
一、引言
当今许多电信公司正密切关注着他们所致力的3G产品的研制和开发,例如移动终端、基站以及其它大量的网络设备。无可置疑地,3G产品和业务已经成为无线通信市场的主流,而其中CDMA,尤其是宽带CDMA(W-CDMA)凭借着其高性能、在系统容量运用中的高效性以及物理资源使用中的便捷性,日益成为3G技术中的主导。
为了满足3G的高技术复杂度以及高信号处理要求,基于FPGA/ASIC的专用硬件必须要符合不同用户产品的规格。也就是说,在3G无线终端发展中,产品的尺寸、重量以及功率消耗这些参数将是十分关键和重要的决定因素。由此,系统芯片(SoC)作为一门新的设计方略被引入了3G的发展。SoC要求能够将区域有效信号处理算法与结构的设计、发展都集成在一块小的芯片上。
数字滤波器作为信号处理中最为常见的元件,被广泛地应用于无线通信的各个部分中。本文针对3G标准CDMA 2000中的脉冲成形FIR滤波器的ASIC实现进行讨论,并在此提出一种实效的实现结构:基于分布式运算(DA)结构的查表法。
二、脉冲成形滤波器
脉冲成形滤波器常用于旨在提高信号频谱传输效率的基带通信传输中。经过D/A转换后的成形滤波器通常是被设计为FIR滤波器,其作用是[1]:将信号的同相(I)和正交(Q)符号转换为模拟的I、Q信号。
一般来说,FIR滤波器是需要有一个升余弦或者是平方根升余弦成形脉冲响应的。这里需要注意的是,成形滤波器的采样速率一般要求比输入的I、Q符号速率要高(通常是其4~8倍)。因此,在此要有一个先于脉冲成形的过采样。图1描述了典型的成形过程,其中过采样通过在连续的输入采样值中插入M-1个零值来实现的。CDMA2000标准中,对1个扩频速率的系统(码片速率=1.2288 MCPS),用48阶对称系数FIR滤波器;对3个扩频速率的系统(码片速率=3×1.2288 MCPS),用108阶的滤波器。由于滤波器运行在4倍码片速率下,因此输入的I、Q符号应该是过采样的4倍,即图1中M=4。
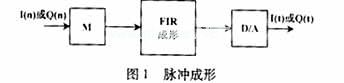

假设FIR滤波器传递函数为H(z),根据十进制/插补理论[2],通过如图2所示对H(z)的多相分解(在图中设M=4),能更有效地完成过采样及滤波器功能。在图2中,Hk(z)表示子滤波器的传递函数,其脉冲响应hk(n)=h(4n+k), n=0,1,…11是由对h(n)抽值得出的。多相结构的优点在于:单个子滤波器是工作在较低的抽样速率上的,而将4个子滤波器相结合后,其系数总值与原来滤波器的H(z)系数相当。也就是说,采用这个方法,整体的计算总量能减少3/4。同时从图2可以看出,这种方法需要用到4个滤波器,因此就硬件的有效性来说,这并不是最理想的。
下面将介绍一种结构,对于ASIC来说它更加得实际、实效,同时也保留了多相分解的优点。
三、分布式运算体系
在分布式运算(DA)运算法则中,滤波器的输出可以表示为
![]()
其中ak是固定的滤波器系数;
xk是输入数据字。
如果将xk表示成B比特的二进制补码,|xk|<1,则有
![]()
其中bki取值为0或是1,bk0是符号位,bk0为1表示数据为负,bk0为0表示数据为正;bk,B-1是最低有效位(LSB)。将(2)式和(1)式合并后,我们可以得到y具体的比特位表达式[3]:
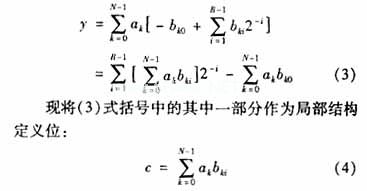
由于bki取值只有0或1, 则(4)式的值有2N种可能性。因此,可以预先算出这2N个局部结果并存放在一个固定的表中(表的宽度为对系数ak定义的宽度,深度为2N),N是能够对数据源抽样数据进行处理的数据长度[3]。然后按照输入的数据,直接对该表寻址并将结果导入累加器中。在B-1次查表之后,累加器的寄存器存储有(3)式第一项所示的结果。最后一个查表给出局部结果 ,也就是(3)式中的第二项,用于表示符号位,并且在寄存器的右移位操作中不包括该项,即将它从寄存器的右移过程中减去。因此,在整个程序中只有在符号位时钟上会使用减法控制。
,也就是(3)式中的第二项,用于表示符号位,并且在寄存器的右移位操作中不包括该项,即将它从寄存器的右移过程中减去。因此,在整个程序中只有在符号位时钟上会使用减法控制。
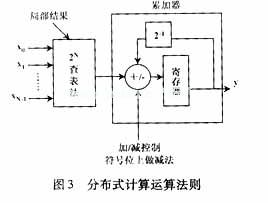
