
基于嵌入式多核SoPC平台的说话人识别系统应用研究
2008-07-02
作者:何 伟,胡又文,张 玲,陈方
摘 要: 针对当前基于DSP、ARM等硬核处理器设计的嵌入式说话人识别" title="说话人识别">说话人识别系统训练和辨认时间长等缺陷,根据MFCC提取过程的特点与遗传聚类" title="聚类">聚类算法中适应度计算的原理,提出一种基于SoPC平台与矢量量化" title="矢量量化">矢量量化原理的说话人识别系统" title="说话人识别系统">说话人识别系统实现方案。经测试,该实现方案在保证识别率前提下,可有效提高训练与识别速度。
关键词: 说话人识别 矢量量化 遗传算法" title="遗传算法">遗传算法 适应度 SOPC
说话人识别(Speaker Recognition)又称话者识别,是指根据特定说话人语音波形中反映生理和行为等特征的语音参数来对说话人身份进行识别[1]。说话人识别技术作为一种非接触性识别技术,在保安、司法、军事和信息服务等领域都有广泛的应用前景。
文本无关的说话人识别方法是当前说话人识别技术的研究重点。常用的识别算法有:基于矢量量化VQ(Vector Quantization)的方法[2]、基于HMM的方法、基于ANN的方法等。其中,基于VQ的说话人识别方法无需考虑复杂的统计模型和时间归整问题,运算过程简单,在说话人识别领域被广泛应用。
基于VQ的说话人识别通常采用MFCC参数,因为MFCC是一种基于人耳对语音频率的非线形感知特征的描述参数[3],在说话人识别中,其性能优于LPC、LPCC等参数。
SoPC技术是一种基于FPGA解决方案的SoC,由美国ALTERA公司于2000年提出[4]。基于SoPC平台的开发结合了FPGA灵活可编程与片上NiosII软核处理器的用户可配置等特点。在实现某功能时,可编写C/C++程序运行于NiosII处理器实现,也可设计硬件模块实现,不占用CPU,起到了硬件加速效果。本系统综合两种实现思路,采用高性价比的Cyclone II 2C35系列FPGA实现。经验证,该说话人识别系统识别率高,实时性优于硬核处理器系统,应用前景良好。
1 基于矢量量化的说话人识别算法
说话人识别中,先需要建立表征用户语音特征的码书,码书由从用户的训练语音中提取的MFCC聚类而成。识别阶段,系统先采集一段测试者的语音,提取出MFCC,再与用户VQ码书匹配,如果失真测度达到一定范围,则可认为测试者即为码书表征的用户。
建立码书时,先由系统采集一段用户语音,经分帧与MFCC提取后可得到N 个M 维原始矢量On={o1,o2,
oM}(n=1,2,3…,N ),其中每一矢量相当于M维空间中的一点。然后将N 个原始矢量在M 维空间作K聚类,得到的聚类结果即是表征说话人语音特征的K容量码书。其中,用于构建码书的N帧M维MFCC称为训练序列。
根据实验验证并综合考虑系统资源与识别性能,参数设定总帧数M一般取256或512,码书大小K取64,M取12或16(若加上差分参数可扩至24、36等)。由于是在高维空间聚类,普通聚类方法易导致结果陷入局部最优点,因而选择具有全局搜索性能的遗传算法进行聚类,可得到最优码书。针对说话人识别设计的算法,具体细节如下:
群体规模:30
编码方式:二进制编码
交叉变异:无回放随机选择策略选择单点交叉,交叉概率PC =90%,变异概率PM =10%
迁移间隔:每运行2代迁移一次
选择(替换) 轮盘赌方式+10%最优个体保存
个体适应度计算公式为:

X 为训练序列,Y 为个体,d(Xj,Yi)是训练序列中某点Xj与个体中某点Yi之间的欧氏距离。
停止条件为当遗传代数达到规定阈值或最近三代最优个体适应度比值达一定阈值。
同时,在遗传过程中可每隔若干代执行一次K-means聚类以加快收敛速度。遗传结束后,最末代得到的最优适应度个体即为用户的VQ语音码书。
识别阶段,系统先采集一段测试者的语音,提取出MFCC,称为测试序列,然后与用户VQ码书比较。如果匹配度达到一定范围,则可认为测试者即为码书表征的用户。
2 系统方案与实现
说话人识别系统主要有四项任务:(1)说话人语音采集与有效语音提取;(2)语音帧MFCC提取;(3)通过遗传算法计算得到说话人语音VQ码书;(4)在说话人识别时实时采集测试者语音并提取MFCC,然后与已有码书进行匹配并作出决策。
SoPC设计中,根据需要可在单FPGA内配置多CPU。本系统配置了双CPU,两块CPU均以同一片SDRAM为运行内存,由Avalon总线模块提供仲裁机制实现双CPU对SDRAM的分时访问。系统除含有必要的储存器与语音输入接口外,还外接PS2键盘与LCD、VGA显示器等人机交互设备,整体设计框图如图1所示。

