
基于关联规则理论的道路交通事故数据挖掘模型
2009-06-11
作者:吴 昊, 李军国
摘 要: 根据数据挖掘技术中的关联规则理论,提出“道路交通事故属性”的定义,并建立一种新的道路交通事故数据挖掘模型,利用改进的多维多数据类型的Apriori算法,从记录交通事故的数据库中发现潜在的、有价值、有联系的规律,用以指导交通管理部门找出道路黑点,并做出决策,杜绝事故隐患、减少事故发生,保障人们的生命和财产的安全。
关键词: 道路交通事故属性; 关联规则; 数据挖掘; Apriori算法
智能交通系统ITS(Intelligent Transportation System)是先进的信息技术、数据通讯传输技术、电子传感技术、电子控制技术及计算机处理技术等多种高新技术与传统交通运输融合的集成和应用。改善道路交通环境。
关联规则是数据挖掘的主要方法,是指在数据集中支持度和置信度分别满足给定阈值的规则,反映一个事物与其他事物之间的相互依存性和关联性。关联规则挖掘的Apriori算法是根据有关频繁项集特性的先验知识而命名的,算法中蕴含的一条基本性质是一个频繁项集的任一子集均应是频繁的。借助一定的专业领域知识,关联规则可以直接用于分析数据的因果关系,做出规则预测。从大量的数据中发现其关联关系在市场定位、决策分析和商业管理等领域极为有用。
本文提出“道路交通事故属性”的定义,并且采用“星型全连接数据模型”对道路交通事故属性的数据组织建模。结合对经典单维单层的Apriori算法进行改进,实现挖掘多维多数据类型关联规则的新算法。通过对某市区的道路交通事故数据进行关联规则提取分析,产生大量具有支持度和置信度的强关联规则,可有效地分析交通事故发生的主要原因,为决策者提供切实可行的治理方案和预防措施。
1 关联规则理论
1.1 关联规则的基本概念

式中:support(AYB)为包含项集AYB的交易记录数目,support(A)为包含项集A的交易记录数目。
规则的支持度和置信度是两个规则的度量, 它们分别反映发现规则的实用性和确定性。这两个阈值均在0%~100%之间,而不是0~1之间。
给定一个交易集D,挖掘关联规则问题就是产生支持度和置信度分别大于用户给定的最小支持度min-sup(minimum support count)和最小置信度min-con(minimum confidence count)的关联规则。前者即用户规定的关联规则必须满足的最小支持度,表示了一组物品集在统计意义上需满足的最低程度;后者即用户规定的关联规则必须满足的最小置信度,反应了关联规则的最低可靠度。
如果不考虑关联规则的支持度和置信度,则在事务数据库中存在无穷多的关联规则。事实上,人们一般只对满足一定的支持度和置信度的关联规则感兴趣。一般把同时满足最小支持度阈值和最小置信度阈值的规则称为强规则。给定一个事务集D,挖掘关联规则问题就是产生支持度和置信度分别大于用户给定的最小支持度和最小置信度的关联规则,也就是强规则的问题。
因此,关联规则挖掘可定义为:给定一个事务数据库D,寻找出所有满足support>min-sup,confidence>min-con的关联规则A B。
B。
具体产生关联规则的操作说明如下:
(1) 对于每个频繁项集l,产生l的所有非空子集。
(2) 对于每个l的非空子集s,若support(l)/support(s)>=min-con,则产生一个关联规则“s(l-s)”。
项的集合称为项集(Item set),包含k个数据项的项集称为k-项集。
项集的出现频率是在整个交易数据集D中包含该项集的交易记录数,简称为项集的频率、支持度或计数。
如果项集的出现频率大于或等于min-sup与D中事务总数的乘积,称项集满足最小支持度min-sup。如果项集满足最小支持度,则称它为频繁项集(Frequent Item set),简称频集。频繁k-项集的集合通常记作Lk。
1.2 Apriori算法
Apriori算法是由AGRAWAL R等人提出的。该算法利用一个层次顺序搜索的循环方法完成频繁项集的挖掘工作。利用k-项集来产生(k+1)-项集。核心思想是把发现关联规则的工作分为两步:第一步通过迭代检索出事务数据库中的所有频繁项集,即频繁项集的支持度不低于用户设定的阈值;第二步从频繁项集中构造出满足用户最低信任度的规则。挖掘或识别所有频繁项集是Apriori算法的核心,占整个计算量的大部分。后来的许多算法多是对Apriori算法的改进研究。