DA运算法则如图3所示。所需的基础操作有:查表排序、加法、减法以及输入数据序列的移位。运用DA结构的前提是:输入抽样值必须要表示为2个补码并将其转换成一个比特串行形式。总共需要有N个B比特的移位寄存器,每个寄存器在一个时钟周期下产生1比特来生成一个用于查找表(LUT)地址(N比特宽)。LUT存储了所有滤波器系数状态可能的局部结果,这些局部结果在寄存器中进行加权(每个周期除以2)和累加,直到每个移位寄存器的最后一位为止。
由于脉冲成形滤波器有着对称的冲击响应,因此先把使用同一个脉冲响应系数的2个输入取样值进行相加,然后相继地把N/2个加法器的输出结果送入DA进行处理,如图4[4]所示。所以,LUT的个数也就从2N个减少到了2N/2个。
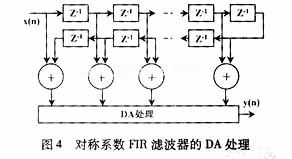
图5所示为通用的FIR成形滤波器结构框图。比较图4与图5后可以看出,运用DA结构可以在程序的编写过程中大量减少乘法运算,而乘法运算在硬件程序中往往是占用资源最大的部分之一。运用DA处理结构能大大减少硬件资源,并在很大程度上提高程序运算速度。

为了进一步减小LUT的个数,现在在过采样中引入零抽样值。设u(n)为过采样程序块的输出序列:
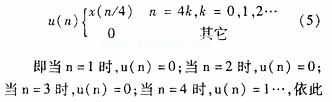
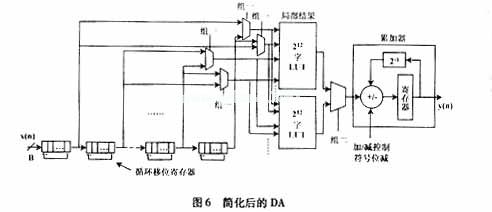
类推,应用u(n)后,48个抽头中的36个采样值将给定为零,这样就有一半的加法器输入为零采样值,并在每个时钟将零采样值传递到对应的乘法器。而另一半加法器的输入值中也只有一个是非零采样值。这样一来,在第一级就能减少24个加法器和一半的乘法器,也就意味着运算出一个输出采样值只需调用一半的滤波器系数。对一个码片速率输入采样值x(n)来说,经过运算得出4个输出采样:y(n)、y(n+1)、y(n+2)以及y(n+3),其中y(n)和y(n+3)需要调用的系数(组一)如下:h(0)、h(3)、h(4)、h(7)、h(8)、h(11)、h(12)、h(15)、h(16)、h(19)、h(20)、h(23);而y(n+1)和y(n+2)需要调用的系数(组二):h(1)、h(2)、h(5)、h(6)、h(9)、h(10)、h(13)、h(14)、h(17)、h(21)、h(22)。这样就可以完成如图6所示的实效DA。输入序列即为码片速率采样值,并且输出的数据是码片速率的4倍,每输入一个采样值可以得出4个输出采样值,内部时钟速率为4×B×码片速率。DA运行中,常用电路移位寄存器(CSR)来代替一个移位寄存器保存数据,直到每个芯片间隔运算出最后的输出采样值为止。一旦输入一个新的采样值,这些CSR就要更新一次。在芯片的持续时间中一共有4个循环,每个循环经历B个时钟并产生一个输出采样值。一个循环过后,CSR移位回归到初始数据,为下一个循环处理做准备,以生成另一个输出采样值。图6中的2个LUT分别存储了两组滤波器系数各自生成的局部结果。选择器是用来决定在每个循环中选择这两组输入分支的哪一组的,其中当高位LUT的结果在循环1和2输出,低位LUT结果在循环3和4输出的时候选择组一;当高位LUT的结果在循环1和4输出,低位LUT的结果在循环2和3输出的时候选择组二。累加器的寄存器在每个循环的起始都要进行清零。
四、设计
现设计一个1比特输入、14比特输出的平方根升余弦滚降线性相位FIR数字滤波器,滚降系数为0.22,带外衰减要求大于45 dB,即通带内(f<8.192MHz)的起伏小于0.5dB,阻带外(f>10 MHz)的衰减大于45dB。在设计中选用了Alter公司的FPGA芯片-EP1K50QC208-3,该芯片有2 880个逻辑单元(LE),40960个片内存储器。本设计占用了387个LE和1088个片内存储器,分别占总资源的1.3%和2%。
经过试验,本结果已经在FPGA中得到了实现。
五、结 论
从试验结果中可以看出,DA实现控制起来比较简单并且时钟速率较低,但是因为LUT的大小会随着滤波器阶数的增加呈指数增长,因此其门的数量也较多。在阶数很大的滤波器中采用并行的FIR结构,每个并行的子滤波器以DA结构实现,这样,控制起来就稍微有点复杂了。因此,如何去克服这方面的缺点还有待于继续研究。