
摘 要: 为解决基于背景差分的车辆检测办法易受交通状况影响的问题,首先建立基于区间分布的自适应背景模型,然后利用改进的背景更新算法对建立的背景模型选择性更新,最后结合阈值分割和形态学处理实现运动车辆检测。实验结果表明,该算法在交通堵塞或临时停车等复杂交通环境中有很好的背景提取和更新效果。与经典的算法相比,该车辆检测算法在实时性和准确性方面都有所提高。
关键词: 车辆检测;自适应背景模型;选择性更新;阈值分割
随着智能交通技术的发展,智能交通系统中交通检测已经成为计算机视觉技术应用的一项重要课题。序列图像中车辆检测与跟踪在智能交通领域中起着关键作用。车辆检测常用的方法有基于帧间的差分办法、光流法和基于背景的差分办法。基于帧间的差分办法可以简单快速地提取出物体的运动信息,但存在检测出的运动目标位置不精确、物体在运动方向上被拉伸等问题,而且很难实现多目标检测。光流法由于噪声、多光源、阴影和遮挡等原因,计算出的光流场分布不十分可靠,且光流场的计算实时性和实用性较差。基于背景的差分办法能解决基于帧间差分办法和光流法中的问题,并且计算简单,但是背景容易受到交通环境和光强度的影响,理想的背景不容易获得,所以,自适应环境变化的背景模型对运动车辆检测的精确性起着非常重要的作用。
1 算法描述
智能交通系统是目前世界和各国交通运输领域竞先研究和开发的热点,基于背景差分的办法是从视频流中检测运动物体常用的方法,是目前研究的重点。由于受到交通状况、天气和光强度等因素的影响,不容易获得理想的背景,尤其在交通堵塞、车辆行动缓慢或者临时停车等情况下,背景更新率低。
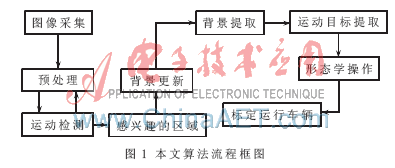
图1为车辆检测流程图。首先,建立基于区间分布的快速自适应背景模型,然后利用改进的基于ε-δ的背景更新算法对建立的背景模型进行选择性更新,结合阈值分割和形态学操作实现运动车辆的提取。该算法既保持了较高的计算效率,也保证了复杂城市交通环境中车辆检测的精确度。实验结果表明,本文提出的算法对于复杂交通环境(交通堵塞、车流量非常大、车流缓慢、交通堵塞或临时停车等情况)有很好的背景提取和更新效果,与经典的算法(混合高斯平均[1]、核密度估计[2])相比,在实时性和准确性方面都有所提高。
2 自适应背景模型
为了解决车辆检测精确度问题,国内外学者在背景建模方面做了大量的研究[3]。参考文献[4]利用视频图像中最近N帧的像素点的平均值的作为背景模型,这种方法在多个运动目标或者运动目标行动缓慢时,背景会被前景目标污染。参考文献[5]利用前几帧的像素分布建立高斯分布模型,对于频繁变化的像素,需要多个高斯混合分布[6]才能反映背景像素的变化。这些方法要求在背景模型的建立过程中没有运动车辆并且建立背景模型的时间较长,不能满足实际应用的需要。本文提出简单有效的背景模型和更新的方法。
2.1 背景模型的建立
在视频图像序列中,可以统计出每个坐标点像素值的分布,并设定出现频率高的像素值作为背景模型中对应点的像素值。但是这种方法计算量比较大,并且对光线和背景的逐渐改变适应性差。

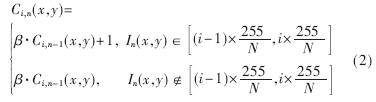
在定义了ui(x,y)和Ci(x,y)后,建立背景模型的细节步骤如下:
(1)确定当前像素属于哪个区间,设定为i。
(2)计算ui(x,y)和Ci(x,y)。
(3)根据Ci(x,y)把区间从小到大分类。
(4)设定Ci(x,y)最大的区间的ui(x,y)作为背景模型Mt中对应点的像素值。
(5)对视频流各帧所有像素点重复步骤(1)~(4)。
2.2 背景模型更新
经过上述几个步骤,得到能自适应光强度变化的背景模型。但在车辆拥挤、临时停车或者车辆运动缓慢的情况下,背景模型容易出错,导致车辆检测准确性降低。为了在复杂交通状况下也能得到理想的背景模型,论文在传统σ-δ背景更新方法[7]基础上提出了一个是否更新背景模型的判断尺度。


