
一种改进Turbo码译码器的FPGA设计与实现
2008-10-17
作者:赵旦峰,罗清华,焉晓贞
摘 要: 提出了一种基于MAX-Log-MAP算法的更有效减小译码延时的方法,通过并行计算前向状态度量和后向状态度量,将半次迭代译码延时缩短一半,而译码性能没有损失,同时也减小了硬件实现" title="硬件实现">硬件实现中的时序控制" title="时序控制">时序控制复杂度。仿真表明,该方法有效降低了译码的延时,并且性能没有损失,具有较高的实用价值。
关键词: Turbo码;MAX-Log-MAP;FPGA
Turbo码又称并行级联卷积码(PCCC),1993年由Berro等人在ICC国际会议上提出。由于其充分利用了Shannon信道编码定理的随机化编码条件,因此获得几乎接近Shannon理论极限的译码性能[1]。
Turbo码在低信噪比应用环境下的优异性能,使得其在很多通信系统中拥有非常好的应用前景。第三、四代移动通信系统的多种方案,都将Turbo码作为信道编码的方案之一。但是,Turbo码存在着译码时延长、硬件实现复杂度高的问题,这使得其实现和应用都受到了一定的局限。人们也推出了一些减小译码延时的译码方法,例如分块并行、滑窗等方法。但是这些译码方法对应的译码性能有损失,而且在硬件实现上控制时序也比较复杂。本文给出了一种更加有效减小译码延时方法,其译码性能没有性能损失,硬件实现时的时序控制相对简单,存储空间也有一定的减少。
1 改进译码方法
成员译码器" title="译码器">译码器(DEC1,DEC2)首先根据输入的外信息和接收到的信息序列进行正向(按帧长从前向后的顺序)分支度量值计算和前向递归" title="递归">递归计算,同时进行反向(按帧长的逆序)分支度量值计算和后向递归计算。当正向递归计算和反向递归计算到帧长一半(N/2)时,进行正向对数似然比计算和反向对数似然比计算,同时计算出对应的外信息经过交织后作为另一个成员译码器的输入先验信息。
这样每半次迭代过程可分如下二个步骤进行:
(1)第一步:DEC正向分支转移度量γk计算和DEC前向递归αk计算[2][3],同时进行反向分支转移度量γj计算和DEC后向递归βj计算:

其中:s′为前一状态,s为后一状态,k为对应的状态数,uk为编码的信息位,xk,v为校验位,yk,l为接收到的信息位,yk,v为接收到校验位,Ak为一个常数,Lc为信道可信度。同时进行前向递归:

对于β的初始化,如果编码在每帧编码之后通过加入归零比特使编码状态回到零状态。则可初始为:

这里v为编码成员码中寄存器的个数。
(2)第二步:正向对数似然值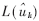 计算和反向对数似然比
计算和反向对数似然比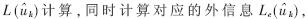 然后进行交织:
然后进行交织:
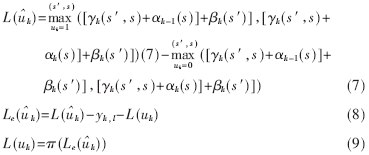
其中π()为交织函数。
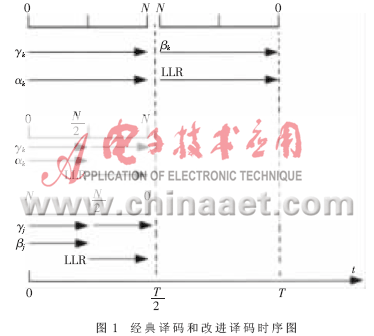
经典译码和改进译码方法的半次迭代(一个子译码的译码过程)对应的时序图如图1所示。由图1可知对应半次迭代译码延时为T,图中下半部分是改进的译码时序,改进的译码延时为T/2。这种新的译码方法能将译码延时缩短一半。由于在整个计算过程中没有采用任何近似计算,所以译码性能没有任何损失。在计算过程中,不需要对γk(s′,s)进行存储,从而减少了在硬件实现时所需的存储容量。
2 与其他译码方法的比较
为了减小译码延时,人们推出了分块并行译码算法" title="译码算法">译码算法、滑窗译码等方法。它们都采用了相应的近似计算,从而在译码性能上或多或少有些损失,它们都是通过牺牲译码性能来换取减小译码延时的,同时它们硬件实现时的时序控制也比较复杂。
分块并行是将接收的整个码字分成若干子块[4][5],各子块进行并行处理,其中各子块的前后向递推公式的初始值由相邻子块的前一次迭代译码的边界计算值传递,这样就引入了近似计算,译码性能就有一定损失。设经典半次迭代译码延时为T,分块的块数为M,则分块并行译码方法的译码延时为T/M。但是,由于它的控制时序很复杂,因而硬件实现复杂度较高。
对于滑窗译码方法而言[6][7],它通过预先递推一段后向递归量作为真正计算后向递归的初值,也采取了近似计算,因而译码性能也有一定的损失。设经典半次迭代译码延时为T,则滑窗译码方法的半次迭代译码延时为:(T/2+T/(2×N/W)),因而其时序控制很复杂,但是这种方法能很大程度上节省存储容量。
本文采用的译码方法的译码延时为T/2,译码延时能节省一半,更主要的是其译码性能没有任何损失,而对应的时序控制也相对简单,更有实际应用价值。
3 几种译码方法的仿真比较
对经典译码方法、分块并行方法分别做了仿真。仿真参数:生成多项式为G=(15,13),交织采用3GPP随机交织,译码算法为MAX-Log-MAP,码率为1/3,迭代次数为4和6,调制采用BPSK,信道采用AWGN,帧长为1 024,分块并行方案中分4块并行译码。仿真图如图2所示。
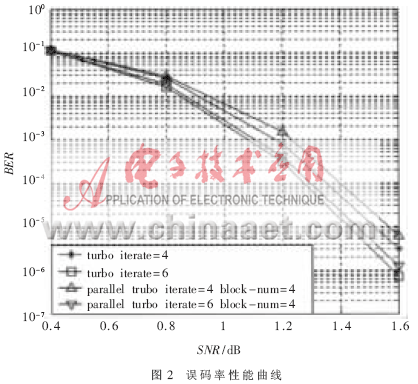
图2中上面两条分别是分块并行和改进译码算法迭代4次的误码率性能曲线,从图中看出分块并行译码算法有性能损失;下面两条是分块并行和改进译码算法迭代6次的误码率性能曲线,对应的分块并行也有性能损失。但是随着迭代次数的增加,两种译码方法的性能差别逐渐减小。由图2分析可知,本文采用的译码方法的译码性能与经典的译码方法一样,没有性能上的损失,在译码性能上优于分块并行和滑窗译码方法,在减小译码延时优于滑窗译码方法,但比分块并行差。
4 硬件实现方案
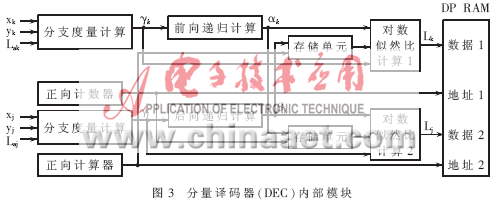
分量译码器(DEC)内部结构图如图3所示。首先从存储器中顺序读出系统信息序列Xk,校验序列Yk和先验信息Lak,进行正向分支度量γk计算和前向递归αk计算并存储,如图3中上半部分所示。同时,从存储器中逆序读出系统信息序列Xj,校验序列Yj和先验信息Laj,进行反向分支度量γj计算和后向递归βj计算并存储,如图3中下半部分所示。另外还设置正向计算器和反向计算器,计数器对并行运算长度进行计数,并将计数结果作为地址来存储计算结果。等计数值达帧长的一半时,对数似然比计算1模块根据已经计算出并存储的后向递归βj,当前计算出的分支度量γk和前向递归αk进行对数似然比计算,并存储计算结果。同时对数似然比计算2模块根据已经计算出并存储的前向递归αk、当前计算出的分支度量γj和前向递归βj进行对数似然比计算,并存储计算结果。这里采用双口RAM实现对数似然比的存储,双口RAM的两个口可以在地址不冲突的情况下,进行同时写操作。在硬件实现的过程中,不用对分支度量进行存储,从而节省了存储单元。当然由于多加了分支度量计算单元和对数似然比计算,增加了资源,但是从减小译码延时并且译码性能不损失角度考虑,这是非常值得的。
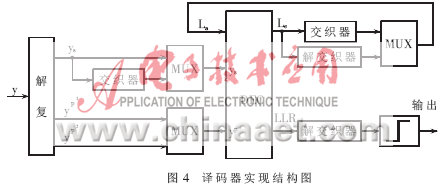
为了进一步节省硬件资源,考虑到两个分量译码器是分时工作的,这样可以进行分量译码器的复用。整个译码器实现结构图如图4所示。当然译码器的实现还需要对应的控制子系统,用于使各个子模块协调有序地工作。这样系统实现的硬件资源就大大减小,译码延时也大大缩小。从而达到高速数据通信的目的。
5 硬件实现
基于以上介绍的硬件实现结构,对Xilinx公司的Virtex2pro系列的FPGA芯片进行了配置,采用的是帧长为2 060、1/2码率的Turbo码;译码部分采用MAX-Log-MAP译码算法,其中输入数据流采用8bit(其中1bit符号位,4bit整数位,3bit小数位4)量化;内部计算采用12bit(其中1bit符号位,8bit整数位,3bit小数位4)量化;迭代6次译码。运用XilinxISE8.2i对2vp30ff896-7进行了综合实现,资源消耗如图5的综合报告所示,最大时钟可达到112.331MHz。仿真工具采用Modelsim SE 6.0进行仿真,布局布线后仿真波形图如图6。


为了在不损失译码性能的前提下减小译码延时,本文提出了改进的Turbo码译码方法,通过前向递归和后向递归并行计算,等计算到帧长一半时,开始同时进行前向对数似然比计算和后向对数似然比计算的译码方法。该方案可以将译码延时缩短一半,译码性能没有损失,能节省硬件实现所需的存储单元,时序控制比较简单,更易于硬件实现。仿真结果表明:这种译码方法在性能上优于分块译码算法和双滑窗译码算法。在减小译码延时上优于双滑窗译码算法。这个方案在中短帧长、对译码延时、译码性能要求高的通信系统中有较高的实用价值。
参考文献
[1] BERRON C,GLAVICUS A,THITIMAAJSHIMA P.Near Shannon limit error-crrecting coding and decoding:Turbocodes[A].Proc ICC′93[C]:1993,1064-1074.
[2] 刘东华.Turbo码原理与应用技术[M].北京:电子工业出版社,2004.
[3] 王新梅,肖国镇.纠错码—原理与方法[M].西安:西安电子科技大学出版社,2001.
[4] HSU J,WANG C.A parallel decoding scheme for turbo codes Pro ISCAS′98[C].1998,6:445-448.
[5] 赵旦峰,李文意,杨建华,等.分块并行Turbo码译码算法的研究[J].哈尔滨工程大学学报,2004,25(2).
[6] GIULIETTI A,BOUGARD B.TURBO CODES Desirable and Designable[M].Kluwer Academic Publishers,2004:63-67.
[7] VUCETIC B,YUAN J H.TURBO CODES principle and Applications[M].Kluwer Academic Publishers,2000.