
引 言
在视频监控、远程视频播放等系统中,通常需要将视频图形数据通过网络传输到远程处理机上。作为数字信号处理专用处理器,DSP虽然在视频压缩等方面有很大的优势,但对诸如任务管理,网络通信等功能的实现较困难。运行于通用嵌入式处理器的Linux操作系统,开源,可以根据需要修改内核,支持各种网络协议,并且其任务调度机制性能卓越。综合二者的优点,嵌入式视频平台可以由DSP完成图形处理功能,并通过高速接口把视频数据传输给嵌入式微处理器,然后由嵌入式Linux系统完成网络传输功能。
目前DSP与微处理器之间的高速通信方式有以下几种:共享内存,此种技术对软硬件的设计要求都非常高,同样效率也最高;通用高速总线接口,如PCI、 USB等,这种类型的通信方式采用复杂的链路协议,软件设计困难;专用接口,如TI公司DSP提供的HPI(Host Port Inter-face)。本文研究了TMS320E)M642的HPI接口,并提出一种在TMS320DM642和AT91RM9200间高速通信的软硬件实现方案。通过HPI接口,TMS320DM642可以高速地将实时视频数据传输给AT91RM9200;在AT91RM9200上,Lnux驱动实现存储器映射I/O和物理内存重映射,避免了视频数据在应用程序与内核之间的二次拷贝,提高了应用程序的网络发包效率。
1 HPI接口硬件设计
HPI是一种并行接口,支持32位(HPl32)和16位(HPll6)数据总线,通过HPI的数据寄存器(HPIDA、HlPIDF),ARM可以间接存取DSP的存储空间。在DSP内部,数据从存储单元到HPI数据寄存器的传输,是由EDMA(增强DMA)控制器完成的。
HPI控制器的外围引脚包括HD[0-31]、数据总线。HCNTL[O-1]是寄存器访问控制线,HPI控制器有4个寄存器,通过这两根控制线,DSP 可以确定ARM要访问的寄存器。其中,HPIA地址寄存器,存放当前访问单元的地址;HPIC为控制寄存器,实现各种控制命令;HPIDA自增长数据寄存器,每访问一次该寄存器HPIA的内容加4;HPIDF固定地址数据寄存器,与HPIDA不同之处在于,访问该寄存器后HPIA的内容不变。HHWIL,高低位访问控制线,它只用于HPll6模式中,该控制引脚决定寄存器的高或低16位被主机访问。HR/nW,HPI控制器4个寄存器的读写控制线。 HDSl、HDS2和HCS,其中HDSl、HDS2可连接ARM的读、写控制线,HCS连接ARM的nCS7片选线,三者在DSP内部组合形成一个 HSTROBE信号,当HCS低有效并且HDSl或HDS2的读或写低有效,决定数据寄存器(HPIDA、HPIDF)的读或写操作。HAS,地址锁存线,当主机的地址线与数据线复用时,主机可用该控制线通知。DSP锁存地址;其他不用该控制线情况时,应接高电平。nHRDY,DSP输出线,表示HPI 总线是否可访问。nHINT,中断输出线,用于中断ARM。
DSP与ARM接口电路如图1所示。采用HPI16模式,16根数据线通过16245数据隔离器接到ARM数据总线的低16位,将HPI的片选空间置于 ARM的nCS7片选线上,HR/nW读写信号经反向器接到ARM的AB4地址线,HCNTL[O-1]与ARM的地址线AB[2-3]相连,则HPI的 4个寄存器的读基地址为0x80000000,写基地址为0x80000010。在ARM端从这两个地址开始访问,相应地对HPI 4个寄存器访问。
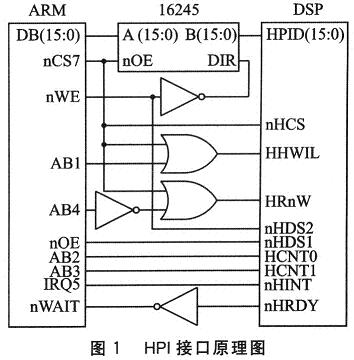
ARM通过HPI读写DSP数据空间,须按以下三步顺序执行:首先,对HPIC寄存器初始化,主要针对HPI16模式最低位HWOB位设置,决定数据传输格式是按高半字在前(设置为0),还是低半字在前(设置为1),该位对于HPI32模式无效,可不设置;然后,对HPIA寄存器初始化,设置访问单元的地址;最后通过读写数据寄存器(HPIDA、HPIDF)实现数据读写操作,其中读写HPIDA寄存器是完成连续地址单元读写操作,读写HPIDF寄存器是完成固定地址单元读写操作。注意,在ARM读写的过程中,如果DSP的nHRDY控制线一直为高,表示HPI数据总线未准备好,ARM的读写操作必须等待;当nHRDY为低后,ARM才继续向下执行指令。
2 Linux驱动设计
