
Turbo码是近年来通信系统纠错编码领域的重大突破,他以其接近Shannon限的优越性能博得众多学者的青睐。本文采用基于Max-Log-Map的优化译码算法,对状态量度归一化计算和滑动窗算法等关键技术进行优化,在满足性能要求的情况下,大大降低算法复杂度。
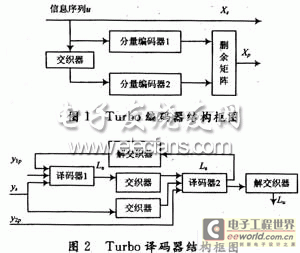
1 Turbo编码器.译码器及算法
Turbo编码器采用3GPP的编码方案,由约束长度K为4,码率为1/2的RSC编码器通过1个交织器并行级联而成,为提高性能对2个译码器分别附加3个尾比特使译码器的最终状态为全0。
译码器采用反馈迭代结构,每级译码模块除了交织器,解交织器外主要包括两个级联的分量译码器;一个分量译码器的输出的软判决信息经过处理成为外信息输入另一个分量译码器,形成迭代译码,在迭代一定级数后硬判决输出。

编码网格表贯穿整个译码过程,任意时刻k~k+1的RSC网格结构如图3所示,图中编码器输入的0~7状态可以由二进制表示。
下面介绍Max-Log-Map算法。
由于需要进行大量的乘法运算和指数运算,Map算法不适用于硬件实现。ERFanian和Pasupanthy最早提出了Map算法在对数域的简化算*og-Map算法。通过转换到对数域运算,避免了指数运算,同时乘法变成加法,而加法则变成Max运算,不过由此也会带来了一定的性能损失。下面简要描述Max-Log-Map算法。设Ak(s),Bk(s),Γk(s)分别代表对数域的前向状态度量、后向状态度量和分支度量,其表达式分别可表示为:
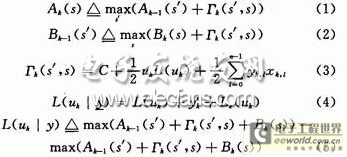
如图3所示,每个节点状态s都对应于一个Ak(s),1个Bk(5)和2个Γk(s)。因此编码网络贯穿整个编译码过程,译码前要先按图3建立网格映射表。
2译码器实现的关键改进与优化
Turbo码译码是一个复杂的过程,之所以这么说,除了算法本身复杂外,还有两个主要的原因,一个是递推计算过程中前、反向度量不断增大给信号处理器带来的麻烦,即经常说的溢出;另一个是大存储量需求。这里,就这两个细节问题进行讨论和总结,并且给出详细解决方案。
2.1状态量度归一化问题
由式(1),式(2)可注意到,随着计算的不断深入,状态量度值不断增加,为防止计算溢出和减小硬件复杂度,必须对其进行归一化处理。一种方法是减去前一时刻状态度量的最小值,这种方法在每个时刻都需要减法器和用于计算最小值的比较器,当状态数较多时,由此带来的额外的时延和硬件消耗是不能忽略的。本算法采用一种十分有效的归一化方法(以Ak(s)为例),在每个计算时刻,判断有没有状态度量值(A或B)大于某一门限值T,若有则所有节点的状态度量值(A或B)都减去T,若没有则保持原值不变。这样便大大减少了减法器使用的次数,也无需计算最小值。由于所有的节点都减去了相同的值,因此式(5)的结果不会受到影响。T值不宜设置太大,但设置得太小,归一化发生的很频繁,会增加译码时延和硬件开销。通过试验仿真,若q代表状态量度值的量化字长,则T设为2q-2为合适。
2.2 引入滑动窗减小存储量
由于Turbo码译码算法的迭代特性,每一级Map译码器需要大量存储器。在译码时引入滑动窗,能有效减少所需的存储量。采用滑动窗的Map译码步骤为:每次译码过程被分为若干段以间隔L(假设滑动窗的长度为L,L《N)连续进行,只需在对nL长的数据进行前向处理后,每个反向子处理过程即可执行,而未使用滑动窗时,需要对整个数据块处理后才能进行。实验证明,滑动窗大小选择7~8倍的约束长度时对误码率的性能影响几乎可以忽略。本算法中约束长度为4,选择窗口大小为32。下面给出采用滑动窗译码前后两种算法存储空间分配情况的比较。假设编码帧长为L,B表示窗口长度,L为B的整数倍。

按照表1,这个存储空间为26L,当L=1K时,为26K。如果我们采用分块译码,按照表2,那么整个译码的存储需求为20B+8L,B一般取编码约束长度的5~10倍,对于8状态编码,取B=32,那么这个存储空间为640+8L,与表1的26L相比要小的多。

