
URL分级散列在分布式搜索引擎中的应用
2008-05-05
作者:何淑庆,李村合,张培颖
摘 要: 搜索引擎在采用分布式技术的信息搜集中存在URL匹配和系统负载平衡的问题。针对现有的几种分布式信息搜集系统设计的不足,提出了对URL分级散列进行定位和匹配的方法,给出了两种适用于中文信息搜集的URL散列函数,并进行了实验分析。
关键词: 散列函数 分布式 搜索引擎 匹配 负载平衡
随着Internet信息量的爆炸式增长,搜索引擎越来越受关注,然而信息量的增加使得搜索引擎中的信息搜集工作变得更加繁重。单机集中式信息搜集技术已成为搜索引擎发展的瓶颈。分布式和并行处理技术以其强大的处理能力成为信息搜集技术的首选,但也产生了一些新问题,如保证节点间不重复搜集网页信息、节点间的任务分配均衡以及节点的损坏对系统的影响等。当前,围绕着分布式信息搜集技术研究较多的内容有:URL匹配算法和划分策略、节点间任务的负载平衡和系统的可扩展性" title="可扩展性">可扩展性。
URL匹配和系统负载平衡是分布式和并行技术在信息搜集系统中的关键。通过深入分析现有的几种分布式信息搜集系统的一些不足,提出了基于URL分级散列的分布式信息搜集系统。该系统主要针对中文网络信息进行信息搜集,使用了两种适用于中文信息搜集的URL散列函数对URL进行节点定位和匹配,该方法使得URL匹配对资源的开销减少、负载平衡性提高。
1 URL匹配和系统负载平衡
1.1 URL匹配
Internet中的信息是异构的、复杂的、多变的,网络中存在着大量的重复链接,若不作处理,会使搜索引擎的Spider在网络中爬行时重复处理信息,造成系统不必要的资源开销和存储空间的浪费。搜索引擎通过URL匹配算法解决上述问题,由于URL为字符串,URL匹配的问题实际为字符串匹配的问题。
散列(Hashing)是信息存储和查询所采用的一项基本技术,它能以O(1)时间复杂度对数据进行处理,可以很好地用于URL的匹配。天网的开发者通过实验评测表明:对字符串散列效果很好的ELFhash函数对URL散列效果并不是很理想,并给出了两种效果较好的散列函数。有些研究中也使用MD5算法对URL进行计算、处理并匹配,但MD5算法会消耗大量的系统资源,造成系统整体性能下降。
1.2 系统负载平衡
系统负载平衡是指分布式系统" title="分布式系统">分布式系统中各节点间任务分配的平衡。例如:一个分布式系统有n个节点,对N份任务,每个节点的任务量为N/n,这是一种理想状态;另一种极端的状态是所有的N任务集中到一个节点上,其他n-1个节点任务量为0。
系统负载平衡主要通过URL划分策略来实现。URL划分有动态和静态两种方式。URL动态划分策略会使系统负载平衡性更好一些,但系统资源开销更大,且不易实现。静态划分策略实现简单,占用系统资源开销少,若划分策略合理,也能使系统具有很好的系统负载平衡。例如:站点散列策略(一个站点一旦散列到某个节点,则该节点负责该站点的所有任务)能很好地将站点均匀地散列到系统的节点上。
1.3 URL匹配和负载平衡的问题
在分布式信息搜集系统运行过程中,URL匹配需要考虑到整个系统搜集到的URL,通过增加一个控制系统和节点的URL共享来解决这种问题。例如:在每个搜集节点上部署相同的visited_urls数据表(已经访问过的URL数据表),URL与其进行匹配。这种方法既浪费了节点的存储空间又降低了URL匹配的成功率,而且随着节点的增加不会改善反而会加大通信的开销,也限制了分布式信息系统性能的提升空间。
站点散列策略可以使站点比较均匀地分布到每个节点上,但网络中每个站点包含的信息量相差很大。假定几个信息量非常大的站点散列到某个节点上,而另一个节点上的大站点少一些,则这两个节点负载会出现不均衡。考虑到站点个数S>>节点个数n,上述情况出现的几率非常低,一般可以忽略。但基于这种方法设计的系统搜集到后期会发生某些节点的搜集任务集中在几个包含信息量大的站点上的问题,造成系统搜集的效率急剧下降。当系统中的节点n变大,而针对搜集的站点S变小的情况下,站点包含信息量不均的问题不能忽略,造成分布式信息搜集系统可扩展性和可移植性不好。
2 基于URL分级散列的分布式信息搜集系统
搜集系统通常由三部分组成:控制模块" title="控制模块">控制模块、搜集器和原始数据库。控制模块控制搜集器的工作,是整个系统的核心。搜集器的功能是爬行和解析信息。原始数据库的功能是存储信息。分布式信息搜集系统按控制模块的设计分为三种" title="三种">三种方案:独立方案、动态分配方案以及静态分配方案。
2.1 三种设计方案的分析
