
信息聚合中多智能Agent模型研究
2008-06-04
作者:李学峰1,2,李彩清3,王文杰1
摘 要: 介绍了一种多智能Agent模型,用于解决用户个性化信息的聚合问题。该模型采用的运算法则是改进型的蒙特卡罗方法,并接合了Hopfield网络模型" title="网络模型">网络模型和Suffix Tree的特点,较准确有效地实现了对用户爱好信息的聚合。
关键词: 多智能Agent 信息聚合 智能模型
20世纪90年代以来,随着计算机网络、通信等技术的快速发展,网络环境" title="网络环境">网络环境正由Client/Server发展到Client/Network,并向Client/Virtual Environment发展,分布式人工智能DAI(Distributed Artificial Intelligence)受到了人们的广泛关注,对智能Agent的研究又是其中的一个热点[1]。多智能Agent降低了对集中式、顺序控制的限制,提供了移动控制、应急和并行处理,不仅为用户提供了一种远程智能程序设计的方法,实现了更加快捷的问题求解,而且将用户从纷繁的信息海洋中解放出来,可以集中精力关注他们感兴趣的信息。
用户对网络感兴趣的并不是网络资源所蕴含数据量的大小,而是那些可以在一定程度上能够满足自己需要的个性化信息,他们都希望能在最短的时间内掌握这些信息的分布情况。用传统的的方法来解决这个问题时,用户的代理服务器往往会遇到许多质疑,例如在无法深入调查用户坦率度的情况下如何准确把握用户的兴趣;如何保证对用户兴趣的模拟是准确的;如何保证聚合信息能满足用户的需求等。本文就如何准确模拟用户兴趣,并依此聚合用户的个性化信息作了尝试性研究,对常用的运算法则和模型的设计思想" title="设计思想">设计思想作了一定的改进,收到了良好效果。
1 智能Agent
Wooldridge等人对智能Agent的“弱定义”和“强定义”[2]广为人们接受。智能Agent不仅具有反应性、自治性、面向目标和环境性四个基本特征,还具有理性、善意和学习等特点。因此可以认为智能Agent是指能为用户执行某些特定的任务且具有心智状态(mental state)[1][3],能自主地根据需要进行分析推理、自我完善的软件体,是一个具有一定智能行为的概念“人”。智能Agent既是人工智能的最初目标,也是人工智能的最终目标。
2 模型设计
2.1 智能Agent模型
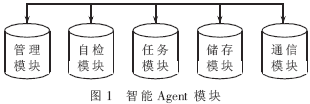
模型选用了1998年中国科学院计算技术研究所研制的多主体系统开发工具AOSDE(Agent Oriented Software Developing Environment)。该系统用Java编写,可以保证Agent的可移植性和异构环境下的互操作性。在此基础上设计了智能Agent的统一结构模型,包括五个模块:管理模块、自检模块、任务模块、储存模块和通信模块" title="通信模块">通信模块,如图1所示。管理模块是核心模块,它负责监控其他四个模块,负责智能Agent的自我保护和自我完善;自检模块负责智能Agent的初始化和性能检测;任务模块负责接收任务、解释任务、执行任务并返回执行结果;储存模块负责存储备用数据和执行结果;通信模块负责智能Agent间、智能Agent与Agent平台间的数据交换。
2.2 智能Agent设计
模型中用到的智能Agent按功能分作四类" title="四类">四类:用户Agent、描述Agent、汇总Agent和学习Agent,它们的协作关系如图2所示。
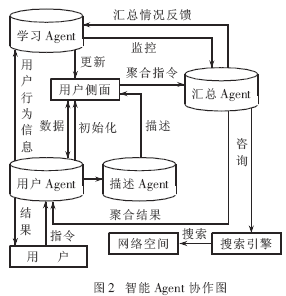
(1)用户Agent,它是一个界面Agent,扮演“眼睛”的角色,完成用户与系统间的对话。
