
摘 要: 设计了一款具有4级流水线结构的16位RISC嵌入式微处理器。针对转移指令,未采用惯用的延迟转移技术,而是通过在取指阶段增加相应的硬件结构实现了无延迟转移。采用内部前推技术解决了指令执行过程中的数据相关。同时通过设置相应的硬件堆栈实现了对中断嵌套和调用嵌套的支持。整体系统结构采用Verilog HDL语言设计,指令系统较完善。在软件平台上的仿真验证初步表明了本设计的正确性。
关键词: 微处理器;流水线;精简指令集;现场可编程门阵列;嵌入式系统
随着微电子及EDA技术的高速发展,可编程逻辑器件的研发与应用也取得了长足的进步。其中,基于现场可编程门阵列(FPGA)的片上系统(System on Chip)在嵌入式系统中得到了广泛的应用。与传统的专用集成电路(ASIC)相比,其具有开发周期短、设计简单灵活等特点。
本文描述了基于FPGA的16 bit嵌入式微处理器的结构设计。该处理器采用程序存储器与数据存储器分离的哈佛型结构,采用精简指令集(RISC),指令面向寄存器操作,加快了运行速度,简化了控制逻辑。
1 系统结构设计
该处理器执行指令时按照取指(IF)、译码(ID)、执行(EX)和结果保存(WR)4个阶段依次进行。由于采用4级流水线结构,每个时钟周期能完成一条指令的执行。
1.1 指令系统
该处理器采用RISC型指令,设置了数据传送、算术逻辑运算和程序控制3大类共21条指令,指令格式固定,每条指令长度为32 bit。
1.2 硬件结构
该处理器共有4级流水线,因此可将硬件基本划分为取指、译码、执行和结果保存4部分。
1.2.1 取指
取指部分结构如图1所示。与参考文献[1]中提及的处理器取指部分相比,其增加了PC选择生成器G_PC,通过它实现了无延迟的程序转移指令。
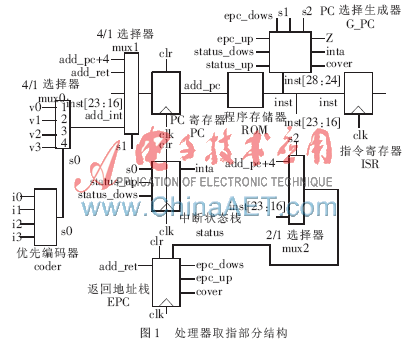
G_PC是本部分的核心,其部分Verilog HDL实现代码如下:
……
input inta,z;//inta为中断请求信号
//z为译码部分回送的信号,用于jz、jnz指令
input[4:0]p_op_code;//指令操作码,即inst[28:24]
output status_up,status_down,epc_up,epc_down;
//对status和EPC进行出入栈控制
output s2;//对将要压入EPC中的返回地址进行选择
output cover;//控制EPC顶部单元数据是否被mux2送来的数据覆盖
output[1:0]s1;//s1对下条指令的取指地址进行选择
reg status_up,status_down,epc_up,epc_down,s2;
reg[1:0] s1;
always begin
case(p_op_code)
//根据指令的操作码来产生信号的输出
5′b00000:begin//此操作码对应add ra,rb,rc指令
if(inta)begin
//如果有符合优先级条件的中断请求则inta为1
status_down=1;
//控制status在下个时钟沿将s0压栈
status_up=0;
epc_down=1;
//控制EPC下个时钟沿将相应的返回地址压栈
epc_up=0;
s1=3;
//选择中断入口地址add_int作下条指令地址
s2=0;
//选择当前指令地址加4作为返回地址压入EPC
cover=0;//EPC顶部数据不被覆盖
end
else begin//无符合优先级条件的中断请求
status_down=0;
status_up=0;
epc_down=0;
epc_up=0;
s1=0;//下条指令地址为当前指令地址加4
s2=1′bx;//s2为无关信号,0或1均可
cover=0;
end
end
……
