
摘 要:提出了可避免数据包重复标记的可变概率分片标记算法。通过模拟试验对比该提出的算法和基本包标记算法,结果表明该方法能够消除对数据包的重复标记问题,并显著地减少反向追踪攻击源所需数据包的数目,提高了对攻击源定位的追踪的准确性和实时性。
关键词:重复标记;可变概率;传输距离
DoS是Denial of Service的简称,即拒绝服务。造成DoS的攻击行为被称为DoS攻击,其目的是通过消耗远程计算机网络资源来使Internet站点拒绝提供给合法用户的服务。这种类型的攻击实施简单、防御困难、危害极大,攻击者的IP地址常常是经过伪装的。针对此类攻击的特点,研究者提出了很多解决方法,例如包标记、日志记录、连接测试、ICMP追踪、覆盖网络等。本文提出了可避免数据包重复标记的可变概率分片标记算法,减少路径重构时所需的数据包数目以及运算时间,提高了对攻击源定位的追踪的准确性和实时性。
1 相关研究工作
由Savage等人提出的概率包标记算法BPPM,具有许多其他方法所不具有的优点:(1)无需与ISP相互合作,避免了调试中高额的管理费用;(2)无需增加巨大的网络流量,可以跟踪多种攻击形式;(3)在攻击停止后很久,仍然可以被用来分析登录过程并制作用于跟踪的数据包。(4)网络路由器负载小。之后在BPPM的基础上不断产生出新的改进算法,例如自适应概率包标记、高级包标记和带认证的包标记,以期减少路径重构时所需的数据包,重构攻击路径时的误报率,计算复杂度(时间复杂度)。
概率包标记的思想[1]是路由器以固定的概率p标记数据包,将路径信息加入到IP头中的16 bit识别域(ID)中,表示为(start,end,distance)。在路由器处产生一个[0,1]之间的随机数,如果这个随机数小于p,路由器将自己的IP填入到start,同时将distance赋值为0;否则将自己的IP地址填入到end中;如果路由器以概率1-p不对包标记,则将distance值加1。受害者从这些数据包中提出路径信息,重构出攻击路径。
假设每个路由器标记数据包的概率为p,受害者从距离d(节点与受害者间路由器的个数)的路由器收集到被标记的数据包的概率为p(1-p)1-d。该函数是距离d的严格单调递减函数,距离攻击者越远的路由器的样本越难被采集到,因此算法的时间主要集中在接收最远路由器提供样本的时间上。例如,当d=20、P=1/2时,受害者要收集到此路由器上的样本必须要收到平均1 048 576个数据包。
它最主要的缺点是随着路径的增长,所需要数据包的数量成指数增长,并且存在数据包的重复标记问题,距离攻击者近的被标记的数据包可能被下边的路由器标记,从而掩盖曾经被标记过的信息,这就不可能很快地重构路径防御攻击。
2 改进的包标记算法NRVPPM
本论文提出一种改进的包标记算法,在包头中增加标记位flags来避免数据包的重复标记问题,并且使用等概率p=1/di,使受害者主机可等概率地收集到攻击路径中路由器标记的数据包。
2.1标记概率

2.2标记格式
为了节省标记存储空间,不给用户带来过多的影响,算法使用IPv4中的16位标识符字段(Identifer)[1]、1位闲置的标志位(Flags)、13位片位移字段(据统计目前少于0.25%的数据包需要分片)[3],以及一般很少使用的8位TOS(Type-of-Sevice),总共38位来存储包标记信息。标记格式如表1所示。

