
基于语句结构及语义相似度计算主观题评分算法的研究
2009-05-15
作者:贾电如,李阳明
摘 要:文字类主观题的自动评分是实现远程教育中在线考试系统的一个关键技术,由于其自动评判具有相当难度,使自动评分系统中在对语句结构、关键字匹配、词性、词义以及语义方面的判断还存在很多问题。通过对已有的算法分析,提出了一种方法,采用浅层次句法结构分析和深层次语义分析相结合的算法计算相似度,该方法可以提高主观题自动评分的效率和准确度,具有一定的实用价值。
关键词:自动评分;动态规划;语句相似度;语义相似度
目前,在线考试系统正在逐渐代替传统的考试系统,能否实现主观题自动评分是在线考试系统中一个重要环节。对于主观题的考查,由于它的答题涉及到人工智能、模式识别以及自然语言理解等方面的理论知识,评阅时就需要解决很多技术上的问题,因而成为阻碍在线考试系统发展的一个技术难点。
当前的主观题自动评分算法中,多数使用的是对学生答案和标准答案中关键字匹配来计算语句相似度,如基于向量空间模型TF-IDF方法、词性词序相结合的方法以及基于语义依存树等[1-4]。已有的这些方法要么从句子的表层结构信息进行匹配而忽略了语句语义分析,要么就是从语义分析而影响了整体语句的相似性,这些都会影响到自动评分计算的精确度。由于汉语语言的结构和语义的复杂性,一种意思可以用多种形式和多种关键字表达,单从一方面很难对语句的意思作出准确的判断,因此提出了一种新的主观题自动评分算法策略,主要思想是采用浅层次句法结构分析和深层次语义分析相结合的算法计算相似度,将这两种思想结合起来使用可以互补不足,提高了主观题自动评分的准确度。
1 语句相似度计算算法
在主观题自动批改系统中,语句相似度是用来评价学生答案和标准答案的接近程度。针对汉语的特殊性和机器翻译领域内一些对语句相似度的研究,采用动态规划法来计算语句相似度,主要思想是对语句进行层次句法分析。首先用正向最大匹配(MM)和基于词频统计的方法对句子分词,将分词后得到的语句视为词的向量,分别对各个关键词进行匹配。然后在此基础上利用动态规划算法求出最优路径及语句相似度[5]。
1.1 相关定义
令P表示标准答案中的某一语句,Q表示学生答案中的某一语句。P和Q分别表示如下:P={P1,P2,…,Pm},Q={Q1,Q2,…,Qm},其中Pi表示P语句中的一个关键词,Qj表示语句Q语句中的一个关键词,且Pi=Pmi U Pgi, Qj=Qmj U Qgj,其中Pmi表示语句P中第i个词的词义集合,Pgi表示语句P中第i个词的词性集合;同理Qmj表示语句Q中第j个词的词义集合,Qgj表示语句Q中第j个词的词性集合。为了便于进一步讨论给出以下几个定义:
定义1:词义、词性相似度。词义、词性相似度可分别表示为:SMij=SM(Pmi,Qmj),SGij=SM(Pgi,Qgj)。
定义2:关键词相似度。关键词相似度Wij=a×SMij+β×SGij其中a、β分别为词义、词性相似度的权值。
定义3:词向量的相似矩阵。用定义2计算出语句P和Q的所有关键词的相似度Wij(i=1,2,…,m;j=1,2,j=i=1,2,…,n),形成一个m×n矩阵M,称该矩阵为语句向量的相似矩阵。
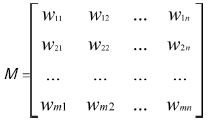
定义4:拓展词向量相似矩阵,对矩阵M进行如下拓展,形成矩阵M',令M'0,0=0, M'i,0, M'0,j=0(i=1,2,…,m; j=1,2,…,n),则M'i,j=max{M'i-1,j-1+Wij, M'i,j-1+γ,M'i-1,j+γ},其中,γ表示词位置不对应时的惩罚系数。
1.2 语句相似度求解算法
(1)利用动态规划法先求出M'矩阵[6]。
(2)M'矩阵的初始化
创建一个(m+1,n+1)矩阵,矩阵的行表示标准答案语句P的每个词,矩阵的列表示学生答案语句Q的每个词,利用定义4进行初始化,将M'矩阵的M'i,0,M'0,j设置为0.其中i=0,1,2,…,m; j=0,1,2,…,n。
(3)利用定义1、2、3、4依次求解M'矩阵中的每个元素M'i,j。
