
基于数据挖掘的分布式入侵检测系统
2008-11-13
作者:孙鑫鸽, 赵跃龙
摘 要: 构建了一个基于数据挖掘" title="数据挖掘">数据挖掘的分布式入侵检测" title="入侵检测">入侵检测系统模型。采用误用检测技术与异常检测" title="异常检测">异常检测技术相结合的方法,利用数据挖掘技术如关联分析、序列分析、分类分析、聚类" title="聚类">聚类分析等对安全审计数据进行智能检测,分析来自网络的入侵攻击或未授权的行为,提供实时报警和自动响应,实现一个自适应、可扩展的分布式入侵检测系统" title="入侵检测系统">入侵检测系统。实验表明,该模型对已知的攻击模式具有很高的检测率,对未知攻击模式也具有一定的检测能力。
关键词: 入侵检测; 数据挖掘; 网络安全
随着Internet在全球的迅猛发展,网络上的各种攻击层出不穷,已成为网络和信息的主要威胁。目前解决网络安全采取的主要技术手段有防火墙、安全路由器、身份认证等,这些技术在抵御网络攻击中发挥了重要作用,但是这些安全产品大多属于静态安全技术的范畴,虽然对防止系统非法入侵起到了重要作用,但从安全管理角度来说,仅有防御是不够的,还应采用动态策略。入侵检测技术就属于一种动态策略,它可以弥补防火墙等静态安全技术的不足,为网络系统提供实时的入侵检测以及必要的防护手段,如记录证据、跟踪入侵、恢复或断开网络连接等。
1 入侵检测技术
入侵检测(intrusion detection)是指用于检测任何损害或企图损害信息系统的完整性(integrality)、机密性(confidentiality)和可用性(availability)的一种网络安全技术[1]。入侵检测技术主要有两类:异常检测(anomaly detection)和误用检测(misuse detection)[2]。
1.1 异常检测模型
异常检测是从审计记录中抽取一些相关量进行统计,为每个用户建立一个用户扼要描述文件,即建立一个用户正常行为的特征模型,然后将用户或系统的实测模型与正常模型进行比较,若两者的差异超出指定的阈值,就说明可能发生了入侵或攻击行为。图1是一个典型的基于异常检测的IDS模型。异常检测的优点是可以检测未知类型的入侵行为,而缺点是误报率高。常用的检测方法有统计分析、神经网络、计算机免疫学和数据挖掘技术等。

1.2 误用检测模型
误用检测是指通过对已知的攻击方式或系统的弱点进行建模,然后将与预先精确定义好的入侵或攻击模式相匹配的行为确定为入侵或攻击。图2是一种典型的基于误用检测的IDS模型。误用检测的优点是可以有效地检测到已知的攻击,精确度高,而缺点是对新的入侵行为无能为力,漏报率高。常用的检测方法有模式匹配、专家系统、模型推理、状态转换分析和Petri网等。

1.3 传统入侵检测模型的局限性
传统的网络入侵检测系统的建立,通常由安全专家分析攻击行为,归纳出攻击特征,然后经过手工编码建立入侵检测所需规则,用于识别入侵。构造丰富、精确的入侵特征知识库相当复杂,同时IDS需要不断更新自己的知识库,以适应不断出现的新攻击类型或已有攻击类型的新形式。传统的使用纯手工方式编码的IDS不仅效率低下,而且限制了入侵检测系统的自适应性和可扩展性。另外,由于入侵者可以对检测系统进行训练,逐渐改变系统中用户的活动记录,使得最初被认为是异常的行为,经过一段时间训练后被认为是正常的,这样极容易出现误报、漏报问题。为了克服传统IDS的缺陷,将数据挖掘技术[3-4]引入到入侵检测中,利用数据挖掘在处理海量数据方面的优势,可以从大量的审计记录中挖掘出正常和入侵行为模式,自动生成规则,省去了人工编写规则的开销,从而生成一种准确的检测模式,以提高检测准确率,降低误报率。采用数据挖掘技术的入侵检测系统在自适应性和可扩展性方面都有较好的表现。
2 数据挖掘技术
数据挖掘DM(Data Mining)又称数据库中的知识发现KDD(Knowledge Discovery in Database),是指从大型数据库或数据仓库中提取隐含的、未知的、异常的及有潜在应用价值的信息或模式。它是数据库研究中的一个很有应用价值的新领域,融合了神经网络、遗传算法、规则推理、决策树、人工智能和数据库系统等多门技术。将DM技术应用于入侵检测研究领域,其思想是:从审计数据或数据流中提取感兴趣的知识,这些知识是隐含的、事先未知的潜在有用信息,提取的知识表示为概念、规则、规律、模式等形式[5],并用这些知识去检测异常入侵和已知的入侵。目前应用于入侵检测系统中的数据挖掘算法主要有关联分析(associations analysis)、序列分析(sequence analysis)、分类分析(classification analysis)、聚类分析(clustering analysis)等算法[6]。