//其他指令类似,根据操作码及是否有中断请求来生成相应的输出信号
endcase
end
优先编码器coder则从硬件电路上实现了中断源的优先级,即3号中断优先级最高,然后依次递减(3号中断的优先级值为4,2号中断的优先级值为3,1号中断为2,0号中断为1)。coder的输出信号s0既代表了中断的优先级,又起到了选择中断入口地址的作用。
取指部分的具体工作流程如下。
(1)假设此时指令地址add_pc在ROM中对应的指令inst为sub r0,r1,r2,此类语句不会使下一条指令地址发生转移。同时假设没有中断信号产生,于是当下一个时钟上升沿到达时,由G_PC生成的控制信号s1将add_pc+4选通送入PC寄存器中,即取出物理地址相邻的下一条指令(加4是因为一条指令有32 bit,共4 B)。
假设add_pc在ROM中对应的指令inst为sub r0,r1,r2,且中断状态栈status顶部单元数据为0。此时有中断信号0和中断信号2产生,优先编码器coder生成的s0为2号中断的优先级3(大于status顶部数据0),于是中断请求信号inta有效。当下一个时钟上升沿到达时,G_PC生成的s2信号和epc_down信号将add_pc+4压入返回地址栈EPC中,s0和由G_PC产生的信号s1将2号中断的入口地址v2送入PC寄存器中(0号中断被忽略掉),同时将s0的值3(即2号中断的优先级)压入中断状态栈status顶部。
(2)假设此时add_pc在ROM中对应的指令inst为绝对跳转jump 100,即程序转移到地址100处开始执行,且没有中断信号产生。则当下一个时钟上升沿来临时,由G_PC产生的s1等控制信号将inst[23:16](此时为100)送入PC寄存器中开始执行。
假设此时add_pc在ROM中对应的指令inst为绝对跳转jump 100,但此时有中断信号1产生(且假设此时status顶部值小于2),则inta为1。于是G_PC产生的控制信号将inst[23:16](即100)压入EPC顶,将中断1的优先级(即s0的值2)压入status顶部,将中断1的入口地址送入PC寄存器中,开始响应中断。如果之后又产生优先级大于2的中断,则将相关数据压栈后响应中断,若产生中断的优先级小于或等于2,则被忽略不执行。
条件转移jz、jnz与jump指令类似,只是当译码阶段产生的Z信号为1时,jz跳转,Z为0时jnz跳转。通常比较指令comp后面紧跟条件转移指令来实现程序转移控制。
(3)假设此时add_pc在ROM中对应的指令inst为调用指令call 100,执行此条指令时忽略所有中断请求信号,将add_pc+4压入EPC中后,将inst[23:16](即100)送入PC寄存器中开始执行调用程序。
(4)假设此时add_pc在ROM中对应的指令inst为中断返回指令int_ret,且没有高优先级的中断产生,则EPC顶部的数据add_ret送入PC寄存器中,同时,EPC和status中的顶部数据弹出,其余数据依次上移一位。
假设此时add_pc在ROM中对应的指令inst为中断返回指令int_ret,但有优先级比status顶部单元数据高的中断信号产生,则G_PC产生的cover信号有效,status顶部数据被新的中断优先级值所覆盖,EPC维持不变,同时响应新中断。
(5)调用返回指令call_ret与中断返回指令int_ret类似,不过执行时status中的数据不弹出。
1.2.2 译码
译码部分结构如图2所示。
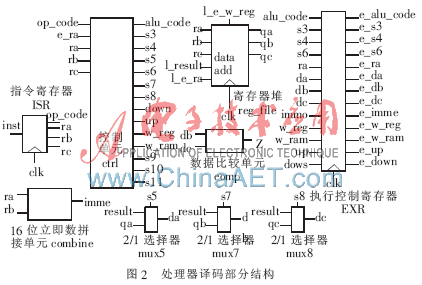
译码部分核心是控制单元ctrl。为了解决流水线的数据相关,采用了内部前推的方法,将执行部分产生的数据result回送至本部分。将比较单元comp产生的信号Z送至译码部分,使得条件跳转指令(jz、jnz)在取指阶段就能实现,从而实现无延迟跳转。