(4)求解最优相似矩阵
先从点(m,n)开始,到(1,1)结束。在点(i,j)上选择M'i-1,j-1+Wij,M'i,j-1+γ,M'i-1,j+γ最大者为最优点,所对应的Mx, y作为路径的前一个节点(x,y)。如果出现三者中两部分值相同且最大时,若该值在斜路径上则选择斜路径上(i-1,j-1)作为路径的前一个节点;若不在斜路径上,优选水平方面(i-1,j)作为路径的前一个节点;依次递推则选择一条最优路径。这样得到的路径上就是一条最优的路径,路径上最后一个点的值M'm,n表示了语句中所以词的相似度之和。
设L是标准答案语句的词数,则语句相似度为Sim=M’m,n/L。
2 语义相似度计算算法
Dekang Lin[7]认为任何两个事物的相似度取决于它们的共性(Commonality)和个性(Differentces),然后从信息理论的角度给出任意两个事物相似度的通用公式:

其中分子是描述A、B共性所需要的信息量的大小;分母是完整地描述出A、B所需要的信息量大小。刘群[8]认为两个词语的相似度是它们在不同的上下文中可以互相替换且不改变文本的句法语义结构的可能性大小。在本文中计算语义相似度是利用《知网》中词语相似度的定义[9],可以把词语语义相似度的计算归结为“概念”相似度的计算;“概念”的相似度由描述它的“义原”的相似度得到。词语存在着一词多义的现象,知网中的一词多义表现为单个词语有多个概念,每个概念由一项定义来描述。比如:“打”在“打架”,“打太极”,“打猎”中的意义各不相同,知网中对应的概念描述分别是:
DEF = fight| 争斗
DEF = exercise| 锻炼,sport| 体育
DEF = catch| 捉住, # animal| 兽
词语语义相似度的计算,严格来讲应该是计算概念之间的语义相似度。本文中采用刘群的思路,认为两个词语的语义相似度是其所有概念之间相似度的最大值。
Sim(c1,c2)=maxSim(C1i,C2j)(i=1,2,…,m;j=1,2,…,n)
其中, C1i是词C1的m项概念,C2j是C2的n项概念。这样就把两个词语之间的相似度问题归结到了两个概念之间的相似度问题。本文利用语句相似度中分词方法将词语标注为概念,然后再对概念计算相似度。
2.1 义原相似度的计算
由于所有的概念都最终归结于用义原来表示, 词语整体相似度由部分相似度合成的,所以义原的相似度计算是概念相似度计算的基础。所有的义原根据上下位关系构成了一个树状的义原层次体系,这里采用刘群的公式计算语义相似度的方法。
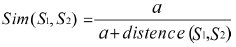
其中,S1、S2表示两个义原, distance(S1, S2)表示它们的路径长度,a是一个可调节的参数。在知网的知识描述语言中,在一些义原出现的位置都可能出现一个具体词(概念),并用圆括号( )括起来。所以本文在计算相似度时还要考虑到具体词和具体词、具体词和义原之间的相似度计算。理想的做法应该是先把具体词还原成知网的语义表达式,然后再计算相似度。这样做将导入函数的递归调用,有可能导致死循环,反而使算法变得很复杂。由于具体词在知网的语义表达式中只占很小的比例,因此可以作如下处理:具体词与义原的相似度定义为一个比较小的常数γ。具体词和具体词的相似度按两个词相同则为1否则为0。
2.2 概念相似度的计算
由义原相似度可以计算概念相似度,词语整体相似要建立在部分相似的基础上。把一个复杂的整体分解成部分,通过计算部分之间的相似度得到整体的相似度。假设两个整体A和B都可以分解成以下部分:A分解成A1, A2,…, An, B分解成B1, B2,…,Bm ,那么这些部分之间的对应关系就有m ×n 种。但并不是这些部分之间的相似度都对整体的相似度发生影响,所以应该选择那些发生影响的部分之间的相似度,选择出来后再进一步得到整体的相似度。在比较两个整体的相似性时,首先要做的工作是对这两个整体的各个部分之间建立起一一对应的关系,然后在这些对应的部分之间进行比较。如果某一部分的对应物为空则将任何义原(或具体词)与空值的相似度定义为一个比较小的常数δ;其他整体的相似度通过部分的相似度加权平均得到[10]。对于实词概念的语义表达式,可以将其分成四个部分:
