
摘 要: 设计了一种新的基于XML的关系数据映射索引技术,利用域关系树解决了DTD的不足,通过改进的XML Schema算法保持了关系数据间的语义约束,并在映射的XML标签树上建立了RPNL索引,实现了查询代价的最小化O(n)。
关键词: XML语言 关系数据 映射索引
1998年,XML被W3C推荐为Web数据交换的标准,标志着数据库系统进入了XML网络时代。但目前使用最广泛的仍然是关系数据库,因此,关系数据向XML文档的异构映射及其优化索引就成为Internet数据集成技术的焦点之一。通过分析映射索引现状,本文提出了一种新的基于XML的关系数据映射索引技术。针对DTD的不足,在域关系树的基础上设计了一套改进的XML Schema算法,并在映射的XML标签树上构造了RPNL索引,使基于RPNLTree的查询代价降至O(n)。
1 基于XML的关系数据映射技术
目前,对关系模型向XML DTD文档的转换研究比较成熟。但DTD模式保守,数据类型有限,特别是异构过程中完全忽略了关系数据间语义约束的保持,没有做到实体联系的完整性映射。针对上述不足,本文在域关系树的基础上设计了一套改进的基于标准XML Schema的关系数据映射算法。
1.1 域关系树
定义1 域D∷=L{e|D{e,|D}*}。其中,e表示结点;L表示路径;{ }表示域空间。

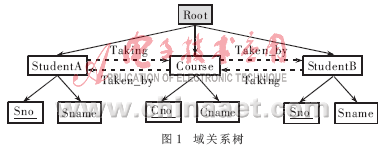
第一层:域根层,有且仅有一个虚根结点Root。
第二层:域表层,由表Student、Course及箭头Taking和Taken_by组成,反映了选课关系。其域关系表达式为:Student.taking![]() Course,Course.taken_by
Course,Course.taken_by![]() Student,Student.taking→Course.taken_by。相应的语义解释为:如果沿着Student边到达结点α并且结点α有Taking边通向结点β,则结点β一定有一条Taken_by边通向结点α。
Student,Student.taking→Course.taken_by。相应的语义解释为:如果沿着Student边到达结点α并且结点α有Taking边通向结点β,则结点β一定有一条Taken_by边通向结点α。
第三层:域属性层,每个结点均标识其域表层直接父结点的一个属性。
1.2 基于域关系树的XML Schema映射算法
严格结构化的关系模型向具有明显层次性的XML半结构化模型映射过程中,借助于域关系树的“中间件”作用,极大地简化了异构的处理。算法中XML术语的父/子关系是关系术语的子/父关系。
算法1:以Student为例的算法过程
(1)设置域属性元素。依次为域属性层结点创建域属性元素Ri-AttType及其属性类型。如果值可以取NULL,则令其标识nillable等于ture。
<complextype name=″Student-AttType″>
<sequence>
<ELEMENT name=″Sno″ type=″string″/>
<ELEMENT name=″Sname″ type=″string″ nillable=″ture″/>
</sequence>
</complextype>
(2)设置域表元素。分别为域表层实体创建域表元素Ri-TabType,并令其域空间内的域属性元素类型为xsd:Ri-AttType。同时设置域表元素minOccurs属性为0,maxOccurs属性为unbounded。
<complextype name=″Student-TabType″>
<sequence>
<ELEMENT name=″Student″ type=″xsd:Student-
AttType″ minOccurs=″0″ maxOccurs=″unbounded″/>
</sequence>
</complextype>
(3)创建库元素。首先在XML Schema文档中设置库元素Ri-DB,然后依次添加库表元素Ri-Tab及其域空间内的元素类型xsd:Ri-TabType。
<ELEMENT name=″Student-DB″>
<complextype>
<sequence>
<ELEMENT name=″Student-Tab″ type=″xsd:Student-TabType″/>
</sequence>