2.1 语音采集与有效语音提取
语音A/D转换由WOLFSON公司的WM8751语音芯片实现。系统上电后,FPGA内的用户制定配置模块以I2C时序配置该芯片工作模式为8kHz采样频率与16bit采样深度,采样得到的语音数据以I2S时序串行传输到FPGA芯片中。
语音数据由采样芯片传至FPGA芯片端口后,由用户制定硬件采集模块负责接收,该模块还负责计算本次收到数据的前向差值与平方值,然后将接收的数据、前向差值和平方值通过Avalon总线传至SRAM。这样,该模块在实现数据采集的同时,完成部分过零率与短时能量计算的工作。SRAM中有两块地址固定的数据存储区A与B。当采样模块采集满A区并通知CPU读数后,如果语音芯片继续传来数据,采样模块将接收的数据存储到B区中,这样CPU读A区不会与模块写B区产生冲突,B区写满后模块与CPU以相同方式工作。
CPU采集到语音数据后进一步作分帧处理与静音检测,经检测为有效语音的数据帧予以保留。每一语音帧根据式(2)、式(3)计算短时能量与过零率,然后通过双门限法检测该段数据是否为有效语音。式(2)、式(3)中,N为每帧采样点数。由于每个采样点的前向差值与平方值已由数据接收模块算出,CPU只需提出这些值按帧累加即可。检测为有效语音的数据帧放入SDRAM中的循环缓冲区中,当有效语音数据足量后,CPU停止采集模块工作。
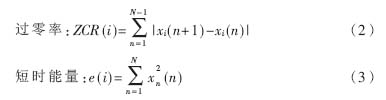
2.2 语音MFCC参数运算
语音采集与检测过程中,若采用笔者设计的主-从CPU帧流水MFCC提取结构(图2),可使语音和MFCC提取在双CPU上同步进行,从而提高系统效率。双CPU结构中,主CPU完成采集与检测,从CPU实现MFCC提取。该结构工作过程如下:
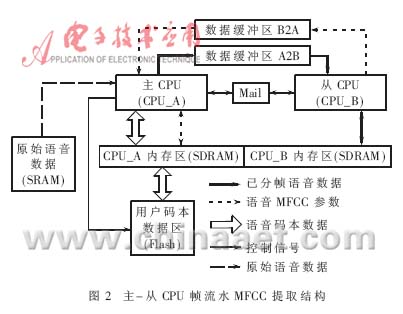
当主CPU采集到一段原始语音数据后,对该段数据进行分帧与检测,然后将有效语音数据按帧写至缓冲区A2B,并通过邮箱通知从CPU。若主CPU在下一段原始语音数据到来前通过邮箱得知缓冲区B2A有从CPU处理完成的MFCC,则将其读出至主CPU内存中。由于主CPU对MFCC的接收是查询,对语音数据的接收是中断,故收发数据不会产生冲突。由邮箱消息启动从CPU,一旦获悉有新语音数据到来,即从缓冲区A2B中读取数据到从CPU内存。当从CPU运算出MFCC,将MFCC写至B2A缓冲区,然后发送信息至邮箱。从CPU的内存区内设有MFCC缓冲区,若B2A内的数据未被主CPU读完,而新MFCC已经提取完成,则从CPU将新MFCC暂存在缓冲区中,待B2A中的数据被读完后再将新MFCC写入。主从CPU进行通信的邮箱由硬件逻辑资源构成,双CPU可通过该邮箱同时收发信息。
主-从CPU流水结构串行处理语音数据可有效加速MFCC参数的提取,相当于数据在双CPU系统中以帧为单位作流水处理,使语音采集与MFCC参数提取同步进行。
2.3 适应度计算硬件结构及遗传算法实现
MFCC参数提取完成,设得到N帧M维MFCC。根据前面讨论,码书容量选择为F=64,若取M=12并加上一阶差分参数,N=512,遗传个体T=30;根据式(1)估算,执行一代群体适应度计算至少需作(2M)×N × T × F =23592960≈24M次乘法和48M次加减法,加上遗传动作,执行一代遗传的总步骤更远远超过运算次数。实验可知,遗传收敛代数大约为40~150,因此直接用软件程序实现必导致耗时过长。
根据适应度计算的算法特点,在设计中采用并行流水结构实现适应度计算,可大大减少耗时。根据式(1),K维空间中两点之间距离的计算可采用K路并行运算器实现,得到的K路输出并行进入K输入加法器,再作开方处理即得到两点距离,然后通过比较得到式(1)中的最短距离值![]() 并累加,再将此距离累加便可得到适应度的倒数。这一系列计算可通过流水硬件结构实现。
并累加,再将此距离累加便可得到适应度的倒数。这一系列计算可通过流水硬件结构实现。
根据该思路设计的适应度计算的硬件结构框图如图3所示。由图3可知,CPU将训练序列与单个个体通过地址分配单元按维写入K路数据存储与运算单元,由选择与控制单元启动运算,K路并行运算的结果通过K输入加法器与距离运算单元得到两点欧氏距离,选择与控制单元输出结果进行比较,搜索 ![]() 并累加,经过N次处理后,得到该个体适应度的倒数,并由控制与选择单元以中断方式将该值返回给CPU,完成一个个体的适应度运算。CPU处理完这个个体的适应度值后,再将下一个个体写入存储单元并重复上述过程,直至求出最佳个体。
并累加,经过N次处理后,得到该个体适应度的倒数,并由控制与选择单元以中断方式将该值返回给CPU,完成一个个体的适应度运算。CPU处理完这个个体的适应度值后,再将下一个个体写入存储单元并重复上述过程,直至求出最佳个体。

