
摘 要: 将多模型综合的思想和“变点”思想相结合,给出了一种简单有效且具有普适性的软件可靠性预测方法——基于模糊隶属度的软件可靠性多模型综合预测方法。首先阐述了多模型综合预测问题的一般描述,并介绍了模型评价准则,然后给出了单个模型权重的确定方法和该方法的一般步骤,最后用实际数据验证了方法的有效性及普适性。
关键词: 软件可靠性;模糊隶属度;多模型综合
软件的普遍应用促进人们对其可靠性的关注,到目前为止软件可靠性的研究取得了很大的成果,提出了近百种软件可靠性预测模型,如JM模型、GO模型、NHPP模型、LV模型等,并称此类模型为经典模型。但是单个经典模型存在很大的局限性,对于一个软件可靠性的评估往往很难用一个模型来处理,而且很多软件可靠性模型都是建立在概率分布假设的基础上,这就造成对一个软件有很好的适用性而对其他的软件则效果很差[1]。20世纪90年代以来,基于知识的方法被越来越多地应用到软件可靠性预测中,如神经网络的方法[2-4]、遗传算法、支持向量机、泛函网络等。然而这些方法算法复杂、计算性能较低、其预测结果的精确性取决于神经网络结构的设计和模型的训练。Cai[5]在大量对比实验的基础上指出,大多数情况下,神经网络方法很难得出满意的量化预测结果。
由于单个经典模型的局限性以及基于新理论方法的复杂性和不成熟性,软件可靠性预测仍然还有很多问题需要解决:一是建立能够普遍应用的模型;二是设计一套行之有效的模型选择方法,能够让工程人员从众多的软件可靠性模型中选择出最适合实施项目的模型。
Littlewood B在对大量软件项目研究的基础上提出了“变点”的思想[6],表明不能期望用某一个模型来描述软件的失效过程,而从另一个侧面表明可以用多个模型来描述软件的失效过程。香港中文大学的Lyu Michael提出了多个单一经典模型“综合”的思想[1],并提出了四种线性“综合”的方法,试图找到一种能够普遍适用的软件可靠性预测方法。
本文将多模型综合思想和“变点”思想相结合,提出了一种基于模糊隶属度的软件可靠性多模型综合预测方法,通过各个经典模型的预测数据和实际数据的模糊等于程度来动态地改变单个模型的权重,以综合各个模型的优势,进而更准确地预测软件的可靠性。

2.1.3 单个经典模型权重的计算方法
在进行软件可靠性线性综合模型动态预测时,单个经典模型权重的确定是最重要的。本文给出动态计算单个经典模型权重的方法步骤如下:
(1)在二元信息表的基础上,选择前h个时刻作为基础数据(前h个时刻的实际失效数已知)。
(2)计算前h个时刻每个模型预测失效数和实际失效数的模糊等于程度A(cit)。
(3)计算出各个模型在对h+1时刻软件失效数预测的重要度(即权值)Wci:

(5)当实际测得t+1时刻的失效数d′t+1后,二元关系表指针下移一位(即t=t+1),返回第三步。
3 综合模型评价
对软件可靠性模型预测性能进行评价最主要的是模型的有效性,它可以用定量的方法来测量。本文采用的评价标准如下:
(1)平均误差AE(Average Error)[7]:在整个测试阶段模型预测的误差均值,只能针对同一数据进行比较。平均误差越小,模型的预测效果越好。
(2)平均偏差AB(Average Bias error)[7]:在整个测试阶段模型预测总的偏差趋势。平均偏差越接近于零,模型的预测效果越好。
(3)均方根误差RMSE(Root Mean Square Error)[1]:在整个测试阶段模型预测值和实际值距离。均方根误差值越小,模型的拟合度越高,预测性能越好。
4 实验分析
4.1 实验1
选取UDIMM(University of Denmark Informatics and Mathematical Modeling)提供的数据包[8]中一软件失效数据作为实例进行预测分析。根据Lyu所提出的几个经典模型选择原则,选用JM、GO、LV、YO四个经典模型。其中,JM模型是马尔可夫过程模型,GO模型和YO模型都是经典的非齐次泊松过程模型,LV模型是贝叶斯模型,它们都有很好的预测效果并且应用比较广泛。四个模型预测偏好的综合正好可以相互抵消,GO、LV模型的预测结果比较乐观,而JM模型和YO模型的预测结果则有悲观也有乐观。
设固定窗口h=4,即采用前4个时刻各个经典模型的预测失效数和实际失效数建立二元关系表。使用基于模糊隶属度的软件可靠性多模型动态综合预测方法步骤进行计算,隶属函数参数δ=0.25时计算结果如表1所示。
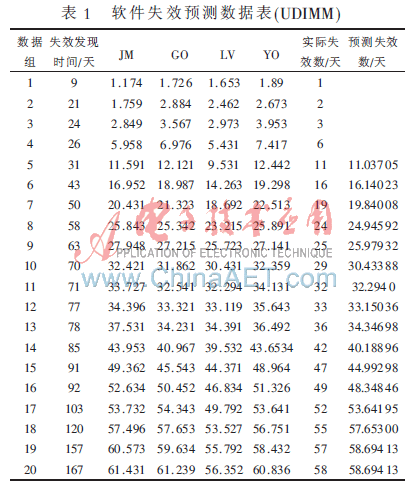
从表1可以看出,该失效数据存在“变点”的问题,即在第5~第7个时刻,JM和LV模型比较适用;从第7个时刻开始一直到第12个时刻,LV模型比较适用,GO模型次之,此后都没有特别合适的模型。基于模糊隶属度的软件可靠性多模型动态综合预测方法能够动态地对各时刻各分模型的权重进行调整,使得整个测试过程中对失效数的预测都比较准确;而且采用固定窗口滑动步长,能够很好地感知数据的变化,减小了数据噪声。
为了与单个模型的预测性能进行对比,选用平均误差(AE)、平均偏差(AB)、均方根误差(RMSE)作为模型预测性能的评价标准。各个模型评价标准计算结果如表2所示。表中FD模型即是本文提出的基于模糊隶属度的软件可靠性多模型动态综合预测方法。