系统运行期间,用户Agent观察用户行为,并将观察到的行为信息传递给学习Agent和描述Agent。例如记录用户的ID号、文档的关键词,用户是否下载了文档、是否在文档中添加了书签或者建立了超链接等。用户通过它可以随时调用或更改用户侧面中储存的兴趣主题(副主题),整个系统对用户是透明的。
(2)描述Agent,它采用语义网络的表示方法来描述用户兴趣,并与学习Agent协作完成对用户兴趣的模拟。
用户的兴趣可以是单个主题,也可以是多个主题的结合体。描述Agent在对概念、行为描述的过程中考虑了合取概念聚类问题[3]和主题间的相关性,用副主题来描述多个主题的聚合概念,主题和副主题都储存在用户侧面中。
描述Agent还负责描述用户对聚合信息的反映,并把结果作为计算主题(副主题)优先级变化量的一个参数。法则如下:用户对聚合信息中与主题(副主题)n相关文档j的反映可以分作四类:不喜欢、希望了解、比较感兴趣、喜欢。参数依次设定为-1、0、1、2,分类的依据是时间利用率β,β=tn/T,其中,用户访问网络的时间为T,用户浏览j所用时间为tn,n的优先级变化量记为δmn。定义:β≥0.5时,用户对文档j喜欢,δmn=2;0.5>β≥0.3时,用户对文档j比较感兴趣,δmn=1;0.3>β≥0.15时,用户对文档j只是希望了解,δmn=0;β<0.15时,用户对文档j不喜欢,δmn=-1。用户退出用户Agent时,描述Agent将δmn作为更新值传递给用户侧面。描述法则伪程序如下:
(3)汇总Agent,它是模型的“双手”,通过搜索和汇总来完成信息的聚合。
模型选用Google Web Service来完成搜索任务,应用程序接口选用Google API[4]。汇总Agent将搜索结果(URL、摘要等)按主题(副主题)优先级从高到低的顺序排列,在提交用户Agent的同时向学习Agent反馈汇总情况。为了使聚合效果更佳,模型采用了文献[5]中详细讲述的STC(Suffix Tree Clustering)方法。在网络性能良好的情况下,如果搜索结果为空,它一方面向用户Agent提交“搜索结果为空,请重新输入主题(副主题)”的请求,另一方面将搜索情况反馈给学习Agent,由学习Agent向用户侧面传递删除n的指令。如果网络存在故障,则暂时保存n。
(4)学习Agent,它扮演“大脑”的角色,是整个模型的核心部分,它依据用户的行为信息和汇总Agent的反馈信息来更新用户侧面,完成对用户兴趣的模拟。
用户的行为信息指用户对聚合信息的反映情况。用a、b、c、d、,e依次表示用户是否点击了文档、用户是否浏览了文档、是否给文档加了标签、是否下载了文档、是否建立了超链接。文档优先级的计算采用Hopfield网络模型学习方法,a、b、c、d、e五个输入节点按照“是”选1、“否”选0的方法来标注用户对文档的兴趣程度,输出节点是文档的优先级,用k表示。
学习Agent依据用户的行为信息更新用户侧面。法则如下:文档j的优先级kj可用上述方法求出,mn表示主题(副主题)n的优先级,定义初始值为20,最高值为50,最低值为0,当20<mn≤50时,用户对n兴趣度比较高;当0
2.3智能Agent间的协作
模型采用多智能Agent旨在克服单个智能Agent知识不完整、处理信息不确定等缺点,解决单个智能Agent由于各种原因不能或难以解决的问题,形成智能Agent协调合作的问题求解网络。这种协作表现为:智能Agent间的相互依赖、对协作行动的相互承诺、无死锁的协作过程、协作与约束和协作与协调。如图3所示。
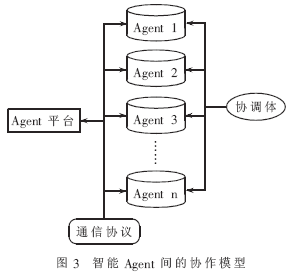