第一独立义原描述式:将两个概念的这一部分的相似度记为Sim1(S1,S2);
其他独立义原描述式:语义表达式中除第一独立义原以外的所有其他独立义原(或具体词),将两个概念的这一部分的相似度记为Sim2(S1,S2);
关系义原描述式:语义表达式中所有的关系义原描述式,将两个概念的这一部分的相似度记为Sim3(S1,S2);
符号义原描述式:语义表达式中所有的符号义原描述式,将两个概念的这一部分的相似度记为Sim4(S1,S2)。
于是两个概念语义表达式的整体相似度记为:
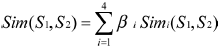
其中,βi(1≤i≤4)是可调节的参数,且有β1+β2+β3+β4=1,β1≥β2≥β3≥β4 。后者反映了Sim1到Sim4对于总体相似度所起到的作用依次递减。由于第一独立义原描述式反映了一个概念最主要的特征,所以应该将其权值定义得相对比较大,一般应在0.5 以上。
3 实验测试与分析
以《操作系统》课程为实验素材,选取2006级计算机专业学生的90份考卷中4道简答题为例。每道试题的分数是10分,分别通过计算机自动评分和人工阅卷,所得到的评分结果进行分析,得到如下表所示:
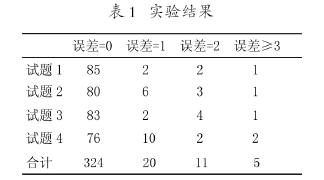
其中误差为自动评分与人工评分所得分数之差。由于系统中分词词典中缺少某些专用词汇或由于语句繁琐较长,可能导致得分的偏差。但是对于主观题来说,在人工评阅时,也受到教师情绪等诸多因素的影响,因此认为只要误差小于1分的就认为得到了正确的评分。
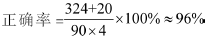
本文综合运用了语句层次结构、句法、词性、语义等特征来计算相似度,不仅考虑词语的局部相似,还从语句的整体出发,考查了语句语义整体相似性,大大提高了相似度计算性能,降低了计算的时间复杂度,同时也提高了主观题自动评分的准确性,具有一定的实用价值。
参考文献
[1] 孟爱国,胜贤.一种网络考试系统中主观题自动评分的算法设计与实现[J]. 计算机与数字工程,2005,33(7):147-150
[2] 李彬,刘挺,秦兵.基于语义依存的汉语句子相似度计算[J]. 计算机应用研究, 2003,20(12): 15-17.
[3] 李素建.基于语义计算的语句相关度研究[J]. 计算机工程与应用, 2002,38(7):75-76.
[4] 李明琴,李涓子,王作英,等. 语义分析和结构化语言模型[J]. 软件学报, 2005,16(9): 1523-1533.
[5] 高思丹,袁春风. 语句相似度计算在主观题自动批改技术中的初步应用[J].计算机工程与应用, 2004,40 (14): 132 -135.
[6] Levitin A . The Design and Analysis of Algorithm [M]. Beijing: Electronics Industry Press, 2003.
[7] LIN De Kang. An Information2Theoretic Definition of Similarity Semantic distance in Word Net [A] .In: Proceedings of the Fifteenth International Conference on Machine Learning [C].1998.
[8] 刘群,李素建.基于《知网》的词汇语义相似度计[C]//第三届汉语词汇语义学研讨会,台北,2002,5.
[9] 董振东,董强.“知网”网站[DB/OL].http://www.keenage.com.
[10] 朱征宇,苑昆峰,陈杏环.一种基于最大权匹配计算的信息检索方法[J]. 计算机工程与应用, 2007,43(33):176-179.