
文献标识码: A
文章编号: 0258-7998(2012)01-0112-03
近年来,在许多领域中出现了多媒体视频自动匹配和识别的需求,同时也出现了很多关于视频处理的方法,涉及医学、电视系统、交通监管系统及网络数据库等领域。随着网络数据库的兴起与发展,视频技术也迅速地普及到网络中来,例如百度、优酷以及美国的“YouTube”等在线视频网站。用户每天都可以通过互联网上传并共享数以万计的网络视频[1],由此引发了网络视频的大量重复和数据库冗余的现象。如何准确快速地匹配这些网络视频,打造一个无重复文本、无资源浪费的绿色网络,对当前的视频匹配技术提出了迫切的要求。
以往的视频匹配多采用基于内容的处理方式,计算量巨大。对于背景动态变化的场景,参考文献[2]利用动态纹理的方法实现视频的登记。该方法通过多角度共同解决这些含糊不清的模型参数,并且用多个视频序列转换识别参数,达到一个标准的形式,降低了在视频登记时出现多个图像配准的问题,从而有效地解决了现有的图像匹配技术。近年来,出现了利用视频序列或者是视频运动轨迹来实现的视频匹配或识别。参考文献[3]提出了一种利用视频图像之间的轨迹进行比对的方法,利用视频序列运动轨迹所得到的稀疏矩阵对视频进行的匹配。该方法属于视频匹配中一个新的领域,具有良好的实用性和精确度。
参考文献[4]提出一种基于多维缩放的算法,能从不同修改程度的视频中得到一个具有鲁棒性特征的序列。但是这个方法对底层特征有巨大改变的视频存在一定的缺陷,同时也会产生一些误差。本文提出一种基于镜头模型和多维缩放方法的视频内容描述框架以及匹配方法,该方法对于镜头数目较多或者切变较快的视频具有鲁棒性。采用可伸缩镜头算法TS(Telescopic Shot)模型来描述各个镜头与视频处理算法的对应关系,提高了多维缩放方法的准确度及对这类视频的匹配能力。
1 镜头检测技术
视频由一序列镜头组成,而相邻镜头的连接方式是切变和渐变[5]。参考文献[6]减少计算量是根据视频一个镜头中大部分都是镜头内帧,且内容变化小的特点,利用K(K=11)步长滑动窗口和自适应阈值把大部分的镜头内帧去掉,只在剩下的少数候选帧中进行切变和渐变检测。为了提高检测精度,切变则利用步长为1的方法计算镜头帧距离,并对闪光进行排除。渐变采用参考文献[6]提到的迭代方法进行检测。
2 多维缩放算法
多维缩放算法MDS(Multi-Dimensional Scaling)是一种针对多变量分析的降维方法,该方法找到了视频序列在低维空间中的运动轨迹,其核心含义是当视频中距离矩阵改变很大时,低维空间两点之间的距离改变量却很小。而当修改距离矩阵时,对于低维空间的改变影响不大,保证了得到序列的鲁棒性。
3 TS模型描述
对于镜头切换快、数量多的视频,采用多维缩放方法会遇到一些小的误差。尽管大多数误差不足以影响视频匹配的效果,但为了力求更加精确的配准率,本文还是插入了镜头分割的流程。对于整个算法的实现,提出了一种基于TS模型的多维缩放算法的实现,TS基本模型如图1所示。
本文提出的可伸缩式镜头模型成功地解决了两类问题:一是可以减小经过视频匹配得出的视频散列值的误差,使多维缩放方法的鲁棒性更高;二是降低了计算复杂度。在视频哈希序列匹配的前提下,只需对视频的镜头数量进行检测,验证视频切变与渐变的个数是否一致,如果一致则证明此视频和目标视频为同一视频,即匹配成功。该过程无需对全部镜头都做降维等复杂处理,即可达到可伸缩性的目的,大大减少了计算时间和空间的复杂度。其中镜头模型设定的阈值可采用自适应性阈值,以镜头和完整视频帧的比率自动调节,一般最少进行降维处理的镜头个数占完整视频的二分之一。
算法描述如下:
Input
Original video V
Begin
Shot-Boundary Detection
For K=1:N
For N=1: M//M为具体视频的镜头数
MDS

4 基于TS模型的匹配算法的实现
4.1 特征提取
底层特征选取的两个主要需求是不变性和敏感性,即底层特征对图片的旋转和平移等变化具有不变性,而对视频内容变化具有敏感性。文中采用基于像素的亮度变化特征及运动补偿特征计算帧图像的距离,使镜头边界检测方法更高地独立于运动。

(2)将图像分成n块,对其中一块在另一幅待比较图像的n块中找到亮度距离最小的一块,将该最小亮度差值作为该块的距离值,然后把n个距离值累加,即可得到两幅图像的距离。本文则对每帧视频图像进行8×8分块的离散余弦变换(DCT),并在输出的zigzag阵列中对DCT系数进行标记,选取最中间的40%的DCT系数取平均值,这样既避免了采用片面的系数值达不到准确反映视频变化的要求,又可以把一些不稳定的距离因素排除,实现鲁棒性。
4.2 镜头分割
采用参考文献[6]中的镜头边界检测视频中的渐变帧和切变帧。对于候选片段集S,根据切变的特点,利用本文提出的新的距离计算方法和自适应阈值来判定是否是切变,及其所在的帧位置,并进行一次闪光排除过程,以排除闪光造成的误检。
对于镜头的伸缩式阈值P的设定,采用自适应的阈值,因为不同的视频镜头内容构架不同,所得到的结果也不同。采用自适应镜头阈值,可有效地节省计算时间和空间,如表1所示。

