
一种高速并行FFT处理器的VLSI结构设计
2008-09-23
作者:万红星, 陈 禾, 韩月秋
摘 要: 在OFDM系统的实现中,高速FFT处理器是关键。在分析了基4按时域抽取快速傅立叶变换(FFT)算法特点的基础上,研究了一种高性能FFT处理器的硬件结构。此结构能同时从四个并行存储器中读取蝶形运算所需的4个操作数,极大地提高了处理速度。此结构控制单元简单,便于模块化设计。经硬件验证,达到设计要求。在系统时钟为100MHz时,1024点18位复数FFT的计算时间为13μs。
关键词: FFT 蝶形单元 块浮点 流水线
正交频分复用OFDM(Orthogonal Frequency Division Multiplex)是近几年兴起的一种在无线信道上实现高速数据传输的新技术。它采用多载波调制技术,其最大的特点是传输速率高,对码间干扰和信道选择性衰落 具有很强的抵抗能力。在OFDM系统中,各子载波的调制解调采用一个实时的快速傅立叶变换(FFT)处理器实现,因此高速FFT处理器是OFDM系统实现中的一个重要因素。目前通用的FFT模块可以达到的速度数量级为1024点16位字长定点、块浮点、浮点运算在几十到数百微秒量级[1],其中采用TI公司的DSP62XX定点系列达到66μs量级处理速度,新近的64XX在600MHz时钟频率下完成1024点定点FFT的时间仅需10μs。C6701浮点DSP在167MHz时钟频率下完成32位1024点浮点FFT的运算时间需120μs[2]。而AD公司的ADSP-21160 SHARC在100MHz下完成需要90μs。但是如果仅用于FFT处理而废弃其他功能性价比就很低。采用Xilinx公司的FFT IP核处理,也可以达到160MHz的工作频率[3],但由于其采用固核,外围引脚较多不利于使用,且不利于针对特殊要求进行修改。
本文在分析了基4按时域分解的FFT算法特点的基础上[4],提出了一种便于VLSI实现的FFT处理器结构。处理器运算单元的流水并行及操作数的并行读写保证了每个周期能够完成一次蝶形运算。而文献[5~6]提出的地址映射算法不适用于本设计单蝶形运算结构;文献[7]中,寻址方案基于线形变换,但是需要复杂的位矩阵点积算法;文献[8]方案做了改进,但仍然较复杂。本文提出一种完全同址的数据全并行FFT处理器设计方法。此方案仅需要一个计数器,通过简单的线形变换,即可实现对不同长度N=4P的FFT处理。
1 原理分析
设序列x(n)的长度为N=4P,其中p为正整数,则x(n)的DFT为:

由上述运算步骤可推得基4按时间抽取在第s级的蝶形运算单元的方程为:

其中s为基4 DIT算法流图中蝶形运算单元的级数;n=b2·4s+b1;s=1,2,…,p;b1取遍0,1,…,4s-1-1;b2取遍0,1,…,4p-s-1。
式(4)给出了DIT算法的蝶形运算公式,由此可以得出抽取数据的规律,同时也得到了每个数据在每级蝶形运算中相应的旋转因子的值,因此式(4)是VLSI实现基4 FFT算法的基础。
FFT运算中与旋转因子相乘的运算是复数乘法。可以看出,若采用并行处理" title="并行处理">并行处理方式在一个时钟周期" title="时钟周期">时钟周期内实现复乘,需4个实数乘法器" title="乘法器">乘法器和2个实数加法器。存在如下等式:

即可用3个实数乘法器和5个实数加法器实现复乘。在VLSI的实现中,阵列乘法器所占面积远大于加法器,故通常用式(5)完成复乘。
2 FFT处理器的硬件实现
假定处理器需要做N点FFT变换,则基4按时域抽取FFT运算包括lg4N级运算,每一级包括N/4个基4蝶形运算单元。
2.1 系统总体结构设计
FFT处理器设计中采用同址运算有利于系统存储器的片内集成,从而提高FFT处理器访问存储器的速度。对于基4 FFT处理器,一次蝶形运算需要读取4个操作数。因此,如能充分利用硬件的并行特点,在一个周期内并行读取4个操作数,计算速度将是顺序处理器的4倍。
在设计中,使用i、j递增计数器(i表示需要做的级数,j表示每一级运算所需的存储器容量)。由数据地址产生单元生成数据存储器地址B0、B1、B2、B3,由旋转因子地址产生单元生成旋转因子存储器地址C0、C1、C2。为了在一个时钟周期内完成一个基4蝶形运算,采用了4个并行存储器A、B、C、D存放FFT运算的操作数。系统结构框图如图1所示。

2.2 数据及旋转因子地址生成
对于N=4P,设待变化的原始数据是按顺序输入的,由式(4)可知完成的DFT变换结果是按两位二进制倒序排列的,即若输入序列的地址线每两位为一组,其序号用两位二进制表示为ap-1ap-2…a1a0,则输出结果的排序为a0a1…ap-2ap-1。每级数据及旋转因子抽取关系如表1所示。数据A0、A1、A2、A3经过当前级的地址线交换器" title="交换器">交换器后得到一个蝶形运算所对应的4个数据的地址B0、B1、B2、B3。经过蝶形运算后,数据重新写回原地址。一个基4蝶形运算需要3个旋转因子W1、W2、W3。地址B1、B2、B3经过旋转因子交换器及判决交换器(如表2所示)得到相应的旋转因子地址C0、C1、C2。读写地址及旋转因子地址的产生框图如图2所示。
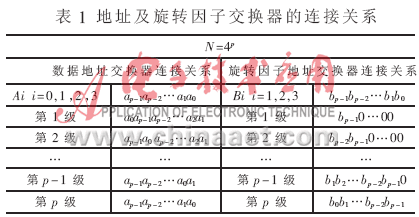