该适应度运算并行流水结构由硬件实现,执行一代群体适应度计算仅需时钟周期数为:(F + 1)×N ×T +(2M ×T×F)=1044480≈1M,远优于软件实现。
在嵌入式系统中实现遗传算法,为降低运算量,通常要对适应度函数作各种简化,如稳态方式[5],通过限制每一代发生变化的个体数量来减少运算,但是这些改进一定程度上限制了算法的随机性。SoPC系统采用硬件资源设计的适应度计算硬件结构加速了适应度运算,克服了算法实现上的难点。
遗传聚类算法中,交叉和变异等遗传操作主要是对存储器的读写与位操作,采用硬件加速效果提升不大,因此这部分功能由软件在处理器上实现。总体而言,系统设计中,将运算量小但步骤繁杂的部分通过软件完成,运算量大的部分通过硬件模块实现,体现了SoPC设计的灵活性能。
2.4 实现说话人识别
说话人识别阶段是针对说话人的辩识过程,通过VQ特征提取与遗传算法操作得到的说话人模板的1个64容量的码书,其值表征某用户的个人语音特征。识别阶段,先采集一定量测试者语音并提取MFCC,由主CPU执行测试者语音MFCC和用户码书的匹配操作,匹配度计算公式与适应度计算公式相同。当得到的匹配度大于经验阈值,则测试者为合法用户,小于阈值则测试者被拒绝。
3 实验分析与结论
VQ说话人识别中,参数的选择对系统性能有一定影响。主要可选参数有训练序列长度与MFCC维数;被影响的性能参数有误识率,FPGA资源消耗与训练识别时间。
实验测试环境为普通实验室,参与实验者共24人(男15人,女9人),测试语音时长不低于5秒。实验中,随机选不同人员语音生成用户码书,然后全体人员参与测试。
表1为不同参数设置下系统性能与资源耗用情况。根据表1可知:在相同的训练语音时长(即训练序列帧数)基础上,使用MFCC+差分参数的系统识别率优于单纯使用MFCC,但带来的数据处理量、存储单元和逻辑单元的消耗也相应增大;同时,训练序列帧数对识别率的影响比提高维数更加重要。这是因为在训练语音帧数有限的情况下,训练语音时长对用户码书的修正效果更加明显,使码书更能反映用户的语音特征。但是这样也带来大量存储单元的消耗与训练时间的增加。

此外,还进行了不同平台上相同算法的耗时比较实验,结果如图4所示。图4中DSP平台采用C5502,PC平台为主频1.6GHz的AMD处理器,纵轴表示完成训练过程的用时。可见,采用适应度计算模块的SoPC系统速度性能远远优于硬处理器系统。

参考文献
[1] O′SHAUGHNESSY D.Speaker recognition.IEEE Acoustic. Speech and Signal Processing Magazine,1986,3(4):4-7.
[2] SOONG F K.Vector quantization approach to speaker recognition.ProcICASSP85,1985:387~390.
[3] 张军英.说话人识别的现代方法与技术[M].西安:西北大学出版社,1994.
[4] 任爱峰,初秀琴,常存,等.基于FPGA的嵌入式系统设计[M].西安:西安电子科技大学出版社,2004.
[5] BORNHOLDT S,GRAUDENZ D.General asymmetric neural networks and structure design by genetic algorithm.Neural Networks,1992,5(2):327-334.