协调体负责智能Agent间的任务分解、合作规划和竞争谈判,尽可能避免冲突。智能Agent间的通信语言ACL(Agent Communication Language)通常有两种:KQML(knowledge Query and Manipulation Language)和KIF(Know-ledge Interchange Format)。模型选用了KQML,它定义了一种描述Agent间信息传递的标准语法以及一些“动作表达式”。
2.4 设计思想
选优是人类赋予科学的永恒课题。蒙特卡洛方法MCM(Monte Carl Method)是一种优选法,用来解决数学和物理的非确定性问题,在确定大量事物的某种特定表现时行之有效。MCM作为一种统计方法,随着取样次数的增大,计算结果与事实相符。
模型中用到的运算法则是结合了Hopfield网络模型和STC特点的改进MCM。问题原型如下:设计一种优化策略,通过智能Agent间的协作来模拟用户兴趣、聚合需求信息。由于网络更新速度快,文档的URL刷新频率高,聚合信息需要及时更新。模型考虑了两种情况:(1)用户没有发布查询指令时,汇总Agent处于静止状态,不更新聚合信息;(2)汇总Agent收到聚合指令后,开始搜索网络空间,更新聚合信息。这样处理既满足了用户的需求,又提高了系统的利用率。
对于兴趣固定的用户,用户侧面中的主题是比较固定的,系统只需将用于模糊查询的主题组加以合取聚类,作为新的副主题更新用户侧面就可以了;对于兴趣不固定的用户,用户侧面中的主题(副主题)以及聚合信息需要的更新周期短,系统运行期间,通过不断地更新用户侧面,删除用户并不真正喜欢的主题和副主题,使用户侧面尽可能地与用户兴趣相一致,而不去考虑用户的坦率度,也不需要去深入质问用户的兴趣爱好。
模型中用到的运算法则有别于传统的MCM。首先,文档j的优先级算法都一样,结果可被视为传统MCM算法的平均值,因为汇总Agent每次搜索的网络环境和信息聚合结果完全一样的概率很小,计算结果kj与用MCM算出的结果相当。另一方面,传统的MCM把用户的行为信息存储在“look up table”中,而模型对于用户的行为信息并不加以保存,只是作为学习Agent和描述Agent计算用户兴趣主题(副主题)优先级更新值的依据。汇总Agent可以根据用户侧面传递的聚合指令自动聚合信息,所以MCM中的发现、存储用户行为信息并不是必须的。
2.5 系统运行
系统首次运行时,要求用户输入用户名、兴趣主题、关注的网站等原始资料,它们被储存在以用户名命名的用户侧面中,系统允许用户创建新侧面或者更改已有侧面,也允许新用户在通过身份认证的前提下调用已有的用户侧面。
面对纷繁复杂的网络环境,如何让用户在尽可能短的时间内掌握兴趣信息的分布情况,是本文设计聚合模型的目标,虽然该模型在一定程度上使信息聚合变得简单化和智能化,但是距设计目标还有很大的距离,相信随着人工智能技术的不断完善,智能Agent的日趋人性化,基于智能Agent的信息聚合系统将会臻于完善。
参考文献
1 王文杰,叶世伟.人工智能原理与应用.北京:人民邮电出版社,2004
2 Wooldridge M,Jennings N R.Intelligent Agents:Theory and Practice.Knowledge Engineering,1995;10(2)
3 史忠植.智能主体及其应用.北京:科学出版社,2001
4 IBM.WS applications with the Google API.IBM Developer Works,http://www.ibm.com/developer works
5 Branson S,Greenberg A.Clustering Web Search Results Us-ing Suffix Tree Methods.http://stanford.edu/lass/archive/cs/cs276a/cs276a