
摘 要: 针对已有增量分类算法只是作用于小规模数据集或者在集中式环境下进行的缺点,提出一种基于Hadoop云计算平台的增量分类模型,以解决大规模数据集的增量分类。为了使云计算平台可以自动地对增量的训练样本进行处理,基于模块化集成学习思想,设计相应Map函数对不同时刻的增量样本块进行训练,Reduce函数对不同时刻训练得到的分类器进行集成,以实现云计算平台上的增量学习。仿真实验证明了该方法的正确性和可行性。
关键词: 增量分类;Hadoop;云计算
随着信息技术和生物技术突飞猛进的发展,科学研究和实际应用中产生了海量数据,并且这些数据每天都在增加,为了将每天产生的新数据纳入到新的学习系统,需要利用增量学习。增量学习比较接近人类自身的学习方式,可以渐进地进行知识的更新,修正和加强以前的知识,使得更新后的知识能适应更新后的数据,而不必重新学习全部数据,从而降低了对时间和空间的需求。模块化是扩展现有增量学习能力的有效方法之一[1],而集成学习(Ensemble Learning)一直是机器学习领域的一个研究热点[2-6],许多模块化增量分类算法[7-9]正是基于二者提出的。
云计算(Cloud Computing)这一新名词从2007年第3季度诞生起就在学术界和产业界引起了轰动,Google、IBM、百度、Yahoo等公司都开始进行“云计算”的部署工作。云计算是分布式计算(Distributed Computing)、并行计算(Parallel Computing)和网格计算(Grid Computing)的发展与延伸。在云计算环境下,互联网用户只需要一个终端就可以享用非本地或远程服务集群提供的各种服务(包括计算、存储等),真正实现了按需计算,有效地提高了云端各种软硬件资源的利用效率。随着云计算技术的日益成熟,云计算也为解决海量数据挖掘所面临的问题提供了很好的基础[10]。虽然在机器学习领域,对增量学习进行了较深入的研究,但是在云计算环境下,还没有相关文献讨论利用增量分类提高云计算环境下海量数据挖掘的效率问题。本文基于模块化的集成学习思想,研究在开源云计算平台Hadoop[11]上的增量分类方法。
1 Hadoop云平台的体系结构
在现有的云计算技术中, Apache软件基金会(Apache Software Foundation) 组织下的开源项目Hadoop是一个很容易支持开发和并行处理大规模数据的分布式云计算平台,具有可扩展、低成本、高效和可靠性等优点。程序员可以使用Hadoop中的Streaming工具(Hadoop为简化Map/Reduce的编写,为让不熟悉Java的程序员更容易在Hadoop上开发而提供的一个接口)使用任何语言编写并运行一个Map/Reduce作业。Hadoop项目包括多个子项目,但主要是由Hadoop分布式文件系统HDFS(Hadoop Distributed File System)和映射/化简引擎(Map/Reduce Engine)两个主要的子项目构成。
1.1 分布式文件系统HDFS
Hadoop实现了一个分布式文件系统(Hadoop Distribu-
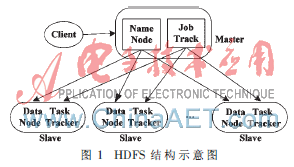
tedFile System),简称HDFS。HDFS采用Master/Slave架构,一个HDFS集群由一个NameNode节点和若干DataNode节点组成。NameNode节点存储着文件系统的元数据,这些元数据包括文件系统的名字空间等,并负责管理文件的存储等服务,程序使用的实际数据并存放在DataNode中,Client是获取分布式文件系统HDFS文件的应用程序。图1是HDFS结构图。
图1中,Master主要负责NameNode及JobTracker的工作,JobTracker的主要职责是启动、跟踪和调度各个Slave任务的执行。还会有多台Slave,每一台Slave通常具有DataNode的功能并负责TaskTracker的工作。TaskTracker根据应用要求来结合本地数据执行Map任务以及Reduce任务。
1.2 Map/Reduce分布式并行编程模型
Hadoop框架中采用了Google提出的云计算核心计算模式Map/Reduce,它是一种分布式计算模型,也是简化的分布式编程模式[12]。Map/Reduce把运行在大规模集群上的并行计算过程抽象成两个函数:Map和Reduce,其中,Map把任务分解成多个任务,Reduce把分解后的多个任务处理结果汇总起来,得到最终结果。图2介绍了用Map/Reduce处理数据的过程。一个Map/Reduce操作分为两个阶段:映射和化简。
