
摘 要: 随着Internet等技术的飞速发展,信息处理已经成为人们获取有用信息不可或缺的工具,如何在海量信息中高效地获得有用信息至关重要,因此自动文本分类技术尤为重要。现有的文本分类算法在时间复杂性和空间复杂性上遇到瓶颈,不能满足人们的需求,为此提出了基于Hadoop分布式平台的TFIDF算法,给出了算法实现的具体流程,通过MapReduce编程实现了该算法,并在单机和集群模式下进行了对比实验,同时与传统串行算法进行了对比。实验证明,使用TFIDF文本分类算法可实现对海量数据的高速有效分类。
关键词: 文本分类;MapReduce;并行化;TFIDF算法
当今信息时代,数据膨胀的速度已远远超过人工分析它们的能力,如何在海量数据中快速地获得所需信息至关重要,因此自动文本分类技术尤为重要。文本分类是指依据文本内容由计算机根据某种自动分类算法,把文本判定为预先定义好的类别[1]。文本分类是数据挖掘的关键技术,为了提高分类质量,首先要实现算法并行化。
近几十年来,一系列统计学习文本分类方法被提出[2],国内外对文本分类算法的研究很多,但大都存在一些局限性,特别是缺乏对海量文本数据的挖掘。云计算的出现为算法并行化带来了新的契机,很多科研人员和机构都在投入研究云计算。Hadoop平台发布以来,很多专业人员致力于利用它对海量数据进行挖掘,目前已经实现了一些基于该平台的算法。本文研究TFIDF文本分类算法,并通过MapReduce编程,在单机和集群模式下研究TFIDF算法的并行化并进行实验验证,并与传统算法进行对比实验, 实验表明,改进的算法提高了分类速度,有效地解决了海量数据的分类问题。
1 TFIDF算法的实现
TFIDF是一种用于资讯检索与资讯探勘的常用加权技术。在某一个特定的文档中,词频(TF)指某一具体给定的词语在这个文档中出现的次数。对于在某一特定文档里的词语ti,其词频可以表示为:

TFIDF算法是有监督的文本分类算法,它的训练集是已标记的文档,并且随着训练集规模的增大,分类效率、精度均显著提高[6]。
2 MapReduce编程模型
分布式文件系统(HDFS)和MapReduce编程模型是Hadoop的主要组成部分。Hadoop是一个能够对大数据进行分布式处理的框架,能够把应用程序分割成许多小的工作单元,并且把这些单元放到任何集群节点上执行[7]。MapReduce模型的计算流程如图1所示。
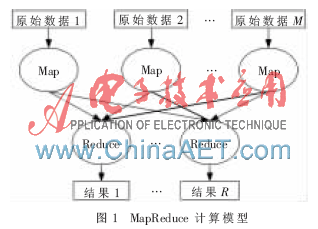
分布式文件系统主要负责各节点上的数据的存储,并实现高吞吐的数据读写。MapReduce计算模型的核心部分是Map和Reduce两个函数[8]。Map的输入是in_key和in_value,指明了Map需要处理的原始数据。Map的输出结果是一组<key,value>对。系统对Map操作的结果进行归类处理。Reduce的输入是(key,[value1… value m])。Reduce的工作是将相同key的value值进行归并处理最终形成(key,final_value)的结果,所有的Reduce结果并在一起就是最终结果。其中HDFS和MapReduce的关系如图2所示。

3 MapReduce编程模型下的TFIDF算法
3.1 TFIDF算法流程
Hadoop分布式计算的核心思想就是任务的分割及并行运行。从TFIDF 的计算公式可看出, 它非常适合分布式计算求解。词频(TF)只与它所在文档的单词总数及它在此文档出现的次数有关。因此,可以通过数据分割, 并行统计出文档中的词频TF,加快计算速度。得到单词词频TF 后,单词权重TFIDF 的计算取决于包含此单词的文档个数。因此,只要能确定包含此单词的文档个数,即能以并行计算的方式实现TFIDF的求解。MapReduce下计算TFIDF 的整个处理流程如图3所示。主要包括统计每份文档中单词的出现次数、统计TF及计算单词的TFIDF值三个步骤。

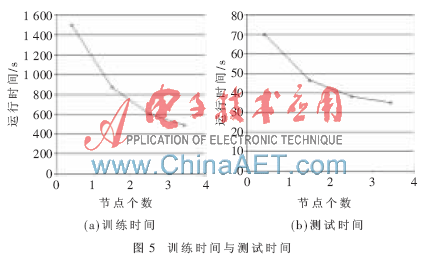
Hadoop对数据进行的是分块处理,并且默认数据块大小为64 MB,所以当存在很多小数据文件时,反而降低了运行速度,因此对小数据集Hadoop的优越性体现得并不明显。但是随着数据集增大,传统算法所需要的时间急剧增长,而应用了Hadoop框架的TFIDF算法所需要的时间只是呈线性增加,表现出了一定的算法优越性。
(3)不同节点数下的对应运行时间
图5(a)和(b)分别显示了Sogou文本分类语料库随着节点数目由1增加到4时的训练时间和测试时间曲线。
本文通过在Hadoop平台下的MapReduce编程,对传统TFIDF算法进行了性能优化,并通过3组对比实验,验证了改进的TFIDF算法可取得更好的分类结果,可以很好地实现对海量数据的高效挖掘。
参考文献
[1] SEBASTIANI F.Text categorization[Z].Encyclopedia of Database Techologies and Applications,2005:683-687.
[2] Yang Yiming.An evaluation of statistical approaches to text categorizationg[J].Journal of Information Retrieval,1999,1(1/2):67-68.
[3] 谢鑫军, 何志均.一种单一表单工作流系统的设计和实现[J].计算机工程,1988,24(9):53-55.
[4] 王宇.基于TFIDF的文本分类算法研究[D].郑州:郑州大学,2006.
[5] 向小军,高阳,商琳,等.基于Hadoop平台的海量文本分类的并行化[J].计算机科学,2011,38(10):190-194.
[6] 搜狐研发中心.Sogou文本分类语料库[OL].(2008-09)[2012-09-30].http://www.sogou.com/labs/dl/c.html.
[7] 刘鹏.实战Hadoop-开启通向云计算的捷径[M].北京:电子工业出版社,2011.
[8] 李彬.基于Hadoop框架的TF- IDF算法改进[J].微型机与应用,2012,31(7):14-16.