为提高按层次搜索并产生相应频繁项集的处理效率,Apriori算法利用了一个称为Apriori的重要性质,来帮助有效缩小频繁项集的搜索空间。Apriori算法的性质:频繁项集中所有非空子集也都必须是频繁项集。
这一性质是由AGRAWAL和SRIKANT提出并证明的,若一个集合不能通过测试,该集合的所有超集也不能通过同样的测试。根据这一性质,进行第k遍扫描之前,可先产生候选集Ck,Ck可以分两步来产生,设前一步(第k-1步)已生成(k-1)-频繁集Lk-1,则首先可以通过对Lk-1中的成员进行联接来产生候选,Lk-1中的两个成员必需满足在两个成员的项目中有k-2个项目是相同的这个条件方可连接,即:

然后再从Ck中删除所有包含不是频繁的(k-1)-子集的成员项目集即可[2]。也可以根据定义,如果项集I不满足最小支持度阈值min-sup,则I不是频繁的,即P(I)
2 基于关联规则的道路交通事故数据挖掘模型
2.1建立数据模型
实际上,交通管理部门在道路交通事故预防工作中,主要是根据不同时期、不同地点道路交通事故的态势做出相应的管理对策,从管理上减少事故。要做到这一点,首先要对事故发生的情况进行数据分析,从中发现规律性的东西,做到有的放矢。道路交通事故研究主要建立在大量事故统计分析资料的基础上,由于道路交通事故难以现场直接观测其发生过程,需要通过事后的数据资料分析来研究其发生规律。因此,针对交通事故基础数据资料的整理显得尤为重要。如何从大量的道路交通事故的诱发因素中发现它们之间联系的内在规律,进行人为控制和干预,以减少交通事故发生的概率是大家所关注的焦点。结合对实际情况的分析,提出以下问题:
在以往关联规则理论研究中,主要集中在单维单层布尔型关联规则上,即每一条规则包括一个多次出现的谓词。如果把典型的单维单层布尔型的数据挖掘的Apriori算法直接作用于此次项目中的数据,则Apriori算法只能解决针对多维数据列表中的某一列属性的关联规则的挖掘,而不能解决多个属性集之间的数据挖掘。例如,只能挖掘道路交通事故属性中的事故主要原因的关联规则:酒后驾车,疲劳驾车,超速行驶,逆向行驶,违章超车,违章转弯,违章装载……。但是如果要挖掘驾驶员因素与道路因素之间的关联规则,此算法则无法直接应用。
如果把道路交通事故属性集的所有属性不分类别地全部放到一个属性集合中,使其成为一个混合内容的单维数据集合,就可以直接利用Apriori算法。例如,把天气属性:沙尘、雨、雪、雾、晴、大风、阴、其他的每个元素都作为整体事故属性集合中的属性值,存在如下问题:(1) 每次数据库扫描的信息过于庞大,降低效率;(2) 同一类型的属性被拆开,不利于做统计分析;(3) 得到的结果很可能是没有意义的;(4) 数据库将变得杂乱无章等。
人们已提出了挖掘单层与多层的布尔型关联规则、多维多层数据类型关联规则的许多算法,最著名的是单层布尔型Apriori挖掘算法。许多算法都是基于Apriori的,其缺陷是扫描数据库的次数正比于最大模式的长度。而挖掘多维多层关联规则过程中发现的模式长度在20左右的情况并不少见,算法代价非常高。其次,已有的多维多层关联规则挖掘算法只能通过合并相邻的数值型属性区间来建立有限的概念层次,不能满足实际应用的需要。
针对以上问题,本文基于多维多层的关联规则的挖掘算法,着重研究数据挖掘技术在决策分析系统中的应用,针对道路交通事故这一实际问题对典型的单维单层布尔型Apriori算法进行改进,实现挖掘多维多层多数据类型关联规则的新算法。
2.2 道路交通事故属性的定义
道路交通事故属性PRTA(Property of the Road Traffic Accident)是指道路交通事故发生时,驾驶员、车辆、道路、天气和时间的状态,以及事故本身的特点,即:驾驶员属性、车辆属性、道路属性、天气属性、时间属性和事故本身属性的集合。这样,就可以将大量的道路交通事故数据按照道路交通事故属性组织为信息进行数据挖掘。
2.3 道路交通事故属性的数据模型