3 运动目标提取
在获得重建的背景之后,可以根据当前图像和背景图像的差值求得运动目标。背景差图像为D(x,y)=I(x,y)-B(x,y)。图像中所有低于这一阈值的像素集将被定义为背景, 而高于这一阈值的像素集定义为运动目标。采用归一化的方法,即低于阈值的赋0值, 高于阈值的赋1值。不论以何种方式选取阈值, 取单阈值分割后的图像可定义为:

阈值分割的核心是阈值的选取问题。若阈值选取过大,会使车辆的某些部分被认为是背景,使得车辆图像残缺,获得的车辆信息不准确;若阈值选取过小,由于光照的原因形成的阴影会和车辆粘连在一起,变成了车辆的一部分。因此选取合适的阈值对运动车辆部分准确地提取出来非常关键。
本文选取基于最大方差理论的大津法作为视频车辆检测中阈值分割的处理算法。取阈值将物体从背景中分离出来,实际上就是将图像中的所有像素分为2组,或属于物体像素,或属于背景像素。由概率论中的理论得知,若使待分割的2组数据方差最大,则得到2组数据的错分概率最小。
经过阈值分割已经能够成功地分割出运动车辆。大津法分割得到的二值图像仍然在车辆内部存在黑色像素点的问题。为了使检测到的运动目标完整而连续,对背景帧差法得到的二值图像进行形态学膨胀与腐蚀。实验证明,经过三次膨胀与腐蚀之后的图像,可以基本填补运动目标的空洞。
4 实验结果
本文以智能交通中车辆自动监视系统为应用背景,通过实验证明提出方法的正确性。使用固定在三脚架上的摄像机在室外摄取不同场景的视频进行实验。实验平台为PC机Matlab7.0仿真。
图3为自适应背景模型的提取。选取特殊的临时停车情况,本文提出的算法能够自适应提取出背景模型。本文提出的算法在第621帧时能够得到理想的背景模型,如图3所示;而利用高斯分布提取背景模型的方法则在1 460帧时才能获得如图所示的理想的背景模型。所以该算法比传统的算法在计算速度上有所提高,能够实时性地检测出运动车辆。

图4为一段城市交通视频,图5为城市交通视频中临时停车情况,其中左下角为原始视频,右下角为本文算法提取的背景模型,左上角为检测出的运动物体,右上角为标定检测出的运动车辆。图4分别取了城市交通视频的第59帧和第114帧,图5选取了第618帧和第673帧,可以看出在繁忙的城市交通中,本文提出的算法能够准确地检测出运动车辆。

从图4中可以看出在城市交通场景中运动车辆能够实时地提取出理想的背景模型。通过背景差分办法并结合阈值分割和形态学操作,精确地得到了运动区域。
从图5可以看到临时停车时,能够准确提取出背景模型。当车辆经过短暂的停车又并入车流时,背景中这个车辆慢慢变得模糊,而且在运动目标提取时提取了该车辆。说明该算法能够在提高计算速度的同时保证检测精确度。

本文以背景模型的建立和选择性更新为基础实现车辆检测。为了适应快速改变的交通环境,本文提出一个自适应的背景模型算法。在建立自适应背景模型后,利用灰度图像与背景模型差分实现运动目标提取。结合基于最大方差理论的大津法求取阈值进行阈值分割,最后利用形态学膨胀和腐蚀操作填补阈值分割后运动目标的空洞,标定出视频图像中的运动车辆。仿真实验证明,提出的算法在像素水平上建立自适应光强度等环境变化背景模型,同时估计交通流量的大小,通过对交通流量的估计判断是否更新背景模型。本文提出的算法对于复杂交通环境(交通堵塞,车流量非常大,车流缓慢,交通堵塞或临时停车等情况)有很好的背景提取和更新效果,并且能实时精确地提取出运动车辆的完整信息。
参考文献
[1] CUCCHIARA R, GRANA C, PICCARD M, et al. Detecting moving objects, ghosts,and shadows in video streams[J]. IEEE Trans.Pattern Anal. Mach. Intell., 2003,25:(10):1337-1342.
[2] MITTAL A,PARAGIOS N.Motionbased background subtraction using adaptive kernel density estimation[J].Proc.IEEE Conf. on Computer Vision and Pattern Recognition, 2004,2:302-309.
[3] PICCARDI M. Background subtraction techniques:a review[J]. Proceedings of IEEE International Conference on Systems, Man,and Cybernetics.Hague,Netherlands:IEEE,2004:3099-3140.
[4] WANG Xing, PAN Shi Zhu. Real time detection of moving object in video surveillance system[J]. Microcomputer and Its Application, 2004(156):47-49.
[5] ZHAO Ming, LI Na, CHEN Chun. Statistical inference for automatic video segmentation[J].Computer-aided Design and Computer Graphics,2005(36):318-323.
[6] COLOMBARI A, FUDIELLO A, MURINO V. Segment and tracking of multiple video objects [J].Pattern Recognition, 2007,40(4):1307-1317.