本部分中的寄存器堆reg_file在时钟下降沿且写信号l_e_w_reg有效时执行写数据操作(实现结果保存WR这一部分的功能)。ctrl产生的一部分控制信号通过执行控制寄存器EXR送至下一级使用。
1.2.3 执行
执行部分的结构如图3所示。此部分核心是算术逻辑运算单元ALU,前面译码部分的ctrl产生的运算控制码alu_code指定运算操作,运算结果c_out送入5/1选择器mux6。关于mux6的其余4路数据对应的指令为:dout对应load ra,imme即将数据存储器中指定地址单元M[imme]的数据送入ra号寄存器中;ds对应pop ra,即将数据堆栈stake栈顶的数据弹入ra号寄存器中;e_imme对应指令val ra,imme送立即数imme入ra号寄存器;e_db对应mov ra,rb即将rb号寄存器中的数据送入ra号寄存器中。

1.2.4 结果保存
这里的结果保存是针对目的地址为寄存器的指令,如算术逻辑运算指令、寄存器之间的数据传输指令等。工作流程即将图3中RSR的l_e_ra、l_e_w_reg、l_result信号送入图2中的reg_file。当时钟下降沿到达且l_e_w_reg有效时,数据l_result被写入l_e_ra号寄存器中。
2 仿真验证
为了验证该设计,利用Altera公司的Quartus II软件进行仿真验证。仿真时设计在取地址为32的指令时出现0号中断,在取地址为52的指令时出现1号中断。实际执行时,1号中断嵌套在0号中断之中。对应中断的入口地址分别为48、68。仿真结果如图4所示。

图4中a0~a6分别显示的是r0~r6号寄存器中的数据;v0、v1分别是0号中断、1号中断的入口地址;pc_num是处在取指阶段的指令的地址;ints是中断输入信号,ints=1、ints=2分别表示外设请求1号中断、外设请求2号中断。从图4中可以看出:
(1)几乎每条处在取指阶段的指令都要经过3个时钟上升沿和一个时钟下降沿后才执行完毕。这是因为指令取指完成后,还要经过译码、执行和结果保存3个阶段,并且结果保存是在时钟下降沿完成的。但由于是流水线结构,故等效于每一个时钟执行一条指令。
(2)当取到地址为pc_num=32的指令时,中断信号1产生,于是下条指令的取指地址为1号中断入口地址48。执行1号中断的子程序到52时,中断信号2产生,于是响应2号中断,下条指令地址为2号中断入口地址68(2号中断子程序就一条返回指令)。
(3)当执行地址为24的jump 0指令时,下条指令地址为0,实现了无延迟转移。
综上所述,经初步验证,该设计能实现4级流水线结构,并具备中断及其嵌套、无延迟转移等功能。
本文设计了一种基于FPGA的16 bit嵌入式RISC微处理器。该处理器主要特点是通过增加硬件结构实现了对转移指令的无延迟实现以及对中断及调用指令的支持。在下一步工作中将优化结构设计,增加外围设备,逐步构成一个高性能的单片系统。
参考文献
[1] 李亚民.计算机原理与设计[M].北京:清华大学出版社,2011.
[2] 郑纬民,汤志忠.计算机系统结构[M].北京:清华大学出版社,1998.
[3] 夏宇闻.Verilog数字系统设计教程[M].北京:北京航空航天大学出版社,2008.
[4] 于洋,肖铁军,丁伟.面向教学的16位CISC微处理器的设计[J].计算机工程与设计,2010,31(16):3584-3587.
[5] 张英武,袁国顺.32位嵌入式RISC处理器的设计与实现[J].微电子学与计算机,2008,25(6):14-17.
[6] 曾舒婷,杨志家.高性能PLC专用指令集处理器设计与仿真[J].微电子学与计算机,2011,28(7):76-81.