4.3 多维缩放
对于分割完成的镜头序列N0,N1,…,Nm,首先选取第一个镜头N0,此时不需要再对这个镜头进行特征提取,可直接调用此前已经保存的镜头内的亮度距离矩阵dij,对其进行降维处理,如下式:

4.4 伸缩镜头匹配
对于已经完成的n个镜头内的哈希序列匹配,判定是否已经决定匹配,即已经匹配出目标视频。如果没有,则继续对第n+1个镜头进行缩放匹配,直到视频完全匹配为止。再对其余各个镜头进行数量匹配,并对完整视频帧数进行匹配。这两个步骤的计算量相当小,目的是确保在最短的时间内确定目标视频与源视频为同一视频。
5 试验结果与分析
实验中采用50个内容完全不同的视频来训练伸缩式镜头模型。视频长度介于60~40 000帧之间,视频格式为AVI、MPEG-1等。
实验证明,当视频的镜头切换比较频繁时,本文所得结果优于单纯基于多维缩放算法所取得的结果。同等情况下,由于渐变式镜头切换内容变化较少,而切变式镜头是瞬间变化背景内容,因此切变率较高,参考文献[4]得出的哈希序列误差相对多于本文算法。由于各个镜头的帧数不同,平均值又不能很精确地描述哈希序列中的误差和镜头之间的关系,因此本文摒弃普通帧,或是相对变化缓慢的帧,选取两镜头的分界处属于切变的两帧视频图像。分析大量视频得到的结果可以得出一个结论,即对于切变帧的哈希值,如果不做镜头处理,直接将下一个镜头的第一帧和本镜头的最后一帧做距离的运算,则很容易出现不稳定的结果。而利用镜头算法可以将视频切变引起的误差减少到最小。
图3给出了利用本文算法对三种格式的视频匹配与参考文献[4]方法得出的平均误差的比较。其中,视频签名VS(Video Signature)、MPEG-1、AVI代表的是三种视频格式,分别与TS模型相结合,在图中表示为TS-VS、TS-M、TS-A。
从图中可以看出,本文方法所得到的视频哈希序列的误差比参考文献[4]有所减少。当镜头数很少的时候,误差数相差不太明显,但当镜头数很多时,其中切变数对误差的影响较大,渐变数对误差的影响较小。因此,经过镜头分割之后,在切变点的两帧之间的误差有所减少。本文做了大量的实验,分别对带有视频数字签名、压缩的MPEG-1和AVI格式的视频进行了多次验证,并对实验结果进行了平均化处理。结果发现,基于TS镜头模型算法的处理方式对三种格式的视频均有大幅度改进。
TS镜头算法的计算量相对减小了很多,用本文方法丢弃的不必要的距离计算更多,同时也弥补了镜头分割参与到算法中的计算量,计算效率优势更明显。同时,在视频哈希值可匹配的情况下,将镜头调用阈值定为1/2,省去了1/2的视频多维缩放处理的计算量。由于添加了镜头分割的算法,所以计算量高于参考文献[4]计算量的1/2。
图4中列举了各种算法需要的计算时间,其中MDS代表多维缩放算法所得出的运算时间,Shot cuts代表镜头分割算法,而TS-MDS则是本文TS模型和MDS相结合的算法。
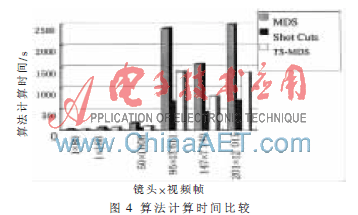
由图4可以看出,各个算法的时间与视频帧数和镜头数之间有着明显的线性关系。由于运行环境不同,得出的计算时间不同,但是同种运行环境得到的结果相似。通过大量的实验发现,镜头数越多的视频,本文方法的优越性就越明显。通过比较,采用单镜头时,本文方法计算时间不如参考文献[4]的MDS方法;而采用多镜头时,镜头分割和TS-MDS方法的计算时间总和比MDS有明显提高。
对于内容变化缓慢的视频,本文方法的检测准确度和返回率与MDS方法相当,对于有较多镜头的视频,或者说是切变较为快速的视频来说,本文方法的配准率高于参考文献[4]所述方法。
本文提出一种基于可伸缩式镜头模型的视频匹配算法,通过视频分割成镜头的方式,在匹配有效的前提下,省去部分镜头的距离矩阵等运算,在一定程度上减少了算法的计算量。通过避开切变前后帧的不稳定差值,从而大大减小了切变引起的哈希值的误差。文中的可伸缩式镜头模型(TS模型)是根据切变对视频散列的影响而提出的,并通过大量实验验证,具有一定的通用性。
参考文献
[1] ESMAEILI M M, FATOURECHI M, WARD R K. A robust and fast video copy detection system using content-based fingerprinting[J].IEEE Transactions on Information Forensics and security, 2011,6(1):213-226.
[2] RAVICHANDRAN A, VIDAL R. Video registration using dynamic Textures[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(1):158-171.
[3] NUNZIATI W, SCLAROFF S,BIMBO A D. Matching trajectories between Video Sequences by Exploiting a Sparse Projective Invariant Representation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010,32(3):517-529.
[4] Nie Xiushan, Liu Ju, SUN J. Robust video hashing for identification based on MDS[R]. Acoustics Speech and Signal Processing (ICASSP), 2010 IEEE International Conference,2010.
[5] 顾家玉,覃团发,陈慧婷.一种基于MPEG-7颜色特征和块运动信息的关键帧提取方法[J]. 广西大学学报:自然科学版, 2010,4(2):310-314.
[6] Qin Tuanfa, Gu Jiayu, Chen Huiting, et al. A fast shotboundary detection based on K-Step slipped window[R].Proceedings of IC-NIDC 2010.