当L=1K时,存储空间只占原来的33.2%。当编码帧长L的取更大值时,存储空间的节约更加可观,比较得知采用滑动窗后,Turbo译码能够大大节省硬件的存储资源。
3 Turbo译码的DSP实现
3.1 TMS320C6416简介
TM S320C6416是TI公司推出的功能强大的DSP产品,他采用先进的VelociTI结构,将超长指令字VLIW结构和高并行性结合起来,通过增加指令级的并行性使其性能有了较大的飞跃。C6416的最高工作时钟达到1 GHz,指令周期仅为1 ns,最大处理能力可以达到9 000 MIPS,比TMS320C62系列芯片性能高出15倍之多,是当前市场上最先进的定点数字信号处理器。
片内有8个可完全并行运算的功能模块(2个乘法器和6个算术逻辑单元),他们分为相同的两组,属于两个数据通道,每个数据通道与一组32个32位寄存器相连,不同组的两个功能模块之间的数据交换是通过两个寄存器组之间的交叉总线实现。典型片内资源还包括1 MB的片内RAM和一个32位的外部存储器接口,可以支持多类型RAM,包括同步随机访问存储器(SDRAM)和同步突发静态随机存储器SBSRAM等。 DMA控制器包括4个可编程通道和一个辅助通道,能够在内存、片内辅助资源及外部器件之间以CPU的时钟速率实现高速数据传输,这种传输发生在CPU运行后台。CPU和DMA控制器对数据存储器的操作可以按8位字节,16位半字或者32位字的长度进行。
3.2 用DSP实现Turbo译码器的优化措施和技术
TMS320C6416的特殊结构对编译器和软件设计结构提出了很高的要求,软件的设计与优化将成为整个系统性能的决定因素,代码的高度并行性将是获得超强性能的关键。采用流水线技术和功能模块多重化技术是开发处理器的指令级并行性的两个主要手段。C6416对指令获取、指令分配、指令执行、数据存储等阶段进行了多级流水线的划分,不同指令执行的流水延迟也不相等,因此各种指令的安排要尽量不中断指令流水执行,同时,使尽可能多的功能模块并行运行。
由于TMS320C6416芯片的结构对于基于汇编语言的编程过于复杂,这里采用C语言编写主程序。Turbo译码采用并行算法,为提高程序执行效率,充分利用Max-Log-Map译码算法的结构特点,对程序进行寄存器级优化:把Viusal C++实现的浮点算法改为定点算法,将前后向累积路径度量计算的最内层循环展开,合理分配寄存器,使指令中参与运算的寄存器尽量属于同一个数据通道,以减少交叉数据通道冲突,对于访问频繁的变量,置成寄存器型。同时利用功能强大TMS320C6416的C语言编译器和优化器对程序进行全程优化,从而得到效率较高的代码。
4测试结果及性能分析
首先在Visual C++6.0上完成信息比特的产生,Turbo编码和AWGN信道加噪通过DSP的RTDX(Real-Time Data Exchange)技术,把加噪后的信息比特送到TMS320C6416的EVM板上,测试其误码率和完成译码所花费的周期。译码器的许多参数都可以改变,如编码长度,滑动窗大小,归一化门限,迭代次数等。这种灵活性便于满足不同系统的需要,可移植性好。本文系统仿真采用BPSK调制,在AWGN环境下传输,发送端Turbo编码采用约束长度为4,生成矩阵为(15,13)的分量译码器,交织算法为3GPP标准交织算法,译码算法为Max-Log- Map算法。
4.1 不同迭代次数
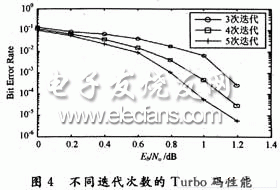
图4为采用1/3码率,交织长度为1 024,迭代3,4,5次,通过AWGN信道时的误码率曲线。从图中可以看到,随着迭代次数的增加,获得的编码增益越高,但增加迭代次数会带来系统延时和增加系统的译码复杂性。仿真充分说明了不同迭代次数对码字纠错性能的改善程度。
4.2 不同的交织长度
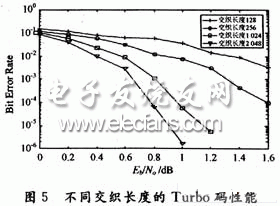
图5采用1/3码率,不同交织长度,5次迭代通过AWGN信道的误码率曲线。从图5仿真结果看,在同样的码率、生成矩阵、交织算法和迭代次数条件下,所取交织长度越长,对码字中各个比特的交织距离就越大,误码率性能就越好,且随着信噪比的增加,误码率性能改善越明显。但交织长度的增加也会带来译码延时的增大和存储量的增加,所以应根据业务的要求来采用不同交织长度。
4.3 不同的码率

图6为1 024交织长度,迭代译码5次,1/2和1/3码率的误码率曲线,从图中可以看出码率越低误码率性能越好,但是随着码率的降低,所需传输的冗余比特也线性增加,对于固定的信息传输率而言,会导致系统的吞吐率降低,需求的带宽增加。
4.4译码处理时间
采用5次迭代译码,1 024交织长度,1/3码率的Max-Log-Map算法在TMS6416EVM板上用CCS软件测试得到所需要的周期数为45 867 356个时钟周期,而TMS320C6416EVM的主频为1 GHz,计算得到所花费的时间大约为4.5 ms,而在3G系统中最小延时为10 ms,所以满足3G系统实时处理的要求。
5结语
本文从译码算法和硬件存储方法对Max-Log-Map算法进行优化,使他在译码性能损失满足要求的情况下,能大大降低算法复杂度,减少运算量和缓存器数量。