2.1 关联分析算法
关联规则是描述数据集中的各项出现规律的知识模式。关联规则分析的目的是挖掘出隐藏在数据集中的各项之间的相互关系。在入侵检测系统中,使用关联规则时一般用支持度和置信度两个阈值来度量关联规则的相关性。使用关联规则挖掘过程可分为:高频繁挖掘和低频繁挖掘两步。高频繁挖掘是指找出大于等于一定支持度和置信度的频繁属性集,通过高频繁挖掘就能检测出攻击频繁的异常行为,如DDOS攻击等;低频繁挖掘是指找出支持度低于一定阈值而置信度大于一定阈值的数据记录集,通过低频繁挖掘能检测攻击不频繁的异常行为,如慢扫描在单位时间内异常扫描较少,如果只检查高频繁数据,就会漏掉检测此类攻击。常见的关联分析算法有Apriori、Apriori Tid、AIS等算法。
2.2 序列分析算法
序列分析算法是指通过时间序列搜索出重复发生概率较高的模式规则,是用己知的数据预测未来的值,侧重于事件的时间先后关系。这类算法可以发现频繁发生的事件序列,这些频繁事件序列是反映用户或程序行为模式的重要因素。运用该算法找出入侵行为的序列关系,从中提取出入侵行为之间的时间序列特征。它与关联分析算法共同形成规则集。序列分析的代表算法是AprioriAll、Apriori Some、PSP、GSP等。
2.3 分类分析算法
数据分类的目的是提取数据项的特征属性,生成分类模型,然后将数据项映射到预先定义好的分类中去。分类算法可以用规则集或决策树的形式表示,一个理想的分类算法必须收集足够的“正常”或“不正常”的数据来判定一个用户或者程序是否合法。利用分类算法,可以对关联分析算法和序列分析算法得到的规则集进行学习,挖掘出新的规则。用于入侵检测时,可以使用分类算法得到规则集来判断新的数据属于正常还是异常行为。数据分类的处理步骤如下:首先获取训练数据集,该数据集中的数据记录具有和目标数据库中数据记录相同的数据项;然后训练数据集,训练数据集中每一条数据记录都有已知的类型标识与之相关联;接着分析训练数据集,提取数据记录的特征属性,为每一种类型生成精确的描述模型;最后使用得到的类型描述模型对目标数据库中的数据记录进行分类或生成优化的分类模型。常用的分类分析算法有CART、ID3、C4.5、SLIQ、NaiveBayes、神经网络等。
2.4 聚类分析算法
聚类分析是识别数据对象的内在规则,将对象分组以构成相似对象类,并导出数据分布规律。分类与聚类的区别在于分类是将分类规则应用于数据对象;而聚类是发现隐含于混杂数据对象的分类规则。聚类分析算法是一种无监督异常检测的算法,该算法不需要训练数据,只要带有各种属性的数据记录,通过计算不同记录的属性差别,把类似的记录聚集在一起,然后利用距离矢量来判断哪些是异常记录即攻击数据。常见的聚类分析算法有PAM、CLARA、BIRCH等。
3 基于数据挖掘的分布式入侵检测系统
根据入侵检测系统和数据挖掘技术的特征,本文设计的基于数据挖掘的分布式入侵检测模型如图3所示。其基本组件包括检测引擎、决策引擎、响应引擎、数据预处理器、规则库和决策库等。
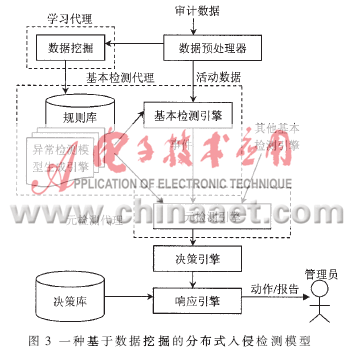
3.1 数据预处理模块
入侵检测中的数据来源于网络传感器收集的网络中的大量数据包和主机传感器收集的本地主机系统生成的日志,其计算量十分庞大,因此必须先进行数据预处理。
数据预处理主要是将采集来的大量原始数据经过数据清理与集成、数据选择与变换、相关性分析(特征选择)、离散化和概念分层等几个过程,实现标准化数据、处理数据遗漏、消除脏数据、纠正数据中的不一致、存储合并数据,最后将数据转换成适合数据挖掘的形式。
由于数据分析的准确性不仅仅取决于所采用的算法,在很大程度上依赖于所处理的数据的质量, 因此该模块对整个系统起着举足轻重的作用。
3.2 数据挖掘模块