独立方案:分布式系统中各节点单独运行,互不通信。由于网络信息的复杂性,很难找到一种方法将网络信息分成单独的几块,所以这种方案在分布式信息搜集系统中一般很少采用。如果只针对信息量的搜集而言,独立方案的性能最好。例如:一个分布式系统中有n个节点,每个节点的搜集性能均为p,则整个系统的信息量的搜集性能为n×p。
动态分配方案:分布式系统存在一个控制模块,在系统运行过程中,动态地分配URL到各个节点。利用节点与控制模块之间的通信,动态分配方案可以实现网络信息的搜集工作。但是分布式系统内部信息的通信占用带宽,使得系统中每个节点的原有搜集性能p下降,系统的信息量搜集性能小于n×p,造成整体性能降低。
静态分配方案:将URL按事先分配好的策略分配到各个节点。静态分配方案的关键在于URL划分策略,一个好的URL划分策略占用很少的系统开销,却可以很好地解决URL匹配和系统负载平衡问题。但静态分配方案也存在缺陷,即跨节点的URL问题:一个URL可以被某些节点发现,却不能被处理。这使得搜集过程中缺失大量的信息。
2.2 基于URL分级散列方案
对以上三种方案分析表明:独立方案信息搜集性能最好;动态分配方案处理网络信息搜集最理想化;静态分配方案实现效果最好,但存在技术上的缺陷。吸取它们的优点,笔者给出了基于URL分级散列方案:分布式系统由一个控制节点" title="控制节点">控制节点和若干个搜集节点组成,搜集节点只处理定位到本节点的URL,其余提交控制节点,由控制节点负责URL的调度;URL的定位和URL匹配实行分级散列处理,根据URL的地址格式:scheme://host:port/path,URL定位使用针对路径(path)的散列函数,URL匹配过程中使用针对站点(host)的散列函数,并根据路径散列函数进行站点内匹配。
该方案URL的处理流程:首先根据Spider解析出的URL表对URL实行节点定位,每个节点单独处理定位到本节点URL,对于定位后发现不属于本节点的URL,发送到控制节点;然后控制节点对这些URL定位,在合适的时间发送URL到其定位节点;同时每个节点对本节点搜集到的URL在控制节点做实时更新及控制节点上待定位的URL做相应处理,以免造成URL重复处理,搜集节点与控制节点采取定时、有限的通信。URL处理流程如图1所示。
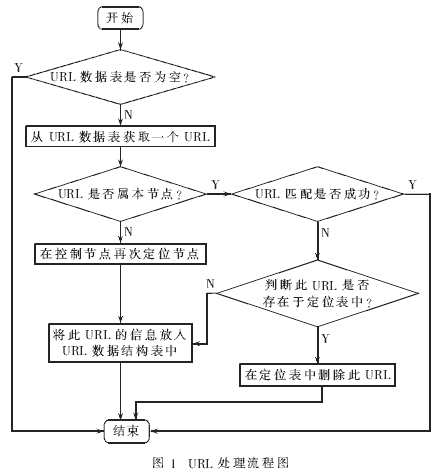
2.3 两种URL散列函数的设计
系统在定位过滤器、匹配过滤器和定位分配器的运行中以及在URL定位表和URL数据结构表的生成过程中都需要对URL做大量的散列处理,对URL散列函数的要求较高。本文设计的系统是面向中文信息的搜集系统,常用的散列函数在此处的应用效果不理想。针对中文信息的特点,给出了两种适用于中文信息搜集的URL散列函数。
据2004年中国互联网络信息资源数量调查报告,截止到2004年底,CN注册下的域名总数为432 077个,全国域名总数为1 852 300个。全国网站总数约为668 900个。全国网页总数约为650 682 300个。当前中文网址在百万数量级,中文网页在10亿数量级,站点的平均页面数量在1 000以上。
虽然运用散列技术进行匹配的成功率无法准确预见,但大量的实验表明:设装填因子为a,给定散列表空间为N,对S个站点进行散列,则a=S/N,当a<0.75时,散列的效果很好。基于此特性,设计了URL匹配散列函数和URL定位散列函数。
2.3.1 URL匹配散列函数
URL匹配散列函数是针对中文站点散列匹配的函数。设定站点散列函数的表空间为221(2 097 152)。由于字符的ASCII码值的首位为扩展位,函数中取字符的ASCII值的后七位进行运算。
Java语言实现如下:
int result(String url){ // 指定一个URL字符串
int r=0;int s=0; //给定两个32位的整型变量r,s=0
for(int i=0;i
s=r; //将结果值赋值给变量s
while(!(r==s)){ //相加后结果值与上次值的1~21位相等时停止
r=s&0x001FFFFF; //获取值的1~21位
s=(s&0xFFE00000)>>21; //获取值的32~22位,并将获取值右移21位
s=s+r;} //获取原来值的32~22位与1~21位相加的结果值
return s; //返回结果值s
}
2.3.2 URL定位散列函数
考虑到每个站点的平均网页数量为1 000多,设定path散列的表空间N为215(32 768),该值可以满足大多数的站点,对少数的大站点超过0.75N,再次进行动态散列。定位散列函数的实现比站点散列函数简单,基于path的长度较长而对散列的表空间要求不高。函数中取字符的ASCII码值的后五位进行计算。