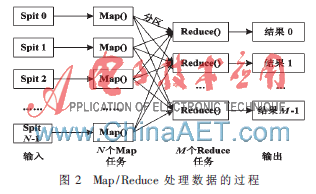
在映射阶段(Map阶段),Map/Reduce框架将用户输入的数据分割为N个片段,对应N个Map任务。每一个Map的输入是数据片段中的键值对<K1,V1>集合,Map操作会调用用户定义的Map函数,输出一个中间态的键值对<K2,V2>。然后,按照中间态K2将输出的数据进行排序,形成<K2,list(V2)>元组,这样可以使对应于同一个键的所有值的数据都集合在一起。最后,按照K2的范围将这些元组分割成M个片段,从而形成M个Rdeuce任务。
在化简阶段(Reduce阶段),每一个Reduce操作的输入是Map阶段的输出,即<K2,list(V2)>片段,Reduce操作调用用户定义的Reduce函数,生成用户需要的结果<K3,V3>进行输出。
2 基于Map/Reduce的模块化增量分类模型
基于Map/Reduce的增量分类模型,主要思想是Map函数对训练数据进行训练,得到基于不同时刻增量块的分类器,Reduce函数利用Map训练好的分类器对测试样本进行预测,并且将不同时刻训练得到的分类器进行集成,得到最终的分类结果。基于Map/Reduce的增量分类模型如图3所示。当t1时刻有海量的训练样本到达时,通过设置Map任务的个数使得云平台自动地对到达的海量样本进行划分,每个Map的任务就是对基于划分所得的样本子集进行训练得到一个基分类器。同一时刻的不同Map之间可以并行训练,从而得到t1时刻的增量分类系统。当tT时刻的训练样本到达以后,采取相同的步骤,得到tT时刻的不同基分类器,然后将这些分类器加入到tT-1时刻的增量分类系统以构成tT时刻的增量分类系统。再采用Reduce函数将当前增量分类系统里所有分类器进行集成,集成方法可以采用投票法Majority Voting(MV)进行。
2.1 Map过程
Map函数的主要功能就是建立不同时刻的增量分类系统。当某一时刻有新的训练样本到达时,Map便从HDFS将其读取。通过设置Map任务的个数使得云平台自动地对大规模的训练样本进行划分,每一个Map任务完成基于一个划分块的分类训练,划分后的不同块可以并行训练,从而得到基于该时刻增量样本集的不同分类器,然后将这些分类器加入上一时刻的增量分类系统以构成当前时刻的增量分类系统。Map函数伪代码如下:


3 仿真实验
本文用三台PC搭建了Hadoop云计算平台,三台PC的硬件配置均为2GRAM和AMD双核CPU,各节点的操作系统为Linux Centos 5.4,Hadoop版本为0.19.2,JDK版本为1.6.0_12。实验中一台PC既部署NameNode和JobTrack,也部署DataNode和TaskTrack,另两台PC均部署DataNode和TaskTrack。
实验对两个数据集进行了仿真,第一个数据集是来自UCI的Adult[13]数据集,第二个是来自UCI的Mushrooms(每个实名属性都被分解成若干个二进制属性,初始的12号属性由于丢失未使用)数据集。分类器采用SVM[14]。为了证明该方法的正确性,每个实验分别在集中式和云平台两种环境下进行。两种环境都将训练样本集随机划分为五等份以构成5个增量训练子集,也就是按照时间顺序进行了5次增量训练。由于现实中采集的增量训练样本的规模可能很大,所以在云平台环境中,通过设置Map的个数对样本进行分解。本次实验中Map的个数设为2,这样每个增量训练子集都会被云平台自动划分成两块,各块之间可以进行并行训练。为了与云平台环境进行对比,在集中式环境中将每个子集手动均分成两块,每块用来训练一个分类器。每个实验均采用了式(1)和式(2)两种核函数。
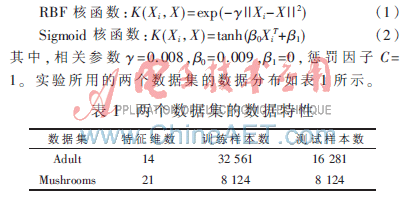
其中,相关参数γ=0.008,β0=0.009,β1=0,惩罚因子C=1。实验所用的两个数据集的数据分布如表1所示。
两个增量分类系统在不同数据集上的分类性能如图4所示。通过比较可知,集中式增量分类的准确率和Hadoop云平台上增量分类准确率较为接近,证明了本文所提出的在Hadoop云平台上实现增量分类方法的可行性和正确性。由于MV方法本身具有较大的波动性,故集中式和Hadoop云平台环境中随着训练样本的增加,增量分类系统的学习能力是曲折上升的。

