
文献标识码: A
文章编号: 0258-7998(2010)12-0039-03
传真服务器是随着通信技术的发展,针对大中型企业、机关需求推出的一种集团传真通信解决方案。它的基本原理是通过软硬件集成,实现多路传真的并发收发,并在此基础上,与办公流程相结合,实现更复杂的自动化管理。
目前的传真服务器,其主要业务是实现传真的收发管理,但是不具备安全功能,因此很容易成为垃圾传真的攻击目标,尤其是一些大企业,其号码为公众所熟悉,更是垃圾传真的重灾区。垃圾传真的泛滥不但造成巨大的浪费,而且严重影响正常办公。
针对上述问题,本文提出一种安全传真服务器的概念,在传真服务器上增加垃圾传真的自动检测功能,从而使分发或打印的传真都是安全有效的。
1 安全传真服务器模型
文献[1]、文献[2]等给出了传真服务器的实现方法。为实现安全传真服务器,需要在原来的传真服务器上增加传真自动分类功能,只对无害的传真进行分发,而将垃圾传真剔除。一种直观的方法是在分发之前增加内容的机器识别功能,如对传真图像进行OCR[3](光学字符识别)识别,得到传真图像的文本字符信息,在此基础上进行文本分类。但是受限于传真的实际情况,如手工发送造成的版面倾斜、手写字体等,如果直接对其进行OCR识别,较低的准确率会严重影响系统的可用性,为此,需要对垃圾传真的特征进行全面研究及利用,确保分类方法的有效性。
垃圾传真通常是将一份传真进行广播式发送,因此在传真服务器的接收端,垃圾传真重复严重,而正常业务传真则没有此特征。所以本文的方法是对接收到的传真进行聚类处理,能够聚类的认为是垃圾传真,不能聚类的认为是正常业务传真。根据上述分析,得到安全传真服务器的系统模型,如图1所示。与传统的传真服务器相比,本服务器在传真分发前,增加了对垃圾传真的聚类检测功能。为达到最佳的检测效果,且避免垃圾传真因数量少而不能聚类,增加了垃圾传真的历史特征库。

2 垃圾传真检测算法
由安全传真服务器系统模型可见,调制解调、编码解码、传真收集与分发等都属于普通传真服务器具有的功能,相关资料中已有说明,本文不再重复,这里只详细介绍其中的垃圾传真检测算法。
本文中的应用对精确度要求很高,不允许将正常业务传真识别为垃圾传真,所以需要选取一种能够精确表达传真内容的特征进行聚类,本文采用传真的游程[4]特征。
每幅传真图片的黑白像素分布不同,从每一扫描行的图像数据上看,这种不同体现在黑像素和白像素的分布上,即交替的次数不同,且连续黑白像素点的长度也不同。将此特征以游程数M和游程值L来描述,游程数是指每个扫描行黑白像素变化的次数,游程值是指每个连续像素段的像素个数。假如某一行的像素为00001111110011000,则该扫描行的游程特征为:M=4,L0,…,M=(4,6,2,2,3)。将所有的传真图像以此特征来描述,并进行比较,即可实现相同传真图像的聚类。传真图像与游程特征的对比如图2、图3所示。