把32位的start路由器的IP地址和32位end路由器地址分为4块。在start和end子域以等概率放置IP地址的4个8 位的片段,并相应地设置偏移offset子域值。
(1)flgs:如果flags=0,则表示数据包没有被标记过;flags=1,则start子域已被标记过;flags=2,则start、end子域均被标记过。flgs的初始位被置为0。
(2)start和end:用来存储边的信息。
(3)distance: 用5位的distance来记录数据包开始发送的路由器开始经过的跳数。distance的初始值被置为0。
(4)offest:用2位来记录start和end的4个偏移。
(5)hash:hash(IP)取其后13位。
2.3 标记过程
把32位的start路由器的IP地址和32位end路由器地址分为4块,在start和end子域以等概率放置IP地址的4个8 bit的片段,并相应地设置偏移offset子域值。路由器以概率p=1/d对数据包w进行标记。在路由器Ri 处,让x为[0,1]之间的随机数,y为[0,3]之间的随机数,如果x<p,(a)当flags=0时,则把路由器Ri 的IP地址的第y个分片放入start域,distance域置为0;(b)当flags=1时,则表明start域已经标记过,把路由器Ri 的IP地址的第w.offset个分片放入end域,flags的值加1。如果flags=2,则表明数据包w的start、end域均已经标记过,直接将distance的值加1,转发数据包。
标记算法[4]为:

2.4 重构过程
攻击路径重构的目标是建立一棵包含所有攻击路径拓扑信息的树T, 重构的第一步是建立一个只包含根节点V的树T。第二步根据每个节点与受害主机V的距离,把采样到的边插入到树的结构之中,离各个攻击源最近的路由器就是树的各个叶子,最后检查整棵树,删去与节点的距离d不等于distance的节点。该算法参考了参考文献[4]。
重构算法为:
Algorithm 2. Reconstruction procedure at v
let T be a tree with root v
let an edge of T be a tuple (start,end,count)
let E be a two dimension array of the tuples
for each packet w
replace the fragment at offset w.offset of
E[w.distance][w.hash].start with w.start
Replace the fragment at offset w.offset of
E[W.distance][w.hash].end with w.end
increment E[w.distance][w.hash].count
end for
3 仿真试验
为了测试本文方案的性能,通过模拟实验比较了2种方案在路径重构时所需要的数据包的数目,实验数据利用CAIDA[5](Cooperrative Association for Internet Data Analysis)提供的跟踪路由数据库进行仿真攻击试验,如图1所示,选取的攻击路径长度为1~30,每个长度进行1 000次试验取平均值。
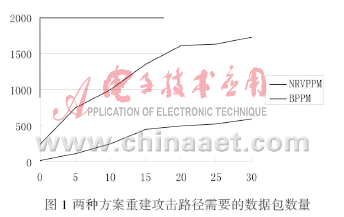
图1横坐标为路径长度,纵坐标为重构路径时所需的数据包数目。从图1可以看出,在重构路径时,本方案重组攻击路径所需的攻击数据包的数量随着攻击路径长度的增加而增加,但增加的速度却随着路径长度的增加逐渐减小,与传统的标记方法相比,传输路径越长,本方案所需的数据包的个数就越具有优势。因为需要的数据包数量比基本包标记少得多,计算量也会大大减少。所以本方案只需要少量数据包就可以在短时间内重构出攻击路径。
追踪攻击源是打击网络犯罪的必经阶段,它不仅是查找攻击者的重要手段,而且对提供网络犯罪的证据也具有非常重要的作用,所以攻击源追踪技术引起了越来越多的重视。本文提出的算法能够消除对数据包的重复标记问题,并显著地减少反向追踪攻击源所需数据包的数目,提高了对攻击源定位的追踪准确性和实时性。但是要追踪到真正的攻击者,还有许多亟待解决的问题。例如攻击源追踪只能得到可疑攻击路径的集合、只能是近似的回溯、以及如何减少错误路径还需要进一步的研究。
参考文献
[1] SAVAGE S, WETHERALL D,KARLIN A, et al. Network support for IPtraceback[J]. ACM/IEEE Transactions on Networking,2001,9(3):226-237.
[2] 胡汗平,王凌斐,郭文轩,等.一次性可变概率分片标记及其压缩标记[J].华中科技大学学报:(自然科学版),2007,35(3):15-18.
[3] RICHARD S W,著.TCP/IP详解—卷1:协议[M].范建华,胥光辉,张清,等译.北京:机械工业出版社.2000.
[4] 梁丰,赵建新,DAVID Y.通过自适应随机数据包标记实现实 时IP回溯[J].软件学报,2003,14(05):1000-9825.
[5] DAVID M. CAIDA cooperrative association for internet data analysis[EB/OL].http://www.caida.org.2004.