在大规模的数据库中,由于多维数据空间的稀疏性,若要在低层和原始层的数据项之间发现强的和有趣的关联规则比较困难,因为好多项集没有足够的支持度。在较高的概念层发现的强关联规则可能提供普遍意义的知识,对于一个用户代表普遍意义的知识,对于另一个用户可能是新颖的。这样,数据挖掘系统可在多个抽象层挖掘关联规则,且容易在不同的抽象空间转换。
概念层次树是数据库中各属性值和概念依据抽象程度不同而构成的一个层次结构,如图1所示。

图中,PRTA为道路交通事故属性; D(Driver)为驾驶员属性; V(Vehicle)为车辆属性; R(Road)为道路属性; W(Weather)为天气属性; T(Time)为时间属性; A(Accident)为事故本身属性。
多层关联规则的挖掘一般采用自顶向下的策略,由概念层1开始向下,到较低的更特定的概念层,对每个概念层的计算频繁项集累加计数,直到不能再找到频繁项集,即:一旦找到概念层1的所有频繁项集,就开始在第2层找频繁项集,如此下去,就可以在每一层使用发现频繁项集的多维多数据类型Apriori算法。
在进行多维数据挖掘时,将数据按一定的结构组织起来,通常的数据建模方法有多维数据结构、星型模型、雪花模型以及超立方体等。基于对道路交通事故属性的分析,这里建立星型全连接结构的数据模型如图2所示。

定义了道路交通事故属性的概念层次树和星型全连接的数据模型后, 就可以对发生道路交通事故的各个因素进行定性的分析。
道路交通事故属性的数据来自“道路交通事故信息采集项目表”,每一个道路交通事故属性是表的维,每个维连接着一个维表。要对D[D1,D2,…,Dn]维进行关联规则的挖掘,每个维Di表示一个属性,每个维包含|Di|(i=1,2,…,n)个不同的数值,在这里|Di|为维Di具有的不同属性的个数。在这些维的每个单元中存储的是原始数据的计数值。一般情况下,可以把一个n维的数据映射成一个具有n个属性的表。
交通事故属性具有概念分层,主要有三层:
第一层是道路交通事故属性。
第二层是第一层的细化:驾驶员属性、车辆属性、道路属性、天气属性、时间属性、事故本身的属性。
第三层是对第二层的更进一步细化,主要是对道路交通事故每一属性维的刻度(也就是粒度)进行分析:性别、年龄、驾龄、驾照种类、驾驶员类型、出行目的、车辆使用性质、交通方式、行驶状态、所属行业、公路行政等级、地形、路面情况、路面类型、道路横断面、路口路段类型、道路线形、道路类型、交通控制方式、照明条件、小时、星期、月份、事故类型、事故主要原因、事故形态、现场。
2.4 提取道路交通事故属性的关联规则
从以上分析可以看出,道路交通事故属性模型是多维多层的。由于Apriori算法只是在单维单层的数据模型上进行挖掘,不适合对多维多层的数据模型进行挖掘,要想对上述的道路交通事故属性的数据模型进行分析,Apriori算法必须进行一定的改进。将数据模型的每个维看成是一个谓词,就可以挖掘多维关联规则,在多维关联规则的挖掘中,搜索频繁谓词集。对于多层数据模型,在设定各层的支持度大小时有多种方法,再进行多维多层的数据挖掘是比较繁琐的,这里对其进行了简化。在进行关联规则分析前,预先指定该维的那一个层次参与关联分析,其他层次不参与关联分析,从而将问题简化为单纯的多维数据模型的挖掘。在进行挖掘之前,对事故主要原因选择第三层,其他维都是单层的。通过这样的指定,就可以得到多维单层道路交通事故属性数据,便于关联分析。
通过选定要分析的交通事故本身与驾驶员、车辆、道路、天气、时间等具体选项信息,利用多维多数据类型Apriori算法作关联分析,发现各个因素之间的联系,结果采用文本形式来描述,形如(A,B,C)D(sup;con)。其中,A、B、C分别代表规则的前提条件,D代表规则的结果,sup和con表示该规则的支持度和置信度,取值均为0 %~100 %之间。支持度描述的是在所有的记录中,A、B、C同时出现的概率;置信度表示在A、B、C同时出现的条件下,发生情况D的概率。当一条规则满足一定的最小支持度和最小置信度时,可以认为该规则是比较常见的,可信度是较高的。
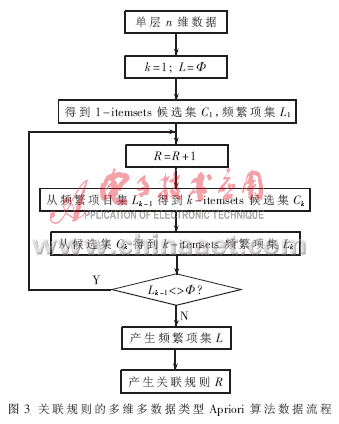
对多维数据关联分析需对Apriori算法进行改进,数据挖掘简要流程图如图3所示。