正常业务传真在聚类过程中可以认为是孤立点或者噪声点,大量重复的垃圾传真或者广告传真是本文聚类的对象。基于密度的DBSCAN[6]聚类算法能够对抗孤立点,并且能够处理任意形状和大小的类,因此这里选择DBSCAN算法。DBSCAN算法提出了一些新的定义:
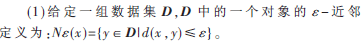
(2)如果一个对象的?着-近邻中至少包含MinPts个对象,则称这个对象为核对象。
(3)如果对象P为另一个对象q的ε-近邻且q是核对象,则称p是从q可“直接密度可达”(Density-Reachable)。
(4)如果存在一系列对象p1,p2,…,pn,其中p1=q,pn=p,而且pi+1(1≤i≤n-1)是从pi“直接密度可达”的,则称p是从q可“密度可达”。
(5)若存在一个对象z,使得p和q都是从z“密度可达”的,则称对象p“密度连接”对象q。
DBSCAN聚类算法就是检查数据库中每一个点的ε-近邻。若一个对象p的ε-近邻包含MinPts多于个对象,则创建包含p的聚类。然后DBSCAN根据这些核对象,循环搜索“直接密度可达”的对象,当各聚类中再无新对象加入时,聚类结束。
聚类算法的具体实现需要考虑如下因素:
(1)要判断两个图像是否相同,只需要判断有限个扫描行数据相似度大小即可。如果对整个图片进行特征比对,会严重增加存储和计算开支。
(2)正常情况下传真都含有页眉,页眉涉及时间、主叫等信息,即使重复发送的垃圾传真,页眉显示的时间也不相同,所以比较传真时应当避开页眉。
(3)在聚类处理的时段内,垃圾传真如果数量少就会因为不能聚类而漏检,为此,应该建立已知垃圾传真特征库,供后续检测使用。
基于上述考虑,聚类算法实现过程如下:
(1)分类器训练:利用训练数据,采用最小方差准则对?着、MinPts等聚类参数进行确定。
(2)提取每个传真图片的游程特征C[i]:设定起始行Srow(如Srow=20),从此行向下搜索,找到有效图像扫描行,作为新的起始行,从起始行开始,提取有限行Mrow(如Mrow=80)游程特征。
(3)确定垃圾传真类:遍历所有传真,若一个传真的ε-近邻中至少包含MinPts个传真,就创建包含这个传真的类,该类中的所有传真为垃圾传真。
(4)确定类代表特征:设dij表示某传真数为n的类中点i到点j的距离,di表示点i到该类所有点的距离和,如果di=min(d1,d1,…,dn),则点i为该类的中心点,其游程特征作为该类的代表特征,加入垃圾传真特征库。
(5)确定孤立垃圾传真:集合M={m1,m2,…}为垃圾传真模版库,G={g1,g2,…}为不能聚类的传真的集合,若d(gi,mj}<?着,则gi为垃圾传真。
3 仿真测试
上述方法通过MATLAB完成了仿真实现。通过该方法实现的传真服务器,不但具有一般传真服务器的功能,而且能够对待分发的传真进行判别,确保最终用户收到的传真不是垃圾传真。
本文最后进行了性能测试。测试过程如下:
(1)从某公司传真服务器处收集得到2 000份传真数据,随机取其中400份作为训练集,另外1 600份作为测试集。
(2)建立传真特征表,用来记录传真的特征数据。字段包括:文件名、属性(垃圾传真为0,其他为1)、可聚类性(在训练集中能够聚类为1,否则为0)、聚类类别(人工对训练集中能够聚类的传真进行分类,并标以不同的类别值)。
(3)对训练集传真进行人工辨认,并将特征记入传真特征表。
(4)根据最小方差准则,用训练集中传真对分类器参数进行训练,使分类器输出结果与传真特征数据具有最大拟合度,从而得到分类器参数。
(5)对测试集中的传真进行人工辨认,并将特征记入传真特征表。
(6)用训练得到的分类器对测试集中的1 600份传真进行分类,并将分类结果自动记入数据库。
(7)比对识别结果与人工辨认数据。
测试结果如表1所示。

从表1中结果可知:
(1)没有正常的业务传真被检测为垃圾传真,说明本文的方法不会影响正常的传真业务。
(2)垃圾传真可能被误识为正常传真,这是因为本方法中,为了确保正常传真不会被聚类,聚类的条件设置得比较苛刻,造成了部分垃圾传真由于数量少不能聚类。
(3)在没有影响正常传真业务的情况下,本文方法对垃圾传真的检出率为92.5%,说明了本文方法的有效性。
在实际应用中,能够聚类的部分传真可能包含用户感兴趣的资讯,用户希望对此正常接收,所以在后续的工作中,应该在聚类的基础上,从用户的感知和体验角度出发,深入研究垃圾传真的本质,使垃圾传真的分类更加合理,进一步提高安全传真服务器的可用性。
参考文献
[1] 罗新.基于局域网的传真服务器的设计与实现[D].大连理工大学硕士学位论文,2006,6.
[2] 陈屹峰.嵌入式传真服务器的设计与实现[D].复旦大学硕士学位论文,2004,4.
[3] 李宝安,孟庆昌.中文信息处理技术——原理与应用[M]. 北京:清华大学出版社,2005.
[4] 田丽华.编码理论[M].陕西:西安电子科技大学出版社,2004.
[5] 杨兰仓.数据挖掘中聚类和孤立点检测算法的研究[D].复旦大学硕士学位论文,2004,4.
[6] 周水庚,周傲英.一种基于密度的快速聚类算法[J].计算机研究与发展,2000,37(11).