
摘 要: 介绍了根据图像的逻辑特征和抽象属性进行检索的基于语义分类的图像检索技术,并用Bayes分类算法设计了一个语义分类器,该语义分类器通过计算用户要查询图像的后验概率,对被查询的图像进行语义分类。
关键词: 语义分类 图像检索 Bayes算法 特征向量
1 语义图像检索
图像检索的传统方法是基于文本的,使用关键字注释是最常用的方法。这样,对图像的检索就变成了对关键字的查找。但是,基于文本的检索存在的主要问题是:由于图像注解的主观性和不完备性,因而不能保证检全率。为了克服基于文本方法的局限性,20世纪90年代出现了基于内容的图像检索(Content-Based Image Retrieval,CBIR)。CBIR系统是指直接采用图像内容进行图像信息查询的检索系统[1]。按照图像检索复杂度的递增,CBIR可以分为以下3个层次上的图像检索。
(1)原始特征。使用颜色、纹理、形状等视觉特征进行图像检索。这些特征是客观的,是图像本身的属性,不需要任何外部知识。在这一层次上的检索一般应用于特定领域的专家系统,如商标登记、档案识别等。
(2)导出特征。导出特征又称为逻辑特征,是通过对图像中所描述对象进行某种程度的逻辑推理而得到的。例如,“查询双层公共汽车的图片”,这一层次的检索需要得到一些外部知识的帮助。目前,报纸、杂志等图像数据库的检索主要是在这一层次上进行。
(3)抽象属性。该层次的检索涉及到对图像中所包含物体的含义和场景的描述进行大量的高层次的推理。例如,“查询描写苦难的图片”,要想检索成功,需要较复杂的搜索引擎,运用推理和主观判断,在图像内容和抽象概念之间建立联系。
按导出特征和抽象属性进行检索又称为语义图像检索[2]。目前,大部分CBIR是按照图像的原始视觉特征,在第一层次上进行检索。然而,基于语义的图像检索的应用范围更为广阔,现在已成为基于内容的图像检索的发展热点。
2 基于Bayes算法的图像语义分类
特征(即内容)的提取是CBIR的基础。CBIR的特征主要是指视觉特征,包括颜色、纹理、形状和位置关系等特征。但是,按照原始视觉特征检索的CBIR系统存在的主要问题是没有建立视觉内容和图像语义之间的关联,如木纹图像和水纹图像的纹理特征向量之间的距离很小,一片枫叶图像的颜色特征和红色油漆木门图像的颜色特征非常相似,但它们的语义却截然不同。为了填补视觉内容和内容解释之间的语义缝隙,本文提出语义图像检索,其核心部分是图像的语义分类[3]。这里,用Bayes分类算法来计算在特征值为[xi1,xi2,……]的条件下,图像属于语义类型cj的概率P(cj|[xi1,xi2,……])。
Bayes分类算法是根据先验概率计算出后验概率。通过训练样本,可以构造出语义分类器,语义分类器根据用户要查询图像的后验概率对被查询图像进行语义分类。
图像的语义,即对图像内容的解释。简单语义通常就是图像的主题词,复杂语义则是对图像内容的叙事型描述。本文采用简单语义的标记方式,即:
图像语义s∷=图像标识+{主题词注释}
这里,图像主题词注释既包括图像名称、图像中显示出的物体,也包括图像的视觉属性。图像可以按照语义归类。

在计算出先验概率P(c)和条件概率P(x|c)后即可得到后验概率P(c|x)。
对于给定的一组训练样本图像,若样本总数为N,语义类型c中包含的样本个数为Nc,则记为:
![]()
研究表明,人类的视觉内容往往存在一定的偏差。这种偏差可以通过正态分布拟合给予弥补,即对于任一种语义类型c,首先把同样的Gaussian内核放入它的所有训练样本的特征向量Xi,然后再把这些Gaussian内核累加起来作为条件概率P(x|c)的估计:
![]()