</complextype>
(4)设置主/外键。如果域属性层结点是主属性,则要插入主键标识Ri-PriKey。对于域表层实体间的联系则通过设置外键来完成,并指明其参照域xsd:Ri-ForKey。在域空间内,分别为主/外键添加selector xpath和field xpath。
<key name=″Student-PriKey″>
<selector xpath=″xsd:Student-Tab/xsd:Student″/>
<field xpath=″@Sno″/>
</key>
<keyref name=″Course-Cno″ refer=″xsd:Student-ForKey″>
<selector xpath=″xsd:Course-Tab/xsd:Course″/>
<field xpath=″@Cno″/>
</key>
此算法已经在一个网上选课系统中得到了验证,该系统的后台数据库采用Oracle。
2 基于XML的关系数据RPNL索引技术
目前已经提出的XML数据库索引机制有基于Trie树的索引Index Fabric、Stanford大学Lore系统的DataGuides、XISS系统索引方案、基于DOM模型的索引、基于共享根结点的索引Rist、基于结构的Join索引和基于路径的索引等。其中较具代表性的是基于结构的Join索引和基于路径的索引。但这二种方法的不足之处是查询处理代价高于O(n)。因此,本文在XML标签树的基础上设计了RPNL(Reverse Polish Notation Link逆波兰链)索引,将查询代价控制在O(n)。
2.1 XML标签树
图2所示的XML标签树是利用XML Schema的树状层次性,借鉴半结构化模型OEM的表示形式建立的。其构造方法如下:

(1)每一个域属性元素分别对应于XML标签树上的一个结点,带方框的$表示父结点,圆圈表示子结点。
(2)在XML标签树中,元素-元素、元素-属性之间的父-子关系均用相应名字的边来标识。
2.2 基于XML标签树的RPNL索引
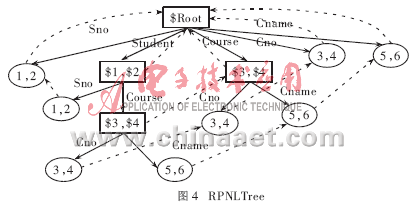
定义3 形如(L1D1L2D2……LnDn)的字符串称为数据路径。(L1L2……Ln)称为语义路径,(D1D2……Dn)称为数据值。其中Li和Di(i=1,2,……n)分别表示标签树的边和结点。
分析图2,结点1、结点2具有相同的语义路径{Student.Sno},结点5、结点6具有相同的语义路径{Student.Course.Cname}……由此可知:XML标签树中存在若干具有不同值但具有相同语义路径的结点,即同一语义路径可对应多个不同的数据值。于是,将具有相同语义路径不同数据值的结点聚合在同一结点中,并在尽可能少的步骤内快速定位到目的结点,便是索引优化的关键技术。本文提出的基于XML标签树的索引,在语义路径上特别设置了结点的RPNL,同时利用Hash表保存索引结点的RPNL指针。实验证明,此方法能够将顺序查找的代价由O(n2)降至加了RPNL索引的O(n)。
定义4 设XML标签树中结点A的数据路径为αβ,其中α为基本单元。若存在结点B的数据路径β,则有一指针自结点A指向结点B,该指针称为结点A的RPNL。
定义5 RPNLTree(逆波兰链索引树)中,聚合在同一结点A内的具有相同语义路径不同数据值的结点集,称为结点A的扩展集。
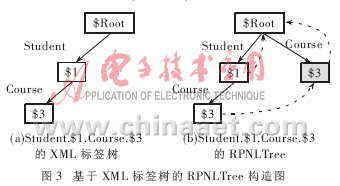
根据定义4、定义5并结合图3(a),给出了在XML标签树上构造RPNL索引(图3(b))的算法,称为算法2。
算法2:在XML标签树上构造RPNL索引
约定: (1)p[i]←Li1Li2……Lin表示结点i的语义路径(i=1,2,……n)。
(2)一层虚根Root的RPNL为NULL,二层子结点的RPNL均指向Root。
Input: TAGTree Output: RPNLTree
算法步骤:
(1)初始化。RPNLTree中有且仅有一个根{$Root},令指针p←RPNLTree.root。
(2)从Root开始前序遍历TAGTree,首先得到边Student及结点{$1},在RPNLTree中创建结点{$1},并使p所指结点Root有一条边Student指向结点{$1}。由于{$1}是根结点的孩子,所以需创建一条由{$1}指向Root的RPNL,最后令指针p指向{$1}。
