
分布式运算单元的原理及其实现方法
2009-04-28
作者:蒋亚坚 张庆雷
摘 要: 以Xilinx公司的XC4000系列FPGA(现场可编程门阵列)为例,介绍了分布式运算单元DA(Distributed Arithmetic)在高速DSP设计中的原理及实现方法。
关键词: 数字信号处理 DSP FPGA FIR滤波器 FFT
随着FPGA集成度的不断提高,在单片FPGA中完成复杂的数字信号处理过程变成了现实。譬如:FIR滤波器、FFT以及雷达信号处理中的数字脉冲压缩、数字鉴相等,都可以在单片FPGA中实现。在基于Xilinx XC4000系列FPGA设计的DSP中,分布式运算单元DA扮演着重要的角色。本文介绍其原理及其实现方法。
1 分布式运算单元原理
DA的运算原理非常简单,但是它的应用却十分广泛。
一个线性时不变网络的输出可以用下式表示:

其中, y(n)为第n时刻网络的输出;Xk(n)为第n时刻的第k个输入变量;Ak为第k个输入变量的权值。
在线性时不变系统中,对于所有n时刻,Ak都是常量。如果该网络表现为滤波器,常量Ak 即为滤波器系数,变量Xk为单一数据源的抽样数据(如A/D的输出)。而在时-频转换系统中(如离散傅立叶变换及快速傅立叶变换),常数Ak即为旋转因子值,变量Xk为单一数据源的数据块(多源数据的例子可以在图像处理系统中发现)。
仔细观察式(1)可以看出,单个输出y(n) 需要将k个乘积累加。在以XC4000系列FPGA中的可配置逻辑功能块(CLB)的查找表(Look-Up Table)结构[1]为基础的DA中,这种乘积累加可以由查找表来实现。XC4000系列的CLB结构特点使得它很容易被高效的配置。
为了使得乘法之后的数据宽度不至于展宽,先把数据源数据格式规定为浮点数2的补码形式。需要注意的是,常数Ak 不一定要进行格式转换来匹配输入数据的格式,它可以根据所要求的精度进行定义。
变量Xk可以用下式表示:

其中,Xkb为二进制数,即取值为0或1;Xk0为符号位,Xk0为1表示数据为负,为0表示数据为正。
将式(2)代入式(1)可以得到:

可以看出,每个方括号中进行的是输入变量的某一个数据位和所有常数(A1~Ak)的每一位进行位与并求和。而指数部分则说明了求和结果的位权。现在就可以建立查找表来实现方括号中的操作了,其查找表用所有输入变量的同一位进行寻址,如图1所示。
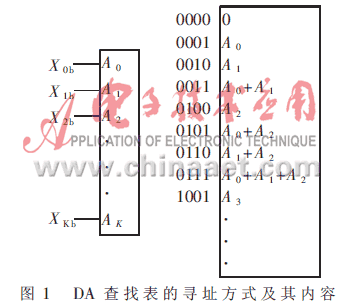
图1中所示的DA查找表,其宽度为对常数Ak 定义的宽度,深度为2K,K是能够对数据源抽样数据进行处理的数据长度,对于滤波器就表现为滤波器阶数;对于FFT就表现为FFT点数。
这样,式(1)所表示的方程就可以由加法、减法和二进制除法来实现了。但是,DA仅仅是运算方程(1)的核心,要完成式(1)还需要根据系统对时间以及FPGA资源的考虑,选择相应的方法。
2 几种实现方法
2.1 全并行实现方法
市场上已经有大量的通用DSP芯片,这些芯片以并行的乘法、加法运算,地址产生器和片内存储器为主要特点,如TMS320C620x、ADSP2106x、及各种通用的FFT芯片(如PDSP16510)。为什么还要选择FPGA呢?主要是考虑速度。要实现一个64阶FIR滤波器,如果采用全并行方式,FPGA可做到50MHz的数据率,可以和系统时钟相匹配,这是通用DSP芯片无法做到的。下面就举出全并行的例子。
若将式(4)每个方括号之间的加法并行执行,即将每个DA查找表的输出采用并行的加法,就得到了全并行结构。现将式(4)中的某个方括号重写如下,并缩写为sum:

利用式(6),可以得到一种直观的树形阵列,如图2所示。

图2中,首先要建立一个K×B位的寄存器阵列,将其输出进行排列,用所有K个输入数据的相同位,对DA查找表寻址,从图中可以看出,当B=16时,输入到输出所需的路径最长,该路径为关键路径,影响着电路处理的速度,在进行设计时应该注意到这点,所以应该采用流水线设计方法[1],并进行适当的约束,其数据率可以达到50MHz。图中的15个节点代表着15个并行的加法器,中间过程的数据宽度既可以保持双精度(B+C)位数据(C是常数Ak的宽度),也可以采用截尾的办法得到单精度B位数据,可根据系统所要求的精度确定。
2.2 全串行实现方法
当系统对速度的要求不是很高的时候,可以用全串行设计方法,即一个DA查找表,一个并行的加法器以及简单少量的寄存器就可达到目的,这样能够节省大量的FPGA资源。同样,设K=16,B=16,将式(4)改写如下形式:

