
基于主动队列管理的拥塞控制机制研究
2009-08-24
作者:夏 奕1,邓广宏2
摘 要:提出了一种基于动态阈值的AQM策略DS-RED,主要思想是在缓存中设置一个动态门限控制包的丢失率,使得缓存可以动态地分配给各个数据流,可以根据各个数据流的不同Qos要求,对其进行有区别的服务,以更好地满足网络Qos要求,从而提高网络网络资源的利用率。
关键词:拥塞控制;主动队列管理;丢包率;区分服务
目前,互联网上已经广泛使用TCP滑动窗口进行端到端的拥塞控制。但是,随着网络用户的增加和所承载业务流的多元化,端到端拥塞控制正面临着严峻的挑战。而路由器是互联网的核心实体,也是网络拥塞状态最直接的感受者,因而充分发挥路由器在拥塞控制中的作用也是解决拥塞控制问题的有效思路。而且路由器可能更及时,甚至能够提前了解网络的状态,并依此实施有效的资源管理策略,保证网络能有效地避免拥塞或尽早从严重的拥塞状态中恢复过来。
本文研究的重点是路由器拥塞控制中的队列管理,队列管理通过选择何时丢弃何种业务流分组来控制队列长度。
1 主动队列管理
1.1 Tail Drop
路由器中最常用的队列管理策略是“尾丢弃”(Tail Drop),从拥塞控制的角度分析,它是一种拥塞恢复机制,也是一种被动队列管理。但它有3个严重缺陷:持续的满队列状态;业务流对缓存的死锁;业务流的全局同步。针对这些问题,提出用“首丢弃”和“随机丢弃”对死锁和全局同步比较有效,但没有解决持续的满队列问题。近年来有学者提出主动队列管理AQM(Active Queue Management)[1-2]让路由器在拥塞发生前就采取一些预防措施,使得满队列问题比较有效地得到解决。
AQM策略试图通过估算在某点的拥塞并且在缓冲区满之前通过丢弃数据包来进行标记。相应的拥塞控制策略能够减小它的传输速率。这样可以避免更加严重的拥塞,且试图降低包的丢失率,保持较低的平均队列长度。一个AQM算法由两部分组成:判断拥塞的发生和决定该丢弃哪些包。所以它的性能依赖于是积极的还是保守的判断拥塞的发生,怎样根据判断结果主动地丢弃数据包。
1.2 RED
去尾算法考虑的是拥塞发生后如何恢复,如果在拥塞发生前就采取措施,则可以解决满队列问题。AQM正是设计用来克服网络中的Tail Drop队列的缺点。而RED是最早提出的一种AQM算法。
RED算法是基于拥塞避免的思路,不是等缓存满后再丢弃到达的分组,而是利用标记概率事先丢掉部分分组来预防拥塞的发生。同时,RED 算法不是采用源抑制策略,立刻把反馈信息返回给发送端,而是通过设置标志位提示接收端,再由接收端传递给发送端;而且,RED通过平均队列而非即时队列来调整分组的丢失率,以尽可能地吸收部分短暂的突发流。在队列频繁接近于满缓存时, RED的丢包率明显小于丢尾队列。
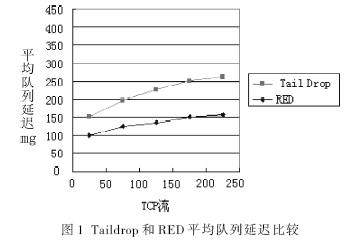
图1所示是对两种算法的仿真曲线图。由结果可以得出:随着流量的增加,两种算法都产生了不同程度上的延迟,且在高负载的情况下,去尾算法由于全局同步而使队列震荡加剧[3-4]。
2 设计方案
RED算法及很多的改进算法,都不能够对不同Qos要求的服务提供有区别的服务,这样就不能很好地保证高服务质量要求的服务。本文中,提出了一种可以实现区分服务的算法DS-RED(Different Serve RED),在缓存中设置一个动态门限来控制包的丢失率,使得缓存可以动态地分配给各个数据流,可以根据各个数据流的不同Qos要求,动态地调整网络资源,从而提高网络网络资源的利用率。可以通过设置一个门限值,然后根据高低优先级包的丢失情况来动态调整这个门限值,使得不同的Qos要求的服务得到有区别的对待,并且高低优先级包丢弃达到一个均衡。使网络资源得到更加充分的利用。
2.1 算法设计目标
(1)拥塞避免与拥塞控制。实验表明要维持网络中的高吞吐量和低延迟,就必须进行拥塞避免;作为拥塞避免失败的补救措施,必须在路由器上实施拥塞控制,以避免网络中拥塞崩溃的发生;
