
改进的k-means算法在客户细分中的应用研究
2009-08-05
作者:易 珺1,路 璐2,曹 东
摘 要: 针对k-means算法在处理大数据集时间开销较大的弊端,提出一种改进的k-means算法。在计算和比较样本点间的距离时,借用三角形中两边之和大于第三边的定律进行改进,提高了算法的执行效率。
关键词: k-means 客户关系管理 客户细分
在当今信息技术时代,客户关系管理CRM(Customer Relationship Management)的应用得到快速发展,客户细分在CRM中担当越来越重要的角色[1]。
在大众营销时代,企业对客户的划分比较简单,如分为大中型企业、小型企业、个人用户等。随着精准化营销、一对一销售时代的来临,客户细分的方法就需要多样化,营销活动要求对客户进行更为细致的分层。在建立和完善以客户为中心的营销体系的同时,最为重要且最为紧迫的就是对客户细分,以便对不同价值的客户实行差别服务[2]。
在客户细分中采用的主要技术是数据挖掘中的分类和聚类技术。面对越来越庞大的客户数据,利用传统的k-means算法进行细分时,存在着处理大数据集时间开销较大的不足。本文进行分析后提出对k-means算法的改进,实现了客户快速、准确的细分方法。
1 客户细分模型
客户数据库中一般采用三个主要要素作为客户价值分析的重要指标:最近一次消费R(Recency)、消费频率F(Frequency)和消费金额M(Monetary)[3]。
最近一次消费R指客户最近一次购买产品或服务离现在有多长时间。理论上,距离上一次消费时间越近的客户应该是比较忠诚的;最近才购买商品或服务的消费者,是最有可能再次购买的客户。吸引一个几个月前才光顾的客户,比吸引一个一年多以前来过的客户要容易得多。
消费频率F是客户在特定期间内购买的次数。一般认为,最常购买的客户也是满意度最高的客户。增加客户购买的次数意味着从竞争对手处抢占了更多的市场占有率。
消费金额M是客户的所有消费金额,是所有数据库报告的支柱。
按照最近一次消费R、消费频率F、消费金额M这三要素建立RFM模型,是分析客户价值最重要且最容易的方法,能实现对客户间差异的准确理解。
2 k-means算法及改进
2.1 k-means算法基本思想
k-means是数据挖掘技术中的一种基于划分的聚类算法,因其理论上可靠、算法简单、收敛速度快而被广泛使用[4]。
k-means算法的目标是根据输入参数k,将数据集划分成k个簇。算法采用迭代更新方法:在每一轮中,依据k个聚类中心将其周围的点分别组成k个簇,而每个簇的质心(即簇中所有点的平均值,也是几何中心)将被作为下一轮迭代的聚类中心。迭代使得选取的聚类中心越来越接近真实的簇质心,所以聚类效果越来越好。聚类过程如图1所示。

设将d维数据集X={xi|xi∈Rd,i=1,2,……,n}聚集成k个簇w1,w2,……,wk,它们的质心依次为c1,c2,……ck,其中 ni是簇wi中数据点的个数。采用误差平方和准则函数作为目标函数来显式地判断算法是否结束,如公式(1)。利用误差平方和准则函数能把真正属于同一类的样本聚合成一个类型的子集,而把不同类的样本分开[5]。
ni是簇wi中数据点的个数。采用误差平方和准则函数作为目标函数来显式地判断算法是否结束,如公式(1)。利用误差平方和准则函数能把真正属于同一类的样本聚合成一个类型的子集,而把不同类的样本分开[5]。
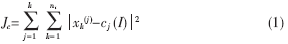
当准则函数Jc收敛后,算法结束。k-means算法步骤描述如下(称为k-means_1):
(1)给定大小为n的数据集X,令I=1,选取k个初始聚类中心cj(I),j=1,2,3,……,k。
(2)以cj(I)为参照点对X进行划分,计算每个样本数据对象与聚类中心的距离。若d(xi,ck(I))=min{d(xi,cj(I)),i=1,2,……n},其中j=1,2,……,k,i=1,2,……n,则将xi划分到簇wk。
(3)令I=I+1,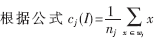 计算新的聚类中心和误差平方和准则函数的值
计算新的聚类中心和误差平方和准则函数的值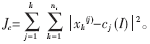
(4)若|Jc(I+1)
2.2 改进的k-means算法
在上述k-means算法中,一次迭代内把每一个数据对象分到离它最近的聚类中心所在类,这个过程的时间复杂度为O(nkd)。n指的是总的数据对象的个数,k是指定的聚类数,d是数据对象的维数。新的分类产生以后需要计算新的聚类中心,这个过程的时间复杂度为O(nd)。因此,这个算法一次迭代需要的总时间复杂度为O(nkd)。如果数据量比较大,算法的时间开销也是相当可观的[6]。
针对处理大数据量时开支大的不足,本文提出了一种借用三角形三边不等定律的思想,即三角形两边之和大于第三边的定律,减少每次迭代的计算次数的改进k-means算法。
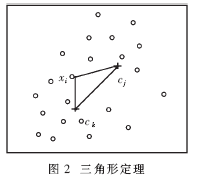 在k-means算法的第一个循环阶段,每次迭代中要计算每一个样本数据到各个聚类中心的距离,依次比较得到与之距离最小的一个类中心,并被分配到这个类中。如果能找到一个方法,避免一些不必要的比较和距离计算,就能节省运行的时间开支。在k-means算法中采用的是欧几里德距离,因此可以考虑借用几何三角形中三边关系定理:两边之和大于第三边,从而简化计算比较过程。
在k-means算法的第一个循环阶段,每次迭代中要计算每一个样本数据到各个聚类中心的距离,依次比较得到与之距离最小的一个类中心,并被分配到这个类中。如果能找到一个方法,避免一些不必要的比较和距离计算,就能节省运行的时间开支。在k-means算法中采用的是欧几里德距离,因此可以考虑借用几何三角形中三边关系定理:两边之和大于第三边,从而简化计算比较过程。
