作; DSP核心OAK为协处理器,完成语音识别算法、语音编解码算法等语音处理工作。
非特定人语音信号由定向拾音器输入,经过SDA80D51内部的数据采集模块进行A/D转换,再经过识别程序的预处理、端点检测、特征参数提取、模板匹配等处理,选择识别词表中最接近的词条序号作为识别结果,识别结果通过GPIO口输出。
1.2 控制驱动模块
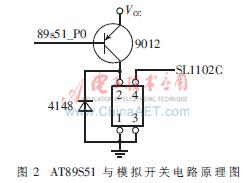
控制驱动模块由MCU和模拟开关及外围电路构成,模块主要用来接收语音识别结果,并对词条编码信号进行逻辑分析和处理,通过模拟开关电路产生对应功能的控制信号驱动音响动作。其中MCU选用美国ATMEL公司产品AT89S51,综合AT89S51输出I/O信号电压特性和SL1102C1音响控制面板电阻式分流键盘电路的特点,确定使用继电器模拟SL1102C1控制面板按键的闭合和断开动作。AT89S51和继电器模拟开关电路原理图如图2所示。
1.3 音响模块
本设计是基于SL1102C1型汽车音响。SL1102C1是专门为中档轿车设计的汽车音响,具有MP3播放、收音机和显示时间等功能,目前大量使用在江淮同悦轿车上。SL1102C1前板共有开关机/静音、音效、播放/暂停等15个按键和一个用来调节音量的编码开关。
SL1102C1前板键控为分压识别方式,按键包含短按和长按两种动作。AT89S51输出电压为TTL电平,直接驱动音响容易引起键码误识别,造成系统误操作,因此本文采用图2所示电路,很好地解决了上述问题。当AT89S51接收到语音编码信号后,立即进行逻辑分析并输出对应的控制信号驱动继电器吸合模拟按键动作,按键的短按和长按功能通过软件实现。
模拟开关电路还适用于SL1102C1前板上的编码开关,编码开关具有音量调节功能。开关旋钮旋转时,开关上端子输出对应的脉冲信号。当MCU收到操作编码开关的语音命令信号后,驱动端子输出脉冲信号,模拟开关旋钮功能。
2 系统软件设计
系统软件包括非特定人语音识别模块和逻辑控制模块。
2.1 非特定人语音识别模块
非特定人语音识别模块基于隐马尔可夫模型算法。HMM算法通过对大量语音数据进行数据统计,建立识别词条的统计模型语音库,然后从待识别语音中提取特征,与模型库进行匹配,由比较匹配分数得到识别结果,并通过SDA80D51的GPIO口输出。非特定人语音识别模块主要由信号预处理、特征参数提取、模型匹配和Viterbi算法部分组成,模块框图如图3所示。

2.1.1 信号预处理
信号预处理部分主要完成输入语音信号的采样、 模/数转换功能。A/D变换由SDA80D51内嵌12位A/D变换器实现,采样频率固定为8 kHz。
2.1.2 特征参数提取
特征参数提取基于语音帧,采用分帧提取特片。先对语音信号进行重叠分帧,前一帧和后一帧重叠一半(帧信号重叠是体现相邻两帧数据之间的相关性),帧长为25 ms,对每帧提取一次语音特片。
MFCC参数属于感知频域倒谱参数,反映了语音信号短时幅度谱的特征。p维MFCC参数的具体计算提取过程如下:
(1)用DFFT对每帧s(n:m)计算线性频谱,计算频谱模的平方为功率谱;
(2)功率谱经过 Mel 滤波器组获得到D个参数X(i),D是Mel滤波器组中三角形滤波器的数量;
(3)对X(i)做对数运算和离散余弦变换,余弦变换计算公式如下:

式中的Y(i)是第i个Mel滤波器对数能量的输出,i=1,2,…,D。
2.1.3 HMM语音识别算法
隐马尔可夫算法采用概率统计模型描述语音信号,HMM模型建立在Markov 链基础上,使用 MarKov 链来模拟语音信号统计特性的变化。HMM模型为双重随机过程,其一是Markov链,由(π,A)描述状态的转移,输出为状态序列;另一个是随机过程,由B描述,在统计意义上B反映了状态和观察值之间的对应关系,输出为观察值矢量序列。Markov链中状态和时间参数都是离散的Markov 过程。
Viterbi 算法是一种帧同步动态规整算法,在给定观察值序列和模型时,Viterbi算法给出了一个概率密度P(Q,O|λ)最大的状态序列。Viterbi算法包括初始化、递推、终止、路径回溯和确定最佳状态序列。