(2)实现各数据流区分服务。在缓存中设置一个动态门限来控制包的丢失率,使得缓存可以动态地分配给各个数据流,可以根据各个数据流的不同Qos要求,动态调整网络资源,从而提高网络资源的利用率,它可以通过设置一个门限值,然后根据高低优先级包的丢失情况来动态调整这个门限值,使得不同的Qos要求的服务得到有区别的对待,并且高低优先级包丢弃达到均衡。
2.2 算法思想
为高、低优先级数据流分别设置丢失计数器ch和cl,每个计数器指定一个丢失增量,例如为kh、kl。当ch每增加kh将会引起门限减少一定值;而cl每增加kl将会引起门限减少一定值。这样如果太多高优先级数据包丢失,增大低优先级数据包丢弃概率的门限值就会减少,以减少低优先级数据包的缓存空间;反过来,如果太多低优先级数据包丢失,门限就会增加。使得高低优先级包丢弃达到一个均衡。使网络资源得到更加充分地利用。
3 与RED算法的性能比较
为了比较RED和新算法的性能,进行网络仿真,仿真使用的网络拓扑结构如图2所示。
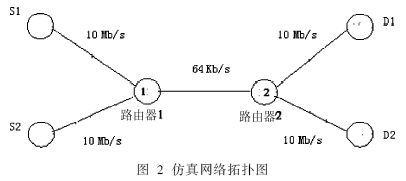
S1和S2为数据发送源端,其中假定S1发送高优先级数据流,S2发送低优先级数据流,D1和D2为接收端。瓶颈链路位于路由器1和2之间,其链路容量为64 kb/s,其余链路的容量为10 Mb/s,各主动队列管理算法设置在路由器1上。仿真时间为20 s,路由器的缓冲区大小为50个数据包。以上介绍的各种算法的参数设置如下:RED基本参数设置为min_th=5, max_th=15, max_p=0.02。对于本文提出的方案DS-RED 参数设置为 min_th=5, max_th=15, max_p=0.2。下面分别采用恒定速率和文件传输FTP的模型对以上的仿真模型进行测试[5-6],仿真结果分别如图3和图4所示。

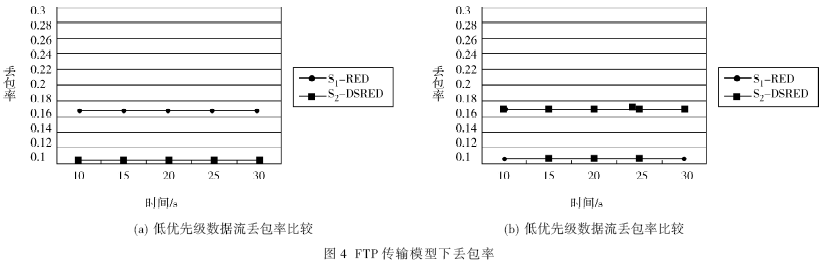
由仿真结果可以看到,在恒定速率下,两种算法的丢弃概率是差不多的,但是在FTP文件传输的情况下,使用改进后的算法高优先级数据包的丢弃概率明显降低,而低优先级数据包丢弃概率相应升高。而改进之前的高优先级数据包的丢弃概率高于低优先级的丢弃概率,改进之后高优先级数据包的概率明显低于丢优先级的数据包的丢弃概率,而且改进后的算法在时间延迟方面也有了明显改善。
如何减少网络中的丢包率,提高链路的利用率,降低传输时延,防止网络崩溃对网络研究来说是很重要的。当数据包在到达接点前就被丢掉或者是链路长时间处于空闲状态或者大量不必要的数据包重传都会造成网络资源的大量浪费。所以网络的拥塞控制的研究也就变得至关重要。
通过MATLAB仿真,将该方法与RED算法进行性能比较,结果表明,改进后的拥塞控制机制能够提供区分服务,更好地满足Qos要求。
参考文献
[1] FLOYD S, JACOBSON V. Random early detection gateways for congestion avoidance. ACM/IEEETransaction on Networking, 1993. (1): 397-413.
[2] BONALD T, BOLOT J. Analytice valuation of RED performance. Proceeding of IEEE INFOCOM, 2000.
[3] 文远保, 石正贵. 无线网络的拥塞控制机制研究[J]. 计算机工程与科学, 2004,26(10).
[4] 任丰原,林闯,刘卫东.网络中的拥塞控制[J].计算机学报,2003,29(9):1025-1034.
[5] MAY M, LYLES B. Reasonsnot to deploy RED. Seventh International Workshop on Quality of Service, 1999.
[6] 罗万明.一种支持多媒体通信的拥塞控制机制[J].电子学报,2000,(11):48-52.