
支持向量机在机械零件识别中的应用
2009-04-16
作者:晏开华, 苏真伟, 黄明飞
摘 要: 提出了一种将支持向量机(SVM)用于机械零件识别的方法。实验采用了97张零件图片,9类零件其中一部分作为训练样本,另一部分作为测试样本。提取零件的Hu矩作为特征向量,并将BP神经网络与SVM进行了比较。实验结果表明,以多项式为核函数的SVM有较高的识别率。
关键词:支持向量机; 零件识别; Hu矩; BP神经网络
零件识别是计算机视觉与模式识别在机械工业领域中的重要应用之一。它作为机械加工自动化的基础,将人从繁重的劳动中解放出来,提高了生产率,也降低了成本。机械零件识别已经在国内引起了广泛关注,现有的方法主要集中在模板匹配和神经网络方面[1-3]。
支持向量机SVM(Support Vector Machine)是Vapnik等人根据统计学习理论(SLT)提出的一种新的机器学习方法。SVM建立在SLT的VC维理论和结构风险最小化原理的基础上,根据有限样本信息在模型复杂性与学习能力之间寻找最佳折衷,以期获得最好的推广能力。SVM有效地克服了神经网络分类中出现的过学习、欠学习以及陷入局部极小值等诸多问题。在解决小样本、非线性及高维数等模式识别与回归分析问题中,表现出独特的优势和良好的应用前景。近年来,SVM在手写体识别、人脸识别、文本分类等领域都取得了很大的成功[4-6]。
本文将SVM应用在零件识别上,通过实验,取得了比较满意的结果。
1 支持向量机
1.1 VC维和SRM
支持向量机最初是建立在VC维和结构风险最小化原理基础上的。在模式识别方法中VC维被直观地定义为:对一个指示函数集,如果存在h个样本能够被函数集中的函数按所有可能的各种形式分开,则称函数集能够把h个样本打散。能打散的最大样本数目就是它的VC维,它反映的是函数集的学习能力。VC维越大则学习机器越复杂。结构风险最小原则(SRM)是统计学理论中提出的一种新策略,即把函数集构造为一个函数子集序列,并使子集按VC维的大小排列;在每个子集中寻找最小经验风险,在子集间折中考虑经验风险和置信范围使实际风险最小[7]。
1.2 最优分类面
如图1所示,实心圆和空心圆分别代表两个不同的类,H为超平面,H1和H2分别为各类中离分类超平面最近的样本,且平行于分类超平面的平面。H1、H2上的样本点就是支持向量,margin为它们之间的距离,称为分类间隔。所谓最优分类面就是能使两类正确分开,而且使分类间隔最大。前者保证经验风险最小,后者保证置信范围最小,从而使实际风险最小[7]。

设有N个训练样本,(x1,y1),…,(xl,yl)·xi∈Rn,yi∈{+1,-1},若线性可分,则存在决策函数:
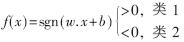
SVM的目的就是要找出一个最优超平面,使得margin=
从而原始最优问题转换为求:
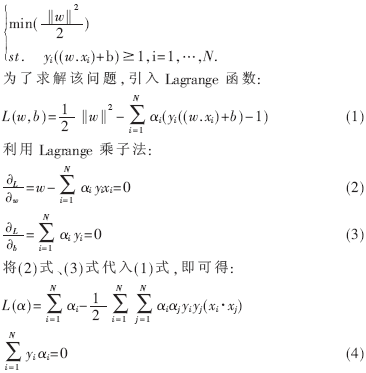
问题已转换成求解(4)式的最小值。通过这种转换,将问题转换成一个不等式在条件约束下的二次寻优问题,存在唯一解α*,再转换成对偶问题后,即可求得最优超平面的参数,w*、b*:
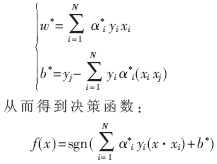
对于非线性问题,SVM的核心思想是利用非线性映射Ф,将输入向量映射到一个高维空间,然后在这个高维空间中构造最优分类面。Rn上的样本集{xi,yi}映射到高维空间得新样本集{φi(xi),yi},然后根据新样本集构建最优分类面,所得判决函数:
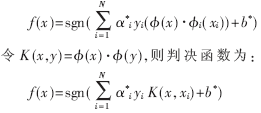
式中,K为核函数,不同的核函数产生不同的支持向量机算法。核函数的选择在支持向量机算法中是一个难点[8]。常见的核函数有:
(1)多项式核函数:K(x,xi)=[(x,xi)+1]d,d为多项式阶数。
(2)径向基形式核函数RBF: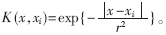
(3)Sigmoid核函数:K(x,xi)=tanh(v(x,xi)+c)。
1.3 SVM多类分类方法
基本的支持向量机方法仅能解决二分问题,要实现多分问题,需要在二分的基础上构造出多类分类器[9-11]。SVM的多类分类方法目前主要有以下三种:
(1) 一对多分类器
对N类分类样本,构造N个两类分类器,其中第i个分类器用第i类的样本作为正样本,其余样本作为负样本。判别方式是:对某个输入待测样本,其分类结果为分类器输出值最大的那个分类器类别。
(2) 一对一分类器
对N类中的每两类构造一个子分类器,需要构造N(N-1)/2个分类器,然后采用投票法确定分类结果。
(3) 决策树分类器
将多类分类问题分解为多级两类分类问题,如图2所示。
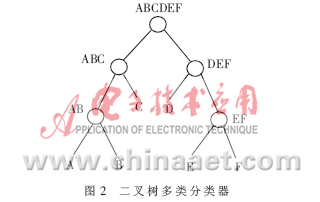
以上三种就是目前流行的SVM的多类分类器构造法。第一种方法的优点是构造的分类器少,缺点是容易产生多个相同输出值,降低了识别率;第二种方法的缺点是类别多了以后,构造的分类器较多,优点是采用投票法,识别结果更好;第三种方法介于前两种方法之间,缺点是如果某个结点发生误判,就会导致下面输出都是错的。本文选用第二种方法来构造多类分类器。
2 特征提取
零件识别,主要基于零件的形状,而矩特征能够充分反映物体的形状信息。Hu提出的7个不变矩,对于目标的平移、旋转、缩放都不敏感。本文提取零件的Hu矩作为SVM的训练样本特征空间。Hu矩的y计算如下:
设f(x,y)为一幅二维数字图像,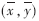 为图像质心位置,则0~3阶中心矩定义如下:
为图像质心位置,则0~3阶中心矩定义如下:

3 实验结果与分析
实验采用了97张零件图像,每张为1 024×1 280,总共9类零件,样本集42张,被测集55张,如图3所示。

基于SVM和神经网络的零件识别流程图分别如图4、图5所示。
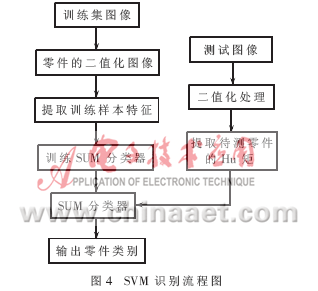
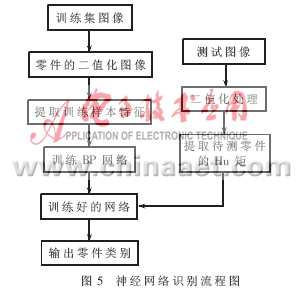
实验1:分别对不同核函数情况下SVM识别情况进行了比较,发现以多项式为核函数的支持向量机分类器有较好的识别效果,如表1所示。

实验2:将SVM与神经网络的识别率进行比较。发现SVM的正确率比较高,如表2所示。
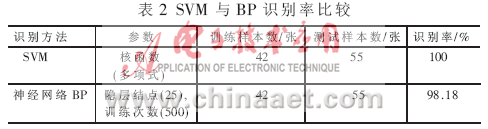
零件误识别的主要原因是零件二值化时,分割效果不好,造成特征提取有一定的误差。然而,SVM却能很好地识别,这进一步证实了SVM比神经网络有更好的泛化性。
以统计学习理论为基础的SVM,不仅克服了神经网络过学习和陷入局部极小的问题,而且具有很强的泛化能力。经过实验验证,将SVM用于机械零件识别的方法行之有效,识别率高于神经网络。
参考文献
[1] 欧彦江.基于神经网络的机械零件识别研究,四川大学硕士论文,2006.
[2] 吴文荣.基于机器视觉的柔性制造岛在线零件识别系统研究,电子科技大学硕士论文,2004.
[3] 安新,李丽宏,安庆宾,等,机械零件识别系统的研究.微计算机信息,2006,22(7):236-238.
[4] 朱家元,杨云,张恒喜,等.基于优化最小二乘支持向量机的小样本预测研究.航空学报,2004(6):29-32.
[5] 尚磊,刘风进.基于支持向量机的手写体数字识别.兵工自动化,2007,26(3):39-41.
[6] 陈鹏.智能交通中汽车牌照自动识别系统的研究. 中国海洋大学硕士论文,2005.
[7] VAPNIK V N.统计学习理论的本质[M].张学工译.北京:清华大学出版社,2000.
[8] 郭丽娟,孙世宇,段修生.支持向量机及核函数研究. 科学技术与工程,2008(2):487-490.
[9] PLATT J, CRISTIANINI N, TAYLOR J S. Large margin DAGS for multi-class classification. Asvances in Neural Information Processing Systems, 12 ed. S.A. Solla, T. K.Leen and K.-R. Muller, MIT Press, 2000.
[10] MAYLRAZ E, ALPAYDIN E. Support vector machines for multi-class classification. Proceedings of the International Workshop on Artificial Neural Networks (IWANN99),IDIAP Technical Report 98-06,1999.
[11] WESTON J, WATKINS C. Watkins. Multi-class support vector machines. In Proceeding of ESANN99,ed.M.Verleysen,D.Facto Press, Brussels, 1999: 219-224.