Java语言实现如下:
int result(String path){//指定path字符串
int r=0;int s=0;//给定两个整型变量r,s=0
for(int i=0;i
if(i%3==2){ //每三位字符的ASCII码值为一组
r^=s;s=0;} //将r异或s的值赋值给r,s清零
}
return r^s; //返回结果值r^s
}
2.4 系统小结
URL分级散列方案通过URL定位方式实现URL的划分,使系统的负载平衡性和健壮性加强:因为网络中的URL数量远远大于站点的数量,所以URL定位方式在URL分配的负载平衡上优于站点散列方式;因为一个站点的URL会散列到不同的节点,所以单个节点的损坏对站点的影响减小,从而系统的健壮性很好。该方案使用了简单易行、针对性强的两种URL散列函数,减少了系统运行中大量的散列运算对系统资源的消耗,提高了URL匹配的成功率;同时将URL匹配集中在控制节点上,URL的划分使搜集节点上需要匹配的URL量减少,进一步节省了搜集节点的资源开销和URL的匹配成功率。采用二级散列的方法还使系统具有启发式信息搜集的功能:在控制节点上,URL进行站点匹配失败,即该站点未搜集过,则定义为新站点,控制节点启动对此站点的搜集任务。这种基于站点的启发式搜集对系统首次搜集效果明显。
该方案集中了以往三种方案的优点:搜集节点只处理本节点的URL使其具有独立搜集的功能;定位过滤器实现静态划分策略;控制节点使其具备动态分配的功能。
3 实验分析
采用Java语言模拟分布式信息搜集系统的工作,主要测试三个方面:分布式信息搜集系统的性能提高、负载平衡和URL匹配。
系统的搜集节点分别设置为1、3、5、7、11、13,得到URL搜集性能统计表如表1所示。

由表1得出:随着分布式系统节点个数的增加,系统搜集的信息量也增加,系统的整体性能也得到了提高,但是节点数的增加却使单个搜集节点的性能有所下降。考虑在利用Java多线程技术进行的仿真试验中,线程的增多和网络信息量的增加,会使系统资源和网络通信开销过大,单个搜集节点的性能应该有所提高,分布式系统的性能基本上随着搜集节点的增加呈线性增长。
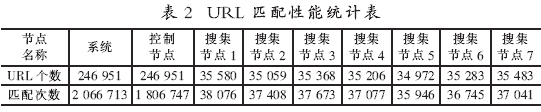
URL匹配性能统计表如表2所示。由表2得出,系统中URL很好地散列到各个节点且节点上的URL匹配成功率非常高。主要匹配集中在URL控制节点上,此节点不负责对信息的搜集,只是用来调度跨节点的URL和构造URL数据结构表,控制节点采用定时有限的调度方式,因此,控制节点任务的繁重不会使系统的搜集性能下降。
分布式搜索引擎是搜索引擎发展的方向,当前围绕着URL匹配、系统负载均衡以及减少内部开销等问题的研究增多。本文提出了基于URL分级散列的方案,通过简单的散列函数实现URL的定位和匹配,减少了搜集节点的资源消耗;在URL匹配上,定位策略使搜集节点的匹配表缩小,匹配成功率升高;在系统负载平衡性上,URL定位搜集节点的策略好于根据站点散列的策略;在可扩展性上,因为URL的数目>>站点数目>>搜集节点数目,所以该方案中搜集节点的增加对系统影响较小,可扩展性好于站点散列策略;在首次信息搜集中,通过控制节点进行启发式搜索,使首次信息搜集性能大大提高;在控制节点上,首次信息搜集完毕会生成完整的URL数据结构表,这是控制和分析URL的核心,系统可以根据URL数据结构表更新策略和分析站点信息,为系统信息更新导航。
参考文献
1 McKenzie B J,Harries R,Bell T.Selecting a hasing algorithm [J].Software Practice and Experience,1990;20(2):209~224
2 Junghoo C,Hector G M,Lawrence P.Efficient crawling through URL ordering[J].Computer Networks and ISDN Systems,1998;30(4):161~172
3 李晓明,闫宏飞,王继民.搜索引擎原理、技术与系统[M].北京:科学出版社,2005:80~84
4 李晓明,凤旺森.两种对URL的散列效果很好的函数[J]. 软件学报,2004;15(2):179~184
5 CNNIC.2004年中国互联网络信息资源数量调查报告[R].中国互联网络信息中心,2005
6 燕彩蓉,彭勤科,沈钧毅等.基于两阶段散列的Web集群服务器内容分配研究[J].西安交通大学学报,2005;39(8):812~815