
关联规则在学生CET4成绩中的应用
2009-05-19
作者:陈 伟1,程黄金2
摘 要:关联规则是数据挖掘的主要技术之一,是描述数据库中一组数据项之间的某种潜在关系的规则。以学生CET4成绩数据为研究对象,运用关联规则挖掘算法Apriori算法,找出学生CET4成绩中听力、阅读、写作、综合测试四部分成绩之间的关系,以及这四部分成绩与总分之间的关系。
关键词:关联规则;Apriori算法;频繁项集;数据挖掘;CET4
数据挖掘技术应用于教学管理中的主要方法是根据现有信息系统中的数据,挖掘高校教学管理工作中平常看不见、也无从知道的规律,以此来提高管理效率,帮助教师改进现有的教学方式和方法,从而增强高校的竞争优势。关联规则形式简洁,易于解释和理解,并可以有效地捕捉数据间的重要关系。
1 关联规则的原理
一般地,关联规则挖掘是指从一个大型的数据集中发现有趣的关联或相关关系,即从数据集中识别出频繁出现的属性值集,也称为频繁项集(简称频繁集),然后再利用这些频繁集创建描述关联规则的过程[1]。
关联规则可形式化定义为:
设I={i1,i2,…,im}是由m个不同的项组成的集合。给定一个事务数据库D,其中每一个事务T是I中一组项的集合,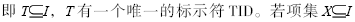
 则事务T包含项集X。
则事务T包含项集X。
关联规则是形如 并且X∩Y=Ф,如果D中事务包含X∪Y的百分比为S,则称S为关联规则X=>Y的支持度,它是概率P(X∪Y) ;如果D中包含X的事务同时也包含Y的百分比为C,则称C为关联规则X=>Y的置信度,它是条件概率P(Y/X)。习惯上将关联规则表示为X=>Y(S%,C%)。
并且X∩Y=Ф,如果D中事务包含X∪Y的百分比为S,则称S为关联规则X=>Y的支持度,它是概率P(X∪Y) ;如果D中包含X的事务同时也包含Y的百分比为C,则称C为关联规则X=>Y的置信度,它是条件概率P(Y/X)。习惯上将关联规则表示为X=>Y(S%,C%)。
关联规则的发现任务或问题就是在事务数据库D中找出所具有用户给定的最小支持度阈值(min_ sup)和最小置信度阈值(min_cof)的关联规则,即这些关联规则的支持度和置信度分别不小于最小支持度和最小置信度,这样,每条被挖掘出来的关联规则就可以用一个蕴涵式(X=>Y)和两个阈值(最小支持度min_sup和最小置信度min_cof)表示[1]。
2 关联规则挖掘算法
2.1 Apriori算法:使用候选项集找频繁项集
Apriori算法通过对数据库D的多次扫描来发现所有的频繁项目集。在第一次扫描数据库时,对项集I中的每一个数据项计算其支持度,确定出满足最小支持度的频繁1项集的集合L1,然后,L1用于找频繁2项集的集合L2,如此下去……在后续的第k次扫描中,首先以k-1次扫描中所发现的含k-1个元素的频繁项集的集合Lk-1为基础,生成所有新的候选项目集CK(Candidate Itemsets),即潜在的频繁项目集,然后扫描数据库D,计算这些候选项目集的支持度,最后从候选集CK中确定出满足最小支持度的频繁k项集的集合Lk,并将Lk作为下一次扫描的基础。重复上述过程直到再也发现不了新的频繁项目集为止。
2.2 由频繁项集产生关联规则
找出了所有的频繁项集,由它们产生强关联规则就很方便了(强关联规则满足最小支持度和最小置信度)。对于置信度,公式为:confidence(X=>Y)=P(Y|X)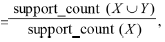 ,其中support_count(X∪Y)是包含项集X∪Y的事务数。support_count(X)是包含项集X的事务数。关联规则产生如下:
,其中support_count(X∪Y)是包含项集X∪Y的事务数。support_count(X)是包含项集X的事务数。关联规则产生如下:
对于任意一个频繁项集L和L的任何非空子集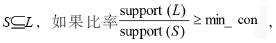 则生成关联规则
则生成关联规则 且该规则的置信度和支持度分别为:
且该规则的置信度和支持度分别为: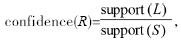 support(R)=support(L)[2]。
support(R)=support(L)[2]。
3 关联规则的应用
以下以Visual Foxpro6.0为工具进行讨论。
3.1 数据预处理
对现有的学生CET4成绩进行数据预处理(Data preprocessing),包括2个步骤:数据清理(Data Clearing)和数据变换(Data Transformation)。
(1)数据清理:对表中的原始数据进行数据清理,消除一些冗余数据,消除噪声数据,消除重复记录。很多学生的CET4成绩数据都为0,通过调查知道这些数据缺失的原因是学生未参加考试,把这些数据都从数据库表中删除。数据清理后的如图1所示。
