
文献标识码: A
文章编号: 0258-7998(2011)04-0113-04
最近邻分类算法KNN(K Nearest Neighbor) 是一种非参数的分类算法,在基于统计的模式识别中非常有效。对于未知和非正态分布可以获得较高的分类准确率,具有健壮性强、概念清晰等诸多优点,在许多领域都有成功的应用[1-4]。
KNN算法的关键技术是搜索模式空间找出最接近未知样本的K个训练样本,未知样本被分配到K个最近邻者中最公共的类,其近邻性用欧氏距离定义。KNN 方法最大的一个缺陷是对样本库容量的依赖性较强[5],因此不适用于小样本情况下的自动分类。此外在KNN分类算法中,确定待分类样本类别需要计算其与训练样本库中所有样本的相似度,计算量较大,甚至导致KNN算法在很多分类问题中失去实用性[6]。虽然众多学者提出了多种KNN的改进方法[7-10],但这些方法都是建立在样本选择基础上的,即以损失分类精度换取分类的速度。为此,学者Guvenir[11]提出一种基于特征投影的K最近邻算法KNNFP(K Nearest Neighbor on Feature Projection)。该算法首先分别计算各维特征投影的K个最近邻,然后根据投票准则确定最终的样本类别。由于各维特征值可以事先进行排序,进而可以进行最优搜索,使算法的效率大大提高。然而,因该算法事先假定每个特征对模式分类贡献相同,降低了算法本身的分类精度。
针对KNNFP算法存在的问题,本文提出一种基于特征加权的KNNFP改进算法WKNNFP(Weights KNNFP)。该算法考虑各维特征对模式分类贡献的不同,给不同的特征赋予不同的权值,提高重要特征的作用,从而提高了算法的分类精度。对不同实际数据进行测试均显示出改进算法的优良性能。由于故障诊断是基于某种属性对系统状态特征进行分类归属故障模式的过程[12-15],因此,本文最后将该算法应用到轴承故障诊断领域,证明了该算法在工程应用的有效性。
1 基于特征加权的KNNFP算法(WKNNFP)
1.1 算法概述
在利用KNNFP算法对样本进行分类时,总是假设特征提取相当完善,构成模式矢量的特征是独立且无冗余的。其特点是以每一个特征维度投影值来存储,在训练阶段,每一个样本都是简单地以在每一个特征上的投影值进行计算。如果这个训练样本其中的一个特征值不存在,则这个样本在这个特征维度上没有投影值存储。为了对样本进行分类,首先在每一个特征维度上分别进行预分类。这个预分类实质上就是在这个单一特征上施行KNN算法。
KNNFP算法认为各维特征对分类的贡献是相同的,而事实上,构成样本特征矢量的各维特征来自不同的传感器,存在测量精度及可靠性等差异,样本矢量的各维特征对分类的影响也不尽相同。因此,本文将探讨一种改进的K最近邻特征投影算法(WKNNFP)。该算法考虑了各维特征对模式分类的不同贡献,以求提高分类的精度。
设一个给定的测试样本为x,特征为t,定义在特征t上的最近邻算法为K Bagging(t,x,k),该函数计算测试样本x在特征t投影值上最近的k个邻居。然后对每一个类别进行k次投票,因此每一特征维度上就有k次投票机会。测试样本的类别由这些特征投影上的k次投票结果综合决定。其中,在计算测试样本x在特征t投影值上最近的k个邻居时,需要根据特征属性的不同分别进行处理,对于数值型特征t,在其上的投影值分别设为u和v,则计算在特征t的距离公式为:
WKNNFP与KNNFP算法的不同之处在于根据不同特征对分类贡献的不同,WKNNFP给每一个特征以不同的权值,使得每一个特征上的投票结果对最终测试样本类别的影响权重是不同的。
1.2 权值的确定
采用ReliefF算法来确定特征的权值。基本的Relief算法[16]是Kira和Rendell在1992年提出的,其要点是根据特征值在同类实例中以及相近的不同类实例中的区分能力来评价特征的相关度。Relief算法对数据类型没有限制,可以较好地去除无关特征,但此算法仅适用于训练样本是两类的情况。1994年,Kononemko[17]扩展了Relief算法,提出Relief F算法。RelliefF可以处理不完整数据、噪声数据和多重类别问题。
2 WKNNFP算法分类性能评价试验
为评价WKNNFP 算法的分类性能,分别对各种具有不同属性特征的数据集进行测试实验,并与传统的KNNFP算法分类性能进行比较。