3 道路交通事故数据的分析
实验使用的是对某市市区2002年12月21日至2007年7月20日的道路交通事故数据进行测试。采取星型全连接的数据模型对道路交通事故属性数据按照上述数据建模进行组织。对该市区的道路交通事故数据进行关联规则提取分析,得出许多具有实际意义的结论。
以分析2003年12月至2004年7月某市市区事故原因为例,首先得到的是各种事故原因发生的比例(事故数据个数为2 401)如:不按规定让行(27.66%)、未保持安全距离(12.16%)、超速行驶(8.79%)、违章拐弯(7.58%)、其他机动车原因(5.46%)、逆向行驶(4.91%)、违章变更车道(4.33%)等,其他事故原因比例较小,可视为“噪音”而省略。
假设用户想了解导致“不按规定让行”这一结果,设置最小支持度阈值为5%,最小置信度阈值为40%。产生以下规则:
(1)条件:道路因素
规则:
①道路横断面:混合式 & 道路类型:主干路 不按规定让行(6.01%,36.65%)。
不按规定让行(6.01%,36.65%)。
②路口路段类型:四枝分叉口不按规定让行(7.04%,42.66%)。
③路面类型:沥青&道路横断面:混合式 & 照明条件:白天 &交通控制方式:无控制不按规定让行(9.79%,36.40%)。
(2)条件:天气因素、道路因素
规则:
①天气:晴 & 地形:平原 & 道路横断面:混合式 & 照明条件:白天&道路线形:平直&交通控制方式:无控制不按规定让行(9.27%,36.31%)。
②天气:晴 & 路面类型:沥青 & 道路横断面:混合式&照明条件:白天不按规定让行(11.84%,36.34%)。
③天气:晴&路面情况:平坦&道路横断面:混合式 & 照明条件:白天 & 道路线形:平直 & 交通控制方式:无控制不按规定让行(8.67%,36.33%)。
④天气:晴 & 地形:平原&道路横断面:混合式 & 照明条件:白天 & 道路线形:平直 & 交通控制方式:无控制不按规定让行(9.27%,36.31%)。
对2002年12月至2007年7月该市区交通事故情况进行分析,得出以下结果:
(1) 机动车驾驶人违章驾车行为导致交通事故的发生率占到事故总数的85.79%,而死亡率占67.14%。
(2)平直道路事故频繁:其上事故发生率占总数的75.63%,死亡率占81.34%。
(3) 晴天事故占绝大比例:事故发生率占总数的90.24%,死亡事故占89.27%。
(4) 从月统计周期分布来看,6~9月为事故多发时段,9月事故致人死亡较为突出。
(5) 从24小时事故分布情况看,中午、傍晚和下午时分是交通事故的多发时段。
以上实验所得到的结论与交警的经验数据基本一致。
本文基于关联规则理论,针对道路交通的实际问题,建立了基于关联规则理论的星型全连接数据模型,并提出一种改进的多维多数据类型Apriori算法,用来分析道路交通事故历史数据,并且完成了系统决策分析模块的实现。实践证明,关联规则的挖掘能够发现大量数据的属性之间有趣的关联关系,利用关联规则挖掘技术在关联性发现方面有着强大的优势。关联规则最重要的特点是关联是自然组合的,这对发现所有属性的子集存在的模式是非常适用的。
参考文献
[1] LIU Zheng Jiang, WU Zhao Lin. Data mining to human factors based on ship collision accident survey reports. Navigation of China, Jun, 2004(2).
[2] YANG Xue Bing.A high efficient multi-dimensional association rules mining algorithm. Computer Development,2002(6).
[3] SONG Zhong shan. Research on the algorithm apriori of mining association rules. Journal of South-Central University fox Nationalities(Nat. Set Edition), Mar. 2003,22(1).