本文提出了一种基于Hadoop云平台的增量分类方法,仿真实验表明,基于Hadoop云平台的增量分类是可行的。与其他增量分类方法相比,该模型简单,易于实现。通过设置平台中Map任务的个数让云平台自动地对海量训练样本进行划分,划分后的各个任务相互独立,可以进行并行训练。这提高了海量数据的处理速度,基本实现了实时的增量分类。
参考文献
[1] 罗四维,温津伟.神经场整体性和增殖性研究与分析[J].计算机研究与发展,2003,40(5):668-674.
[2] 周志华,陈世福.神经网络集成[J].计算机学报,2002,25(1):1-8.
[3] 王珏,石纯一.机器学习研究[J].广西师范大学学报,2003,21(2):1-15.
[4] LU B L,ITO M.Task decomposition and module combination based on class relations:a modular neural networks for pattern classification[J].IEEE Trans.Neural Networks,1999,10(5):1244-1256.
[5] HUANG Y S,SUEN C Y.A method of combining multiple experts for the recognition of unconstrained handwritten numerals[J]. IEEE Trans. Pattern Analysis and Machine Intelligence,1995,17(1):90-94.
[6] WOODS K, KEGELMEYER W P,BOWYER K.Combination of multiple classifiers using local accuracy estimates[J]. IEEE Trans. Pattern Analysis and Machine Intelligence, 1997, 19(4):405-410.
[7] POLIKAR R,UDPA L,UDPA S S,et al. Learn++:an incremental learning algorithm for supervised neural networks [J]. IEEE Trans. System, Man, and Cybernetic, 2001,31(4):497-508.
[8] LU B L,ICHIKAWA M. Emergent online learning in minmax modular neural networks[J]. In:Proc. of Inter’l Conference on Neural Network(IJCNN’01), Washington, DC,USA, 2001:2650-2655.
[9] 文益民,杨旸,吕宝粮.集成学习算法在增量学习中的应用研究[J].计算机研究与发展, 2005, 42(增刊):222-227.
[10] COPPOCK H W,FREUND J E.All-or-none versus incremental learning of errorless shock escapes by the rat[J]. Science, 1962, 135(3500):318-319.
[11] Hadoop.[EB/OL].2008-12-16.http://hadoop.apache.org/core/.
[12] DEAN J,GHEMAWAT S.MapReduce:simplified data processingon large clusters[J]. Communications of the ACM, 2008, 51(1):107-113.
[13] PLATT J C. Fast training of support vector machines using sequential minimal optimization[D].SCHOLKOPF B, BURGES C J C, SMOLA A J, editors.Advances in kernel methods-support vector learning.Cambridge, MA,MIT Press,1998.
[14] 邓乃扬,田英杰.数据挖掘中的新方法:支持向量机[D]. 北京:科学出版社, 2004.