数据挖掘模块是系统的核心部件。针对传统的入侵检测技术,无论是异常检测还是误用检测,都需要专家手工编码输入入侵模式或是正常行为模式,其代价很大。因此,本系统综合使用了几种数据挖掘算法来进行分析。
在有可以利用的已标记的训练数据时,采用数据挖掘算法中关联分析、序列分析及分类分析的算法来提取特征和检测模式。采用关联分析算法和序列分析算法挖掘连接记录数据库中的频繁模式,如关联规则和频繁序列。利用这些频繁模式,为连接记录构造附加特征,如时间统计特征、主机统计特征等。通用的数据挖掘算法通常会产生大量的无用模式,为了消除这些无用模式,引入了“轴属性”和“参考属性”[7]的概念。最后将分类分析算法应用于处理后的审计数据得到一个分类器,即入侵检测模型,用来判断当前用户行为正常或入侵。
在无训练数据时,则从数据库中提取未标记数据,利用聚类算法进行聚类,把数据标记为正常或攻击数据,并送回数据库构成训练数据集。其他挖掘算法则可利用这些标记好的数据进行分析。
3.3 检测引擎模块
检测引擎分为基本检测引擎和元检测引擎两种。基本检测引擎提供采用特定检测方法的检测机制,而元检测引擎负责汇总来自各个基本检测引擎的所有信息。两种检测引擎区别在于基本检测引擎以预处理的审计数据作为输入,而元检测引擎是以各个基本检测代理产生的入侵证据作为输入。通过元学习[8]、元检测模型把多个基本检测模型的检测能力综合起来,将结果提交给决策引擎,由决策引擎做出最后的决策。
异常检测模型是根据大量数据生成的动态模型,其形态在一段时间内可以是稳定的,但不断的调整和优化也是必要的。
3.4 决策响应模块
构造的模型对当前审计数据进行检测,根据检测的结果,从决策库中寻找匹配决策,执行相应的行动。如果属于入侵行为,则系统给出警报,并采取一定的措施,如断开网络连接、报告系统管理员等,并留下入侵证据;如果属于正常行为,则系统继续进行监视。
4 实验结果及分析
下面以SYN Flood攻击方式为例来介绍数据挖掘是如何在入侵检测中起作用的。
SYN Flood是当前最流行的拒绝服务攻击(DoS)与分布式拒绝服务攻击(DDoS)的方式之一,这是一种利用TCP协议缺陷,发送大量伪造的TCP连接请求,从而使得被攻击方资源耗尽停止响应的攻击方式。
当TCP连接进行三次握手时,如果一方发出SYC+ACK应答报文后无法收到ACK报文的回应,这种情况下一般会重试。在一定的时间窗体内保持连接,这段时间的长度称为SYN Timeout,这个时间窗一般是半分钟到一分钟;但如果有恶意的攻击者大量模拟这种情况,服务器将忙于处理攻击者伪造的TCP连接请求而无暇理睬客户的正常请求,从正常用户的角度看来,服务器不再响应正常请求,这时发生了SYN Flood攻击。
应用本文提出的基于数据挖掘的分布式入侵检测系统模型检测SYN Flood攻击,首先通过TcpDump等工具进行原始网络数据的采集,并对数据处理形成一条条连接记录的形式,每条记录都包括一系列网络相关属性,如连接的开始时间、服务类型、源主机、目的主机、源端口号、目的端口号接口、标志等属性(分别用timestamp、service、src_host、dst_host、src_port、dst_port、flag表示),
网络连接记录如表1所示。然后提取特征标志,为数据挖掘做准备。例如应用数据挖掘中的关联规则和频繁事件算法,以service作为轴属性,dst_port作为参考属性,得到一组关于相同目的主机的频繁时序“服务”模式[8]。得到的特征模式如下:
模式1:(service=telnet,src_host=A)→(flag=SF),[0.89,0.03,2]
模式2:(service=http,flag=S0),(service=http,flag=S0)→(service=http,flag=S0),[0.89,0.03,2]