(2)数据变换:将数据转换成适合于挖掘的形式。由于学生CET4成绩是以数字的形式给出的,不利于数据挖掘的进行,因此需对听力、阅读、写作、综合测试4项的连续属性值进行离散化处理,即转换为优秀、良好、中、及格、不及格5个等级。因为CET4的分值分配为:总分710,听力249,阅读249,写作142,综合测试70,所以要把分数换算为百分制。如分数高于85为“优”,介于80~85之间为“良”,70~80之间为“中”,60~70之间为“及格”,60分以下为“不及格”。“不及格”、“及格”、“中”、“良”、“优”设定为1、2、3、4、5;用“A”代表总分,“B”代表听力分数,“C”代表阅读分数,“D”代表写作分数,“E”代表综合测试分数;将除了学号的所有字段都改为字符型。数据变换后如图2所示,总计1 814条记录。

3.2 设计思路
3.2.1求解频繁项集
图2中的学生成绩表.DBF为本文要研究的事务数据库,它有6个字段,均为字符型。求解频繁项集步骤如下:
(1) 建立一个项目数据表ITEM.DBF,该表中有1个字段,字段名为A,数据类型为字符型,用于存放CET4成绩中每个组成部分的所有分数段的表达值,该表中每条记录代表一种表达值,表中的记录数就是表达值形式的数目。该数据表中的记录升序排列,分别为a1、a2、a3、b1、b2、b3、c1、c2、c3、d1、d2、d3、d4、e1、e2、e3、e4、e5。
(2) 建立6个空数据表FRENQ1、FRENQ2、FRENQ3、FRENQ4、FRENQ5、FRENQ6,分别用来存放1、2、3、4、5、6频繁项集和它们的支持度计数。其中FRENQ1中有2个字段A、SUP,FRENQ2有3个字段A、B、SUP,FRENQ3有4个字段A、B、C、SUP,FRENQ4有5个字段A、B、C、D、SUP,FRENQ5有6个字段A、B、C、D、E、SUP,FRENQ6有7个字段A、B、C、D、E、F、SUP,只有SUP为数值型,其余的数据类型均为字符型。
(3) 利用成绩表产生一个辅助数据表ITEM1,该表中只有一个字段ITEMSET ,数据类型为字符型,记录数与成绩数据表相同,数据为成绩表中的A+B+C+D+E的值。
(4) 在求每个频繁项目集时,分2步进行:第1步产生候选项,第2步生成频繁项目集。具体过程如下:首先,扫描ITEM表中每一条记录,对应在ITEM1.DBF求出所有的长度为1的该候选项的支持度,如果支持度大于给定的最小支持度,就把它存入FRENQ1.DBF中,直至把ITEM中的记录数扫描完为止。随后,利用FRENQ1.DBF产生长度为2的候选项,扫描ITEM1.DBF求出所有长为2的该候选项集的支持度, 如果支持度大于给定的最小支持度,就存入FRENQ2.DBF中,直至扫描完FRENQ1.DBF中的记录为止。其余的以此类推,直到求出所有的频繁项目集。若发现某频繁项集的数目为零,则停止计算。最后,输出所有项目的频繁集。在该程序中依然运用了Apriori算法的性质:如果一个项集是频繁的,则它的所有子集也是频繁的[3-6]。
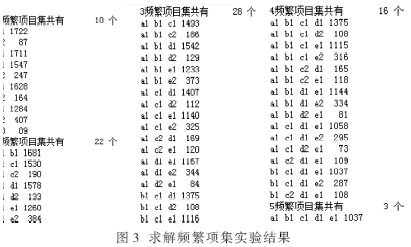
设定最小支持度为0.04,支持度计数为73,产生了79个频繁项集。实验结果如图3所示。
3.2.2 提取关联规则
从已经产生的频繁项集中确定它们的子集,然后根据关联规则的挖掘算法原理,假设最小置信度为30%,由程序得出350个关联规则。部分试验结果如图4所示。

4 结果分析
(1) 听力、写作与总分之间的关系是双向的,即听力或写作分较低,总分一般也较低;反之,总分较低,听力或写作也较低。因为对于学生而言,一般学习听力、写作的主动性较差,而这两种题型也是一般学生考试中最棘手的题型。
(2) 阅读、综合测试和总分之间的关系主要表现为单向,即阅读、综合测试分较低,总分极有可能较低,但反之未必。这是由于CET4中的阅读和综合测试两项的分值比例相对较大引起的。
(3) 任意两项(或两项以上)得分较低,总分都较低。其中,听力和阅读是影响总分最大的两个因素。
(4) 在听力、阅读、写作和综合测试四项中,综合测试题得分与其他三项得分的关系相对较小;而听力和写作则与阅读和综合测试的关系比较紧密。
(5) 从与总分的关系,以及与其余单项的关系来看,听力、阅读、写作和综合测试四项中,听力是最突出的。
最后得出这样一个结论:在日常教学中应进一步强调听力题的重要地位,进一步加强听力的训练。
关联规则的应用很广泛。本文根据关联规则的挖掘过程,对学生CET4成绩的各个部分进行了分析。利用Apriori算法,借助于计算机,可以对于海量数据进行分析,从而可以进行更为全面和客观的预测与决策。分析的结果将会对某门课程的教学提供大量有用的信息,从而指导我们的教学。
参考文献
[1] 陈文伟,黄金才. 数据仓库与数据挖掘[M]. 北京:人民邮电出版社,2004.
[2] 韩家炜. 数据挖掘概念与技术[M]. 北京:机械工业出版社,2000.
[3] 齐晓峰. 数据挖掘技术在学生成绩管理中的应用研究[D]. 阜新:辽宁工程技术大学,2006.
[4] 赵辉. 数据挖掘技术在学生成绩分析中的研究及应用[D].大连: 大连海事大学,2007.
[5] 陆楠. 关联规则的挖掘及其算法的研究[D]. 长春:吉林大学,2007
[6] 罗可,吴建华,吴杰. 一种用Visual Foxpro求频繁项目集的方法[J]. 计算机工程,2001(5).