2.1对常用的IRIS四维数据分类性能评价试验
为了测试本文提出的算法对数值型数据的分类性能,采用著名的IRIS实际数据作为测试样本集。IRIS数据由四维空间中的150个样本点组成,每一个样本的4个分量分别表示为Petal Length、Petal Width、Sepal Length和Sepal Width。整个样本集包含了3个IRIS种类:Setosa、 Versicolor和Virginica,每类各有50个样本。IRIS数据经常被作为检验分类算法性能的标准数据。本文分别采用传统的KNNFP算法和改进的WKNNFP算法对IRIS样本进行分类,测试两种算法的误分率,以比较它们的分类性能。本试验采用6折迭交叉验证法,即将整个数据集六等分得到6个子集,其中5个子集作为训练集,另1个子集作为测试集,这样每一个样本都能作为训练样本5次,测试样本1次。K值取1~10,分类结果如图1所示。
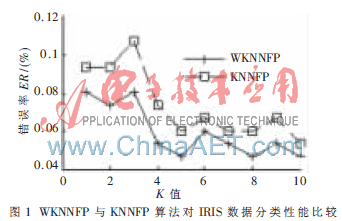
从图1中可知,由于WKNNFP算法考虑了样本特征对分类性能的贡献程度,使得分类性能有所提高。得到的加权矩阵为w=[0.150 65 0.150 0 0.317 0 0.357 4]。从得到的加权矩阵可以看出,各维特征对分类的贡献是不一样的,第4维特征贡献最大,而第2维特征贡献最小。
2.2 对高维数据分类性能评价试验
评价试验分别采用传统KNNFP算法和改进的WKNNFP算法对来自UCI的实际数据进行分类,试验中使用的数据来自James Cook大学数学与统计中心。该数据的测量来自对意大利同一地区的三个不同品种的葡萄酒化学反应的分析。葡萄酒实际数据共有178个记录,每个记录由13个数值特征描述,其中品种1包含59个数据,品种2包含71个数据,品种3包含48个数据。本次试验采用8折迭交叉验证法来比较传统KNNFP算法和改进的WKNNFP算法的分类性能。K值取1~10,分类结果如图2所示。从试验结果可以看出,WKNNFP算法具有良好的分类性能。这说明本文提出的改进算法对高维特征数据同样是有效的。
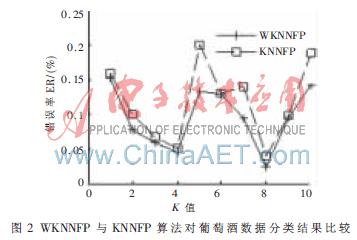
图3为WKNNFP算法得到的各维特征的权值,从图中可以看出,第2维和第8维特征的权值较小,说明这两个特征对分类起的作用较小。而第1维特征对分类的贡献最大。对照实际数据发现在样本的第1维特征上不同品种呈现不同的特征值,这也证明了新算法不仅提高了分类算法的性能,而且还可以用于模式识别中的特征提取和优选。

2.3 对具有混合特征的数据集分类性能评价试验
在数据挖掘中,经常会遇到数据的特征中既包含数值型特征,也包含类属型特征的混合特征数据。本试验采用KNNFP算法和改进的WKNNFP算法对实际的动物园混合数据进行分类,以评价两种算法的分类性能。动物园数据共有101个记录,每一个记录由15个类属特征和1个数值特征描述。由于数据较少,因此本次试验采用3折迭交叉验证法,K值取1~10,分类结果如图4所示。从试验结果可以看出,WKNNFP算法具有良好的分类性能,这说明本文提出的改进算法对混合特征数据同样是有效的。
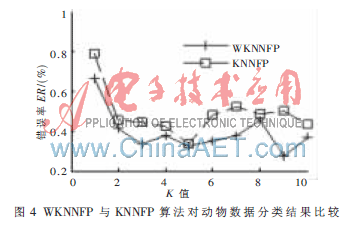
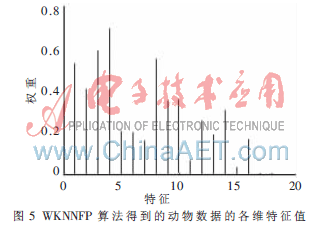
图5为WKNNFP算法得到的各维类属特征的权值,从图中可以看出,第4维特征的权值最大。而第15维特征对应的权值最小,对分类的贡献最小。从试验中可以发现,取不同的K值,改进的WKNNFP算法都要优于传统的KNNFP算法,而K值的选择和分类精度之间却没有明显的关系,因此需要根据具体的应用做出优化选择。
3 WKNNFP算法在故障诊断中的应用
为了验证本文提出的改进算法在工程应用中的有效性,将本文算法应用到机械设备故障诊断中。试验数据来自美国Case Western Reserve University电气工程实验室。振动信号的收集来自安装在感应电机输出轴支撑轴承上端机壳上的振动加速度传感器。实验模拟了滚动轴承的七种状态:正常运行状态,外圈轻微故障,内圈轻微故障,滚动体轻微故障,外圈严重故障,内圈严重故障及滚动体严重故障。其中,轻微和严重故障的故障尺寸大小分别为0.18 mm和0.36 mm。