Linux虽然是一种整体式操作系统,但允许在运行时动态加载或删除功能模块。这个特点方便了驱动功能模块的开发。Linux系统支持两种模块调用方式:一种是静态编译,直接编译进内核,在系统启动时就运行;另外一种是动态加载,在内核运行时,用insmod/rmmod实现模块的加载和删除功能。在嵌入式系统开发中,一般采用动态加载方式,避免了系统频繁重启。当最终发布产品时,可以把模块直接编译进内核。这种处理方式比较简单,且效率高。
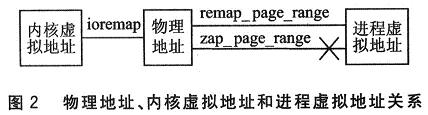
Linux系统中,内存地址主要涉及以下几个概念:物理地址、内核虚拟地址(包括内核逻辑地址)和进程虚拟地址。在内核层,当内核要访问某内存空间时,用的是内核虚拟地址,再由MMU(存储器管理单元)将内核虚拟地址转换为物理地址。采用虚拟内存技术,每个进程都有互不干涉的虚拟空间。三者直接映射的关系如图2所示,其中内核函数zap_page_range完成去掉物理地址与进程虚拟地址映射关系的功能。
2.1 驱动结构
在Linux中,设备也是作为文件来访问的。VFS(虚拟文件系统)为各种不同的文件系统提供了统一的访问接口,通过这些接口,应用程序可以直接使用open、read和IOctl等系统调用对设备进行访问和控制。
本例中,把HPI作为一个外围设备,其驱动主要实现对设备的打开、关闭、内存映射、视频数据缓冲区管理和物理内存切换等功能。根据原理图,可以确定HPI 四个寄存器对应的物理地址,在驱动初始化过程中,调用ioremap_uncache函数把物理地址映射为内核虚拟地址,在驱动层通过内核虚拟地址访问 HPI的4个寄存器。
存储器映射I/O把HPI驱动分配的数据空间直接映射到应用程序的虚拟地址空间,应用程序直接访问该空间,避免了用read/write系统调用导致的视频数据二次拷贝。在内核里,由驱动分配一定的缓存,当应用程序不能及时处理DSP发送过来的视频数据,可以缓存这些数据;当应用程序处理完一帧图像时,采用Linux的物理内存切换技术,把下一帧数据所在的物理地址重映射到应用程序的同一虚拟地址,这样,应用程序不用频繁调用mmap函数映射内存。
2.2 存储器映射I/O
一般情况下,当应用程序用read/write读写设备数据时,该设备的驱动先将设备数据从设备上采样到内核缓冲区,再从内核缓冲区拷贝到应用程序缓冲区,数据经过了两次拷贝。当数据量比较小时,如一些控制命令或状态信息,对系统性能几乎没有影响。但是,如果一次传输的数据量比较大,比如视频显卡上的实时视频图像,两次拷贝将大大影响系统的数据处理效率。这时,可采用存储器映射I/O技术,在内核层存储器映射I/O由函数 remap_page_range完成。
由remap_page_range函数的原型可以知道,该函数的意义在于通过将特定物理地址映射到进程虚拟地址,进程可以访问特定的物理地址,而这在普通情况下是不可能的。在本例中,当进程调用mmap函数进行存储映射时,内核会调用驱动注册的hpi_mmap函数,传入的参数之一包括进程虚拟地址。在 hpi_mmap函数里,调用remap_page_range完成从缓冲区物理地址到进程虚拟地址的映射。hpi_mmap函数实现如下:

mmap系统调用返回一个进程虚拟地址,该地址就是vma->vm_start字段,进程对该虚拟地址的访问,最终变为对物理地址CACHE_PHY的访问。
2.3 数据缓冲管理
缓冲管理的主要任务是,当ARM接收到新的一帧时,为其分配相应的缓存,并将在物理地址重映射到进程虚拟地址。当应用程序处理该帧时,缓冲管理负责内存区域的回收。
当Linux内核启动时,可以传人参数mem=PHY_LEN,指定存储空间的大小。在本例中,内核启动时为HPI驱动预留8 MB的高端物理内存。在本例中,借助Linux中对普通外设I/O内存(PCI卡内存等)管理的思想,用高度为2的树表示一块连续的区域。该数据结构的优点在于,资源分配简单,把离散的小内存合并为一块连续的大缓冲区的算法复杂度为O(1)。具体实现请参阅内核源码中resource结构相关部分。

在当前视频处理平台上,视频处理、视频传输、复杂任务管理等工作一般都是由一块DSP处理器单独完成,结合其他嵌入式微处理器协同工作的技术方案刚刚起步。经测试,在基于本文提出的高速通信方法设计的视频处理平台上,TMS320DM642与AT9lRM9200间的通信速率可以达到50 Mbps,带宽足够用来传输MPEG等压缩视频数据。如果用HPl32模式,速度还会大幅度提高。同时,因为Linux系统的实时性不是很强,如果采用其他实时性强的操作系统,如Vxworks等,系统性能还会有大的提高。