把这些模式与正常模式集相比较,在正常模式集中不存在flag=S0的模式,所以模式2可以作为攻击模式。对攻击模式进行特征建立与提取,去掉所有标志不是SYN的记录,得到基于统计的特征。例如:在2秒内相同目的主机的连接数中有相同服务连接的百分比及状态flag为S0百分比等。最后使用聚类分析算法,聚集属于SYN攻击的记录,并从中提取出SYN Flood攻击的规则。把数据挖掘发现的新规则加入规则库中,发现新规则的加入降低了SYN Flood攻击的误报率。实验是从经过数据预处理之后的数据中抽出了总数为20 000个待分析的记录进行聚类,整个数据集被划分为7个聚类,每个聚类中含有正常数据和攻击数据的记录个数,如表2所示。从表中可以看出,聚类2、5、6发生了入侵攻击。从入侵检测的角度来分析实验结果,检测为攻击的攻击数据占所有攻击数据的比重为检测率,检测为攻击的正常数据占所有正常的比重为误报率。分别计算出这种方法的检测率为96.44%,误报率为3.19%。通过分析数据可以看出,利用数据挖掘算法可以有效地将正常数据与攻击数据区分开来,并具有很好的准确性。

本文提出的基于数据挖掘的分布式入侵检测系统模型,采用检测代理与学习代理分离的方式,从而使多个检测代理可以并行执行,提高了系统执行的效率,审计数据也不必传输到中央检测服务器集中检测,降低了网络中数据的传输量。另外,入侵检测系统通过采用异常检测技术的基本检测代理挖掘新的入侵模式,并把审计记录传输到学习代理,然后计算获得一个可以检测此类入侵的更新了的分类器,再将它分派给所有的基本检测代理,这种将异常检测和误用检测结合的方式,可以提高检测效率和检测准确度,降低漏报率和误报率。入侵检测系统由于其分布式结构可以灵活地在网上进行配置,从而提高了检测分布式协同攻击的能力,提高了系统的可扩展性和自适应性。
参考文献
[1] YU J, REDDY Y, SELLIAH S, et al. Trinetr: an architecture for collaborative intrusion detection and knowledge based alert evaluation[J].Advanced Engineering Informatics,2005,(19):93-101.
[2] NOEL S, WIJESEKERA D, YOUMAN C. Modern intrusion detection, data mining, and degrees of attack guilt.Applications of Data Mining in Computer Security, edited by D. Barbar’s and S. Jajodia, Kluwer Academic Publishers,2002.
[3] YE Nong,VILBERT S, CHEN Qiang. Computer intrusion detection through EWMA for autocorrelated and uncorrelated data[J]. IEEE Transactions on Reliablility,2003,52(1):28-32.
[4] GANGER G R,NAGLE D F. Better security via smarter devices[A]. Hot Topics in Operation Systems[C].[s.l.].IEEE,2001:100-105.
[5] LEE W,STOLFO S,MOK K.A data mining framework for adaptive intrusion detection. Http://www.cs.columbia.edu/~sal/hpapers/framework.pd.gz,1999.
[6] LEE W,STOLFO S J,MOK K W. A data mining framework for building intrusion detection models[A].In Proceedings of the 1999 IEEE Symposium on Security And Privacy[C].Oakland,CA:[s.n.],1999.
[7] LEE W, STOLFO S J. A framework for constructing features and Models for Intrusion Detection Systems[J].ACM Transactions on Information and System Security,2000,3(4):227-261.
[8] 马恒太.基于Agent分布式入侵检测系统模型的建模及实践[D]. 北京:中国科学院出版社,2000.