试验中采用500个正常样本、500个内圈故障、500个外圈故障和500个滚动体故障样本点作为样本集,每个样本含1 024个采样点,利用Harr小波对每个样本进行五级分解,将每一级小波分解系数绝对值的平均值和方差作为特征,共10个特征。实验采用6折迭交叉验证法,试验结果如图6所示。图6中结果说明,利用本文改进的WKNNFP算法对故障诊断是有效的,并且优于传统的KNNFP算法。

图7为WKNNFP算法得到的各维数值特征的权值。从图中可以看出,第5、6维特征的权值最大,特征空间中第5、6维特征是描述信号第3层小波分解的特征,正好对应区分能力最大的本征频谱区域,因此这两维特征对分类的贡献最大。这也说明本文提出的方法可以实现故障诊断特征的优选。

针对传统KNNFP分类算法中假设各维特征对分类的贡献相同而导致分类性能下降这一不足,本文提出一种基于特征加权的KNNFP算法。通过实验证明,WKNNFP改进算法利用ReleifF计算特征权重,考虑了各种特征对分类贡献的大小,提高了重要特征的作用,使其对数据的分类性能大大提高。同时改进算法还有助于分析各维特征对分类的贡献程度,可以有效地进行特征提取与优选。本文的方法在实际应用中非常方便,具有很好的推广价值,不仅适合于轴承故障检测,同样也适用于其他分类应用领域。
参考文献
[1] 周小鹏,冯奇.基于最近邻法的短时交通流预测[J]. 同济大学学报(自然科学版), 2006,30(10):1494-1497.
[2] 孙发圣,肖怀铁. 基于K最近邻的支持向量机快速训练算法[J].电光与控制,2008,15(6):44-47.
[3] 聂方彦.基于PCA与改进的最近邻法则的异常检测[J].计算机工程与设计,2008,29(10):2502-2504.
[4] 刘海博,郗亚辉.用于文本分类的快速KNN算法[J]. 河北大学学报(自然科学版),2008,28(3):322-326.
[5] 杨建良,王勇成.基于KNN 与自动检索的迭代近邻法在自动分类中的应用[J].情报学报,2004,23(2):137-141.
[6] 王晓晔,王正欧.K-最近邻分类技术的改进算法[J].电子信息学报,2005,27(3):487-491.
[7] 周晓飞,姜文瀚.基于子空间样本选择的最近凸包分类器[J].计算机工程.2008, 34(12):167-171.
[8] 姜文瀚,周晓飞.基于样本选择的最近邻凸包分类器[J].中国图像图形学报,2008,13(1):109-113.
[9] 李荣陆,胡运发.基于密度的KNN文本分类器训练样本裁剪方法[J].计算机研究与发展,2004,41(4):539-545.
[10] 王煜,张明.用于文本分类的改进KNN算法[J]. 计算机工程与应用,2007, 43(13):159-165.
[11] AKKUS A, GUVENIR H K. Nearest neighbor classification on feature projections proceedings of the 13th international conference on machine learning[C]. Lorenza Saitta,Bari,Italy,2003:12-19.
[12] 陶新民,杜宝祥,徐勇.基于HOS奇异值谱和SVDD的轴承故障检测方法[J].振动工程学报,2008,21(2):203-208.
[13] 崔宝珍,王泽兵.小波分析-模糊聚类法用于滚动轴承故障诊断[J].振动、测试与诊断,2008,28(2):151-154.
[14] 鲁卿,冯金富.一种基于WFCM 的故障诊断方法[J]. 振动、测试与诊断,2007,27(4):308-311.
[15] 黄晋英,毕世华.独立分量分析在齿轮箱故障诊断中的应用[J].振动、测试与诊断,2008,28(2):126-130.
[16] 李洁,高新波,焦李成.基于特征加权的模糊聚类新算法[J].电子学报,2006,34(1):89-92.
[17] KONONENKO I. Estimating attributes analysis and extensions of relief[C]. Proceedings of the 7th European Conference on Machine Learning. Berlin: Springer,1994,171-182.