(3)继续遍历TAGTree,得边Course及结点A(扩展集为{$3}),并使Course自{$1}(由p所指)指向A。
(4)判断p所指结点是否存在RPNL。若存在,则访问RPNL所指结点N(当前是Root),并创建新边Course和新结点B(扩展集为{$3}),使Course自N指向{$3},然后令A的RPNL指向B。
(5)检查N中是否有RPNL指向下一个结点。如果有,使N标记该新结点,依次重复(3)(4),直到没有可以创建RPNL的新结点并且N的RPNL指向根结点,中止遍历所得边和结点(当前是Course和{$3})。
(6)令p指向结点B,即遍历所得当前结点路径(Student.Course)所对应RPNLTree结点。
图4是依据算法2对图2中XML标签树构造的RPNLTree,其中虚线表示当前结点的RPNL。
由定义4、定义5及RPNLTree的构造过程,可得以下引理:
引理1 利用RPNL索引查询语义路径为L1L2……Ln的结点,若存在,则其扩展集即为查询结果。
引理2 从RPNLTree根结点出发,查询长度为n的字符串p,其查询代价为O(n)。
引入RPNL索引技术的关键是:当遍历得到边L及结点A时,只需从p所指的当前结点开始沿着RPNL进行新结点、边的构造,无需进行全程重复查找(根除外),以此来提高查询速度,降低处理代价。
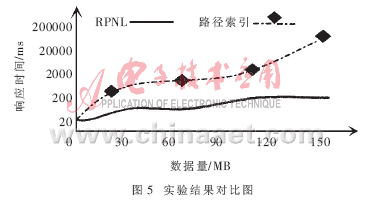
2.3 实验结果
这里选取应用广泛的路径索引[6]作为RPNL索引查询性能的对比分析。实验的硬件环境为:CPU选用Pentium4 2.4,RAM为256MB;软件环境为:操作系统选用Windows XP,数据集为DBLP。图5为实验结果。从图5的趋势曲线可以看出,随着测试数据量的增大,路径索引的查询时间呈指数增长,而RPNL索引的查询时间则基本是线性增长。再由引理1、引理2可证,RPNLTree的查询处理代价为O(n),即在相同条件下,RPNL索引技术的查询效率优于其他索引。限于篇幅,与其他索引实验结果的对比分析省略。
3 总 结
本文设计了一种新的基于XML的关系数据映射索引技术。通过对DTD不足的分析,在保持关系数据语义约束的基础上,提出了一套改进的XML Schema算法,并利用XML文档的层次性,构造了XML标签树,设计了RPNL索引,实现了基于RPNLTree的查询代价最小化O(n)。
参考文献
1 Bourret R.Mapping DTDs to Databases.http://www.xml.com/pub/a/2001/05/09/dtdtodbs.html
2 Goldman R,Widom J.DataGuides:Enabling query formulation and optimization in semistructured databases.In:The 23re VLDB Conf Athens,Greece,1997
3 贾福林,王国仁,于戈.基于DOM的XML数据库的索引技术研究.计算机研究与发展,2004
4 Wang H X,Park S ,Fan W et al.ViST:A Dynamic Index Method for Querying XML Data by Tree Structures.In: proceedings of ACM SIGMOD Conference,San Diego,CA, 2003
5 Srivastava D,Al-Khalifa S,Jagadish H V et al.Structural joins:A primitive for efficient XML query pattern matching.In:Proc of the 18th Int′l Conf on Data Engineering (ICDE′02).San Jose:IEEE Computer Society Press,2002
6 Goldman R,Widom J.DataGuides:Enabling query formulation and optimization in semistructured datavases.In:Proc of the 23rd Int′l Conf on Very Large Databases(VLDB′97). San Francisco:Morgan Kaufmann,1997