这里,G(X-μ,σ)是Gaussian内核,μ是平均值,σ是模糊度(即标准差)。模糊度根据图像质量由用户指定。
不同的视觉特征对不同语义的图像有不同的辩识能力。现在的问题是:如何从图像特征向量集合中选择一类或几类特征,使得被选择特征对特定语义类型的图像具有最强的表达能力。图像、图像特征和图像语义三者的关系如图1所示。
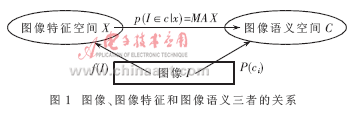
定义3 给定一个语义类型集C,寻找一个从图像I到图像特征向量集合X的映射f(I)=X,使MAX(p(I∈ci|f(I)=X),i=1,2,……m)成立,这一过程称为基于语义分类的图像检索。
3 语义分类器
直接利用图像的原始视觉特征进行语义分类较困难。常用的方法是:用户先对一组图像(训练样本)进行手工语义分类,设定好CBIR系统的语义分类器。当用户查询图像时,系统根据查询图像的视觉特征识别其语义,把查询图像和具有相同语义类型的图像库进行比较,按相似性大小返回查询结果。对图像按语义分类的具体流程如图2所示。

下面设计一个语义分类器,其图像语义层次结构如图3所示。该语义分类器具有以下特点:
(1)图像的语义按层次结构分类。
(2)图像的语义为自顶向下分类。
(3)图像的语义分类结构为可扩充的体系结构。
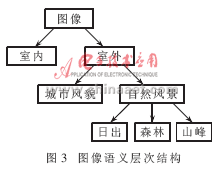
先利用一组训练图像数据进行语义分类,对于训练数据中的图像,按上述语义层次结构,用手工方法把图像归入一个语义类型中,并给图像贴上相应的语义标签。城市风貌可以归纳为具有人工建筑和人造物品,如建筑物、汽车、道路等。自然风景没有这些特征。在自然风景下有3个子类:日出、森林和山峰。日出可以用饱和度较高的颜色(红色、橙黄色、黄色)来表示,森林中绿色为主色调,山峰可以用长距离的山区景色来标识。
衡量视觉特征对语义类型的区别能力还很困难。通常认为,如果一个视觉特征使同一语义类型内的图像距离较小,而使不同语义类型中的图像距离较大,则该视觉特征对语义类型的区别能力是较强的。通过计算一个语义类型内每一对图像之间的距离,可以得到该语义类型内的图像的距离分布。通过计算不同语义类型(如城市风貌和自然风景)之间每一对图像之间的距离,可以得到不同语义类型之间的图像的距离分布。
在每个语义类型(城市风貌和自然风景)中选择k个最相似的图像,用户的查询图像通过与这k幅图像的比较,可以判断查询图像属于哪个语义类型。
对于本文设计的语义分类器,经过计算发现,形状特征对城市风貌和自然风景2种语义类型的区别能力比其他视觉特征要强。城市风貌中的人造物体具有较明显的水平和垂直边,而自然风景对象的边缘就比较随意。因此用形状特征能够比较容易地区别二者。以颜色特征区别自然风景下的日出、森林、山峰更加理想,如草地用绿色表示,天空用蓝色表示等。
4 结束语
本文根据Bayes分类方法对图像语义进行分类,设计了一个语义分类器。利用训练数据定义好语义类型后,就可以根据图像的视觉特征找到图像的语义类型。这样相似性匹配即可在同一语义类型下进行,因而提高了图像检索效率。
参考文献
1 付岩,王耀威.SVM用于基于内容的自然图像分类和检索. 计算机学报,2003;26(10)
2 Smeulders A,Worring M.Content-based Image Retrieval at the End of the Early Years.IEEE Transactions on Pattern Analysis and Machine Intelligence,2000;22(12)
3 庄越挺,潘云鹤.基于内容的图像检索综述.模式识别与人工智能,1999;12(2)