为了实现式(7),先从最低位开始,用所有K个输入变量的最底位对DA查找表进行寻址,得到了[sum15],将[sum15]右移一位即将[sum15]乘2-1后,放到寄存器中,设为[tem15];同时,K个输入变量的次低位已经开始对DA查找表寻址得到[sum14],右移一位后,与[tem15]相加,重复这样的过程,直至得到[sum0],并用前面得到的累加结果减去[sum0]。要实现上述过程,需要K个长度为B的串并行转换移位寄存器、一个容量为2K×C的DA查找表和一个累加器。该全串行电路的数据率为输入数据抽样频率的1/B,即完成一次运算需要B个时钟周期。由此可以得到全串行DA模式,如图3所示。

2.3 串并行相结合实现方法
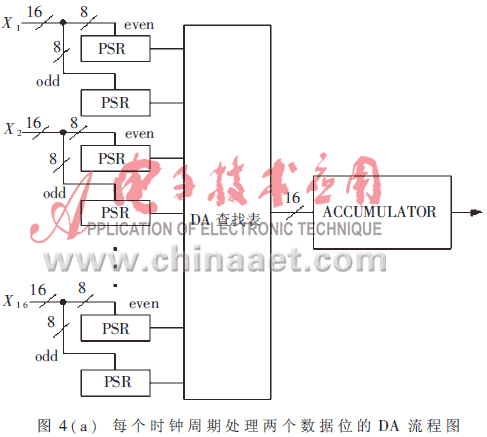
以上介绍的全串行方式是每个时钟周期对所有K个变量的一位进行串行处理,全并行方式是每个时钟周期对所有K个变量的所有B位进行并行处理;这两种方法是针对速度优化和资源优化设计的两种极限情况。在有些情况下,我们可以对这两种情况进行折中考虑,获得最佳资源利用和系统速度。我们可以从每个时钟周期对K个变量的两位进行处理开始着手,回顾一下式(5),并将该式改写如下:

完成该式功能的功能框图如图4a所示。
将图4(a)与图3进行比较后就可以发现,图3中的DA查找表由16个输入变量的同一位进行寻址,而图4(a)中的DA查找表的寻址是由16个输入变量的连续两位进行的,即寻址的位数由16位变成了32位。这样,查找表的内容也需要相应的改变;而且完成一次运算也由原来的B个时钟周期变成了需要B/2+1个时钟周期。
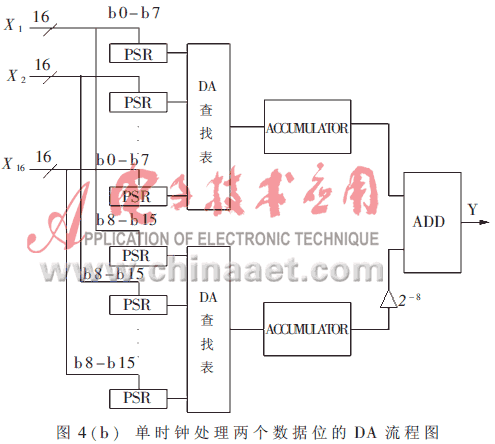
下面介绍一种更易于理解的串并行混合设计方法。
将式(5)改写成如下形式:

从式(9)得到流程图如图4(b)所示。
实现过程中应该注意DA查找表的内容,累加之前要乘2-1,注意进位等。
从以上给出的两种串并行结合的设计方法可以看到,只要将式(5)进行适当的变换,还有其它的硬件实现方法,这里就不一一叙述了。
下面给出在K=8、B=16的情况下,不同的DA查找表所占用的资源。Xilinx公司的XC4000系列FPGA的一个CLB可以实现32×1大小的RAM,在图4(a)中所描述的DA查找表占用2,048个CLB,而在图4(b)中所描述的两个DA查找表只占用256个CLB。用一片XC4025即可完成后者,其数据率可达到16MHz。
综上所述,由于分布式运算单元的应用,改变了传统的设计观念,为基于FPGA的DSP设计提出了新的思路,必将在高速的FIR滤波器设计、高速FFT设计中得到广泛的应用。随着FPGA集成规模的不断提高(Xilinx公司Virtex系列已经达到了百万门级),许多复杂的数学运算已经可以由FPGA来实现,单片FPGA实现系统的设想即将变为现实。
参考文献
1 蒋亚坚,沈桂明. FPGA在雷达信号处理器中的应用研究. 雷达与对抗. 1999(2):57~63
2 The Programmable Logic Data Book. Xilinx, 1999