对于语音处理而言,因Q的变化,P(Q,O|λ)取值范围很大,而P(Q,O|λ)的最大值占了全部P(Q,O|λ)的很大的成分,所以可以用Viterbi算法来计算P(O|λ)。
2.2 控制模块
控制模块的主要功能是:在AT89S51查询到语音词条信号后,查表获得词条编码,根据编码判断对应按键是长按或短按,分别进入相应的子程序处理。在子程序中,输出语音命令所对应的I/O控制信号驱动继电器吸合模拟按键或编码开关动作,并及时复位I/O口。控制模块还具有完全兼容手动控制的功能,在语音控制操作的同时也可以进行手动操作,手动的优先级高于语音命令,这样可以避免语音控制和手动控制之间冲突。
控制模块部分程序代码如下:
void main()
{…… //初始化
while(1)
{…… //初始化
while(P0 == 0x00) //等待语音信号
{ WDTRST=0x1E;
WDTRST=0xE1; //WD指令
YXSY=0;}
YXSY = 1;
if(date != P0)
{ delayms(6); //延时函数
date = P0;
if(date==1 || date==2) //开机、静音
{ PWR = 0; //电源按钮按下
delayms(200);
PWR = 1;} //电源按钮松开
……
P1 = 0xff;
P2 = 0xff;}}}
3 系统实测结果
本系统在江淮同悦SL1102C1型车载音响上进行了非特定人语音识别率和模拟开关动作准确率测试。由于汽车音响的语音词条为2~4个字,语音识别率实验内容为车载音响常用2字词条指令18条、3字词条指令12条、4字词条指令10条,实验对象为6人4男、2女(普通话和方言),实验环境为实验室环境。为了提高系统的识别率,系统采用奥林巴斯 ME52定向麦克,提高了麦克接收范围,系统测试结果如表1所示。
由表1可知,系统的识别率与语音指令词条字数、麦克接收距离、说话人方言有关。男声和女声的识别率接近。

在系统控制电路实验中,模拟开关动作达到了较高的准确率,测试结果为98%以上,只要控制程序运行正常,各路继电器就能按照程序安排执行闭合和断开模拟手动开关操作。
实现汽车电器的语音控制是未来车载电器的发展趋势,越来越多的解决方案被不断提出和验证。本文提出的设计是在SL1102C1型车载音响上使用SDA80D51芯片,实现了车载音响非特定人的语音识别与控制。该设计得到的样机有较高的识别率,工作稳定、可扩展性强,达到预期的设计目标,整个设计方案和实现方法是可行的。由于语音识别率随着环境、说话人不同而变化,虽然HMM算法在噪声很少的环境下可以获得很高的识别率,但当测试语音或者环境中含有不同程度的噪声污染时,语音识别系统的性能会有所下降。提高系统的抗噪性和鲁棒性是语音识别系统走向实用化的关键之一。
参考文献
[1] 杨行峻,迟惠生.语音信号数字处理[M].北京:电子工业出版社,1995.
[2] Inifneon.UniSpeech2V2.0 functional specification[Z].Infineon Technologies AG,2002.
[3] 韩纪庆,张磊,郑铁然.语音信号处理[M].北京:清华大学出版社,2004.
[4] 王海青.基于CDHMM的口令式语音识别系统及其DSP实现[D].合肥:中国科学技术大学,2003.
[5] BURCHARD B,ROMER R,FOX O.A single chip phoneme based HMM speech recognition system for consumer applications,Consumer Electronics,IEEE Transactions on,2000,46(3):914-919.
[6] Masao Namiki,Takayuki Hamamoto,Seiichiro Hangai.Spoken word recognition with digital cochlea using 32 DSP-boards. IEEE Trans.on Acoust,Speech,Signal Processing,2001,2:969-972.