从表2可以看出,FD模型的绝大多数评价标准值都比单个模型的好,只有δ=0.5的FD模型预测结果的均方根误差较大,说明FD模型比单个经典模型有更好的预测性能。δ=0.25时,FD模型的三个评价标准取值比δ=0.5时好很多,也更合理;说明δ=0.25时隶属函数能够更好地描述模糊等于这个概念,更能反映客观实际情况,即是把更大的权重分配给预测值更贴近实际失效数的模型。当δ过于小时,综合预测时会过于偏重某一个经典模型,不能够达到综合多个模型优势的效果。
4.2 实验2
为了与Lyu提出的动态权重的线性综合模型(DLC)进行比较,选取Musa发表的DACS数据集合中的一组失效数据(SYS1)[8]和Lyu提供的一组软件项目失效数据(LDATA)[9]进行试验。同样选用Lyu选择的三个经典模型:GO模型、MO模型、LV模型,固定窗口h=4,隶属函数参数取0.25。分别用两种方法对两组数据进行预测,并对模型预测性能进行评价。两种方法的评价标准计算结果如表3所示。

从表3可以看出,本文的FD模型在各个标准下都优于DLC模型。这主要是因为DLC模型是根据模型的累积预测精确度来动态确定权重,这样平滑了预测时刻以前所有的基础数据,不能很好地反映“变点”的思想;而FD模型采用固定窗口滑动步长来动态确定权重,能够敏锐地感知数据的变化,及时调整权重,又不至于平滑过量的基础数据,从而取得更好的预测效果。
本文提出的基于模糊隶属度的软件可靠性多模型动态综合预测方法结合“变点”思想,采用模糊隶属的方法来动态确定单个模型在综合预测时的权重,以期获得更准确的预测效果。从实验可以看出,该方法不但比单个经典模型有更高的预测精度和更好的预测效果,而且比Lyu提出的线性综合模型更能反映动态反应软件失效数据中“变点”的问题,有更高的预测精度和更好的预测效果。该方法对多个软件项目具有普适性,而且简单有效,在一定程度上解决了一个模型只对某个软件工程项目或者其中某一段时间能够达到较高的预测水平的问题。
参考文献
[1] LYU M R, NIKORA A. Applying reliability models more effectively[J]. IEEE Software, 1992, 9(4):43-52.
[2] KARUNANITHI N, WHITLEY D, MALAIYA Y K. Using neural networks in reliability prediction[J]. IEEE Software, 1992, 9(4):53-59.
[3] SITTE R. Compareson of software-reliability-growth predictions: neural networks vs parametric-recalibration[J]. IEEE Trasactions on Reliability, 1999, 48(3):285-291.
[4] Su Yushen, Huang Chinyu. Neural-network-based approaches for software reliability estimation using dynamic weighted combinational models[J]. Journal of Systems and Software, 2007, 80(4):606-615.
[5] CAI K Y, CAI L, Wang Weidong, et al. On the neural network approach in software reliability modeling[J]. The Journal of Systems and Software, 2001, 58(1):47-62.
[6] PHAME H. Reliability handbook[S]. NewYork: Springer Verlag, 2002.
[7] MALAIYA Y K, KARUNANITHI N. Predictability measures for software reliability models[C]. Fourteenth Annual International Computer Software and Applications Conference,
1990COMPSAC 90. 1990, 1:7-12.
[8] VLADICESCU F P. Performance evaluation of computers courses technical, University of Denmark Informatics and Mathematical Modeling. http://www.imm.dut.dk/popentiu/pec/pec.html.(2009-04-06).
[9] LYU M R, NIKORA A. CASRE-A computer-aided software reliability estimation tool[C]. Computer-Aided Software Engineering Proceedings. 1992:264-275.