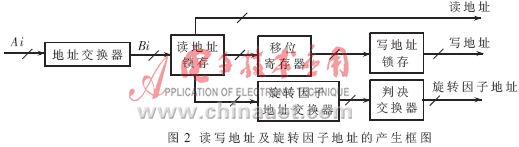
2.3 并行存储结构" title="存储结构">存储结构
设N=2n,则数据地址产生单元的输入数据Bk(k=0,1,2,3)可表示为:
Bk=bn-1bn-2…b0 (6)
得到存储器地址mq及各存储器数据地址rq对应关系为:

其中,mod表示取余运算,⊕表示多位异或运算,[·]表示对其中的数据取最近的小于其的整数,gcd(·)表示其中两个数的最大公约数。
笔者采用4对RAM(一个地址位对应一个复数,实部在前,虚部在后)来存储蝶形运算中的操作数out(0)、out(1)、out(2)、out(3)。如图3所示,数据地址为B0、B1、B2、B3。存储器分类处理单元由m1m0构成,分别得到4个地址对应数据所在的存储器号。地址交换器处理单元由rn-3rn-4…r1r0构成,分别得到4个地址对应数据所在存储器中的地址信息。处理器在每个时钟周期从相应的RAM中读取数据out(0)、out(1)、out(2)、out(3)送入基4蝶形运算单元,如图4。运算结果in(0)、in(1)、in(2)、in(3)在下一个时钟周期写回原地址。
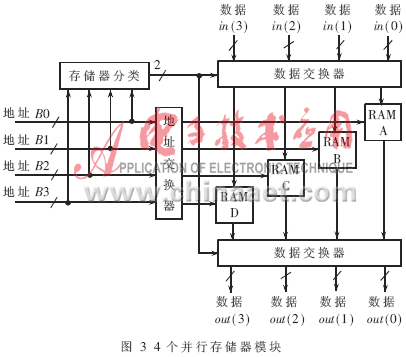
2.4基4蝶形单元
蝶形单元是FFT设计的核心部分,根据式(4)、(5)可得基4蝶形单元的结构如图4所示。它采用流水线结构[9],主要包括乘法器和加法器。蝶形运算单元可在一个时钟周期内完成一次蝶形运算。其中,4个操作数分别位于4个RAM中,3个旋转因子分别位于3个ROM中。由于运算可能产生溢出,所以需进行量化[10]。本设计在每一级蝶形运算后采用量化右移两位处理。

3 硬件设计及性能分析
针对本文提出的结构采用Xilinx公司的Virtex-Ⅱ系列的xc2v250器件进行了1024点FFT处理器的VLSI结构验证。由于此器件包含大量的18×18位硬件乘法器、片内可配置RAM块以及触发器资源,因而便于硬件设计验证。输入及输出数据为18位,当系统的工作频率为100MHz时,完成1024点复数FFT运算所需时间将近13μs。部分仿真波形如图5所示。表3比较了几种FFT处理器的性能指标。


比较表明,本文提出的基4并行存储结构控制部件简单,地址生成速度快,数据访问并行处理解决了顺序访问的瓶颈问题。对于各种形如N=4P的FFT运算能够达到极高的处理性能。
OFDM作为一种可以有效对抗信号波形间干扰的高速传输技术,引起了广泛的关注。人们开始集中越来越多的精力开发OFDM技术在移动通信领域的应用,预计第三代以后的移动通信的主流技术将是OFDM技术。OFDM技术中各载波调制解调器的实现需要高速的FFT处理器。本文在分析了基4按时域抽取FFT算法特点的基础上,提出了一种高性能的FFT处理器实现结构。利用硬件并行无冲突的方法来访问数据存储器,与以往的设计相比大大提高了处理器的处理效率。同时系统结构规则,便于模块化,易于版图设计[11]。经由硬件验证,系统性能完全可以满足OFDM对高速数据流的处理需求。
参考文献
1 http://nova.stanford.edu/~bbass/fftinfor.htm
2 http://dspvillage.ti.com/docs/catalog/dspdetails/dspplatfor-mdetails.jhtm
3 http://www.xilinx.com/ipcenter
4 刘朝辉,韩月秋.用FPGA实现FFT的研究. 北京理工大学学报,1999;19(2)
5 D Cohen.Simplified control of FFT hardware.IEEE Trans on Acoustics,Speech, Signal Processing,1976;24(12)
6 马余泰.FFT处理器无冲突地址生成方法.计算机学报,1995;18(11)
7 A.Norton, E.Melton.A classof Boolean linear transformations for conflict-free power-of_two stride access.in Proc.Int.Conf.Parallel Processing,St.Charles, IL,USA. 1987
8 D.T.Harper.Block,multistride vector,and FFT accesses in parallel memory systems. IEEE Trans.Paralel and Distrib.Syst.,1991;2(1)
9 Ayman M.El-Khashab.A Module Pipelined Implementa-tion of Large Fast Fourier Trasforms.IEEE Transaction on Signal Processing,2002;(39)
10 Knight W R,Kaiser R. A simple fixed-point error bound for the fast Fourier transform[J].IEEE Trans Acous-tics,Speech and Signal Proc,1979;27(6)
11 马维桢.快速傅立叶变化的发展现状.华南理工大学学报,1995;5