
摘 要: 针对初始聚类中心对传统K-means算法的聚类结果有较大影响的问题,提出一种依据样本点类内距离动态调整中心点类间距离的初始聚类中心选取方法,由此得到的初始聚类中心点尽可能分散且具代表性,能有效避免K-means算法陷入局部最优。通过UCI数据集上的数据对改进算法进行实验,结果表明改进的算法提高了聚类的准确性。
关键词: K-means;聚类算法;初始聚类中心;动态聚类
聚类分析[1]是基于数据集客观存在着若干个自然类,每个自然类中的数据的某些属性都具有较强的相似性而建立的一种数据描述方法。因而可以讲,聚类分析是将给定的一些模式分成若干组,对于多选定的属性或者特征,每组内的各样本模式是相似的,而与其他组的样本模式差别较大。聚类分析有许多具体的算法,从算法策略上看,可以分为如下几种典型方法:(1)根据相似性阈值和最小距离原则的简单聚类方法;(2)谱系聚类算法;(3)近邻函数法;(4)动态聚类法。其他方法基本是由这四种派生而来。
在众多的聚类方法中,动态聚类法中的K-means算法因其方法简单、效率高、结果尚令人满意,因此得到了广泛的应用。但是K-means算法本身存在缺陷和不足,如K值的选取、初始聚类中心的选取以及对噪声敏感等问题。学术界对初始聚类中心的选取提出了多种改进算法,如参考文献[2]提出利用数据样本的近邻点信息确定初始聚类中心的方法;参考文献[3]采用基于密度的思想,将不重复的核心点作为初始聚类中心;参考文献[4]选择包含数据样本最多的K个类中心作为初始聚类中心;黄韬等[5]通过对数据集的多次采样,选取最终较优的初始聚类中心。这些算法提高了聚类准确性,但初始中心点的选取未能同时兼顾代表性和分散性的特性。
针对样本点之间的近类内、远类间的分布特性,本文提出一种依据类内距离动态调整中心点类间距离的初始聚类中心选取方法,得到的初始聚类中心能尽量分散,很好地代表K个簇,并且,扫描一遍数据集即可完成初始聚类中心的选取。实验表明,与随机选取初始聚类中心的传统K-means算法相比,该方法提高了聚类的准确率,使得聚类结果更稳定。
1 K-means算法的基本理论
K-means算法有两个阶段,第一个阶段是确定K个中心点,每一类有一个中心点;第二个阶段是把数据集的每个样本点关联到最近的中心点,并由此循环得到新的K个中心点。循环的结果就是中心点位置不断地变动,直到稳定不变,标志着聚类收敛。
设待分类的数据集为{x1,x2,…,xC},聚类的个数为K。算法的具体步骤如下:

在K-means算法中,数据之间的相似度用欧氏距离来衡量,距离越大越不相似,距离越小越相似,两个簇之间数据太密集就会合并为新的聚类簇,而离两个聚类簇稀疏的数据就会形成新的簇。因此如果选取两个簇密集区域的聚类中心的平均值和离簇稀疏的数据作为初始聚类中心,将有利于目标函数的收敛。
由此,本文将依据样本点实际分布情况,利用类内最短距离调整中心点的类间距离,不断更新优化初始聚类中心。基本思路如下:(1)随机选取的K个样本(记为集合L)作为初始中心点,按式(4)计算这K个数据两两之间的最小距离作为初始类间距离limit,设集合R=U-L;(2)按式(4)计算R中任一样本点到L的最短距离t=Dist[ri,L](ri表示R中第i个样本点),如果t大于limit,则删除集合L中最近的两个点,把这两点的中点ri加入到集合L中,更新limit为t。否则,不做任何操作;(3)更新R=R-ri,重复步骤(2),直至R为空。
假设现在有一个二维数据样本集合,含有6个样本点,分成3个聚类簇,如图1所示。

按照本文的算法思想:(1)首先随机选取3个初始点A、C、D构成集合L,按式(4)计算这3个数据两两之间的最小距离作为初始阈值limit,设集合R=U-L={B、E、F};(2)按式(4)计算R中任一样本点到L的最短距离t=Dist[B,L],若t大于阈值limit,则删除集合L中最近的两个点C和D,并把这两点的平均值和B加入到集合L中,更新阈值limit为Dist[B,L];(3)更新R=R-B={E、F}。重复步骤(2),直到R为空。最终得到的聚类中心接近于聚类算法期望得到的聚类中心。
由上述动态选取初始聚类中心算法得到的聚类中心作为K-means算法的初始聚类中心,即为改进的动态K-means算法。
改进的动态K-means算法的时间复杂度主要由两部分组成,一部分是生成初始聚类中心的时间,另一部分是迭代所需要的时间。改进的动态K-means算法计算出初始聚类中心需要的时间复杂度为O(K×C×N),其中K为聚类数,C为所有样本数据的个数,N为样本属性。
3 实验与结果分析
为验证改进算法的有效性,本文采用UCI标准数据集中的葡萄酒Wine数据集和鸢尾花Iris数据集。对各数据集的描述如表1所示。

对于表1所描述的数据,本文做对比实验,比较随机选取聚类中心的K-means算法和本文改进的动态K-means算法,分别在Wine和Iris数据集上进行10次试验。本文用随机的方式选取初始中心点,实验结果如表2、表3、图2和图3所示。

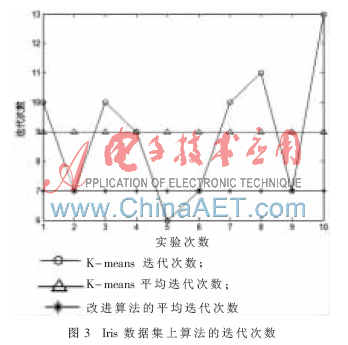
从表2和图2可以看出,在Wine数据集进行10次实验,K-means算法的准确率在53.37%~70.22%之间浮动,平均准确率为62.25%;迭代次数最少5次,最多16次,平均迭代次数为9。由此可见,K-means聚类算法结果不稳定,并且受初始中心点影响很大。本文算法平均准确率为70.34%,平均迭代次数为5。从表3和图3可以看出,在Iris数据集进行10次实验,K-means算法平均准确率为75%,平均迭代次数为9次,本文算法平均准确率为89.47%,平均迭代次数为7次。实验结果表明,本文改进的动态K-means算法选取的初始聚类接近簇中心,收敛速度快,准确率高,聚类效果好。
K-means算法的聚类结果受初始聚类中心影响很大且迭代次数多,本文改进的算法优化了初始聚类中心,有效地提高了收敛速度,提高了聚类的准确率。但本文方法受噪声点影响较大,下一步将对减少噪声点的影响方面进行学习和研究。
参考文献
[1] 孙即祥,姚伟,腾书华.模式识别[M].北京:国防工业出版社,2009.
[2] CAO F Y,LIANG J Y,JIANG G.An initialization method for the K-means algorithm using neighborhood model[J].Computers&Mathematics with Applications,2009,58(3):474-483.
[3] 张琳,陈燕,汲业,等.一种基于密度的K-means算法研究[J].计算机应用研究,2011,28(11):4071-4073.
[4] 张琼,张莹,白清源,等.基于Leader的K均值改进算法[J].福州大学学报,2008,36(4):493-496.
[5] 黄韬,刘胜辉,谭艳娜.基于K-means聚类算法的研究[J].计算机技术与发展,2011,21(7):54-57.