令xi∈X,d(ck,cj)为二个聚类中心的距离,d(ck,cj)、d(xi,ck)与d(xi,cj)三边构成了一个如图2所示的三角形。
则有d(ck,cj)≤d(xi,ck)+d(xi,cj)
即:d(ck,cj)-d(xi,ck)≤d(xi,cj)
如果d(ck,cj)≥2d(xi,ck),则有:d(xi,ck)≤d(xi,cj),即xi到中心cj的距离比到ck的距离大。因此在d(ck,cj)≥2d(xi,ck)的前提下,就不必计算d(xi,cj)了。k-means算法的演变如下所示(称为k-means_2):
(1)给定大小为n的数据集X,令I=1,选取k个初始聚类中心cj(I),j=1,2,3,……,k。
(2)计算每两个聚类中心间的距离d(ci(I),cj(I)),其中i=1,2,……,k,j=1,2,……,k。
(3)设xi当前所在类为wm,计算xi与wm类中心的距离d(xi,cm(I)),若d(cm(I),cj(I))≥2d((xi,cm(I))不成立,则计算d(xi,cj(I));若d(xi,cj(I))<d(xi,cm(I)),则暂时将xi分配到wj,返回(3)循环运行,最终将xi划分到簇wm中。其中j=1,2,……,k,i=1,2,……n,m=1,2,……n。
(4)令I=I+1, 计算新的聚类中心和误差平方和准则函数的值
计算新的聚类中心和误差平方和准则函数的值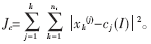
(5)若|Jc(I+1)
这里对算法k-means_1和k-means_2作一个比较。在第二个循环阶段重新计算聚类中心时,这二个算法的时间复杂度是相同的。但是在第一个循环阶段指定聚类簇时,改进的k-means_2算法显然减少了计算量。先考虑一个样本点的情况。在k-means_1算法中,计算样本点到各中心点的距离的次数是k次,而k-means_2算法中,在最好情况下计算样本点到各中心点的距离的次数是1次,最坏情况下计算样本点到各中心点的距离的次数是k次。假设α为第一循环阶段一次迭代时一个样本点的平均计算次数,则有α
如上所述,本文采用改进的k-means算法对某酒店的现有客户群进行细分,建立了RFM模型。根据酒店用户的要求,分别把R、F、M三个要素划分为3个等级,结合这三个指标,可以把客户分成9个等级,也就是聚类成9个簇。
实现聚类算法的主要数据结构如下:
(1)记录一个簇的信息
Public Structure clusterlist
Dim Mean As Double′簇均值
Dim ClusterNum As Integer′簇中记录数
Dim CluserId As Integer′簇号
Dim SquareError As Double′簇中平方误差和
End Structure
(2)记录一个簇中所有记录的关键字
Public Structure recordnum
Dim culsterid As Integer ′簇号
Dim recordid As ArrayList ′记录关键字
End Structure
(3)记录各个聚类中心间的距离
Dim mean_dist(,)as double ′用二维数组记录中心间的两两距离
实现聚类算法的主要函数有:
(1)init_mean( ):设定初始聚类中心。
(2)calc_mean_eucli( ):计算各中心间的欧几里德距离。
(3)calc_sam_eucli( ):计算各个样本点到中心欧几里德距离。
(4)calc_euclidean( ):计算二个点间的欧几里德距离公式。
(5)find_cluster( ):找到离样本点最近距离的簇,并分配样本点到该簇。
(6)calc_new_mean( ):一次划分后计算新的聚类中心。
(7)calc_Jc( ):计算误差平方和准则函数。
(8)kmeans( ):运行k-means算法,若不满足算法结束条件则递归调用。
(9)show_cluster( ):展示一个簇内的客户数据。
聚类算法实现界面如图3所示,用户首先要输入允许的误差准则和聚类要生成的簇数。

4 结 论
K-means是一种基于划分的聚类算法,有着广泛的应用,但其存在着处理大数据集的时间开销较大的不足。本文对该算法进行改进,用以提高运行效率。客户细分是信息时代企业自身发展的需要,在当今客户数据量越来越大的情况下,利用该k-means算法,可以对客户数据进行分析,快速、有效地实现对客户的细分,为企业提供准确的决策支持,提高营销政策的针对性和有效性,提高企业的效益和竞争力。该算法的改进思想也可以为其他领域聚类分析提供参考。
参考文献
1 何荣勤.CRM原理.设计.实践.北京:电子工业出版社,2003
2 谢寰红.数据挖掘在证券公司CRM客户细分中的应用.计算机工程,2004;(30)
3 Bult J R,Wansbeek T.Optimal selection for direct mail.Marketing Science,1997;14(4)
4 Han J W,Kamber M.Data Mining:Concepts and Techniques.San Francisco:Morgan Kaufmann,2000
5 李金宗.模式识别导论.北京:高等教育出版社,1994
6 Moore A W.The anchors hierarchy:Using the triangle inequality to survive high dimensional data.In:Proc. UAI2000:The Sixteenth Conference on Uncertainty in Artificial Intelligence,2000