
文献标识码: A
文章编号: 0258-7998(2012)05-0128-04
近年来,Lustre作为一个开源的高性能分布式集群文件系统,以其PB级的共享存储容量和上百吉字节每秒的聚合 I/O带宽被广泛应用于HPC领域。有数据[1]表明Lustre在HPC领域占有最大的市场份额,已成为构建HPC集群的事实上的标准。将Lustre引入到传统的MPI集群解决I/O瓶颈,可提升并行计算速度。但是简单地将Lustre移植到MPI集群中并不能获得预期的效果。其主要原因是,运行MPI的并行程序需要进行大量的I/O访问,而在这些I/O访问中基于小数据(细粒度)的I/O访问往往占据着相当大的比率,虽然Lustre能在连续大数据(粗粒度)传输上达到很高的I/O带宽,但在不连续小数据传输上并没有获得显著的性能提升。当大量小数据I/O频繁访问时,就会使该文件系统的整体性能迅速下降,以至实际I/O带宽远低于所提供的最大带宽。
为解决这一问题,通常的方法是在Lustre的上层加入一个并行I/O库,通过该库将多个不连续小数据块的I/O操作转化为对并行文件系统中的少量连续大数据块的实际I/O操作,最大程度地利用并行文件系统所提供的带宽,减少I/O瓶颈对程序性能的影响,在库的级别上优化并行I/O的访问效率。本文提出了一种基于MPI-IO库(并行I/O库)编程接口的改进方案,以保证在小数据整合为大数据的过程中进一步减少进程间的通信量和时间消耗,从而提升集群并行效率,为传统MPI集群的升级改造提供新的思路或新的方法。
1 Lustre文件系统性能介绍
Lustre是面向集群的存储架构,是基于Linux平台的开源集群(并行)文件系统。由于其提供了与POSIX兼容的文件系统接口,从而使其扩展了应用领域。Lustre拥有高性能和高扩展性两个最大特征。高性能是指它能够支持数万客户端系统、PB级存储容量和数百GB的聚合I/O吞吐量;高扩展性是指由于Lustre是Scale-Out存储架构,由此可以借助强大的横向扩展能力,只要以增加服务器的方式便可扩展系统总存储容量和系统总性能。
Lustre文件系统主要由元数据服务器MDS(Metadata Server)、对象存储服务器OSS(Object Storage Server)、客户端(Lustre Client)三部分组成。MDS用于存储数据描述信息,管理命名空间和目标存储地址;OSS进行实际的数据存储,提供文件I/O服务;Lustre Client则运行Lustre文件系统,并作为集群计算端与MDS和OSS进行信息交互[2]。如图1所示。
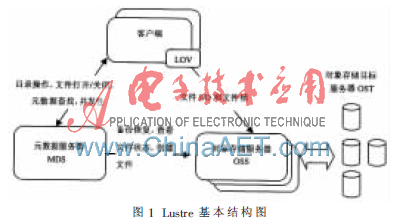
由于Lustre设计的初衷是要提高数据访问的并行性和扩展聚合I/O带宽,所以在设计过程中广泛采用了元数据与数据分离、数据分片策略、数据缓存和LNET网络等技术。而在这些设计中,数据分片设计和后端改进的EXT3文件系统非常适合大数据连续I/O访问,所以Lustre在大数据应用中其性能表现得非常好。但对于不连续小数据I/O而言,由于Lustre在读写文件前需要与MDS进行交互,以获得相关的属性和对象位置信息,从而增加了一次额外的网络传输和元数据访问的开销(与传统本地文件系统相比)。若有大量频繁的小数据读写时,Lustre客户端上Cache的作用将失效,其命中率也会大大降低。如果数据小于物理页大小,则还会产生额外的网络通信量,小数据访问越频繁,则网络开销也就越大,进而影响Lustrer的总体I/O性能。OST(对象存储目标服务器)后端虽然采用了改进的EXT3文件系统,但它对小数据的读写性能存在先天的缺陷,其元数据访问效率也不高,且磁盘寻址延迟和磁盘碎片问题严重。所以,Lustre的设计决定了它对小数据I/O的表现,其实际I/O带宽远低于所提供的最大带宽。
因此Lustre集群及其并行架构非常适合众多客户端并发进行大数据读写的场合,但对于不连续小数据的应用是不适合的,尤其是海量小文件应用LOSF(Lots Of Small Files)。
2 MPI-IO对并行I/O的实现
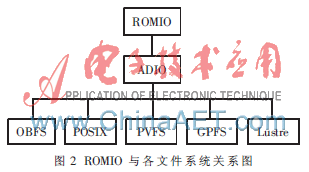
MPI-IO是一个并行I/O库,作为 MPI-2 规范的一部分,提供了执行可移植的、用户级的I/O 操作接口。MPI可以通过该接口在文件和进程间传送数据,如图2所示。ROMIO是MPI-IO的一个具体实现,而ADIO是位于并行文件系统和上层I/O库ROMIO之间的软件层,它的作用是使得上层并行I/O库的实现具有更好的移植性和更好的I/O访问效率。由于ADIO可以在不同的并行文件系统上实现,提供了一组最基本的并行I/O访问的函数,所以I/O库只需要在ADIO上实现一次,就可以通过ADIO实现对所有底层文件系统的访问。一些特定的并行文件系统的优化通常也在ADIO层上实现,所以ADIO的实现使得上层库可以透明访问底层并行文件系统,而不必考虑底层并行文件系统方面的细节。正基于此,本文所提出的改进策略也是在ADIO上实现的[3]。
MPI-IO可分为非集中式(noncollective I/O)和集中式(collective I/O)两种I/O操作。
非集中式I/O操作,是MPI-IO的普通I/O操作方式。在此操作下,若每个进程访问文件中存放位置不连续的小片数据时,往往是对每一个小片连续的数据使用单个独立函数来读写数据,就像在Unix或Linux中一样,所以这种方法I/O延迟较大,系统开销也较大。但对于连续大数据的读写,此种方式可以利用操作系统缓存和Lustre数据分片等技术,充分发挥并行I/O的优势。
而对于集中式I/O操作,由于集中式I/O具有并行程序的对称性,当I/O发生时集群中所有节点均运行到各自子进程的相同位置,所以各子进程会在一个很短的时间间隔内各自发出I/O 请求,集中式I/O便合并这些小的读写请求,使之整合成为大的读写请求,从而减少磁盘磁头移动和I/O次数,提高I/O读写速度。本文的改进型编程接口也正是基于此类I/O方式将多个不连续的小数据I/O整合为少量的大数据I/O,进而再利用底层的Lustre并行文件系统对大数据I/O的优势,使得集群的整体并行效率得到提升。集中式I/O有很多实现方案,ROMIO是采用基于Client-level的两阶段法来实现集中式I/O的。
两阶段法通过分析集中式I/O请求对数据的总体需求,将一次I/O操作分成两个阶段来完成。第一个阶段是所有计算进程交换彼此I/O信息,确定每个进程的文件域,从磁盘上读取相应I/O数据;第二个阶段是按照应用需求将缓冲区的数据交换分配到各进程的用户缓冲区,写操作与读操作类似。在这两个阶段中,进程之间需要进行相互通信,同步同一通信域中的相关进程的数据信息,从而得到程序总体的I/O行为信息,以便整合各个进程独立的I/O请求。如图3所示。

第一阶段:
(1) 确定参加读操作的通信域中所有进程,并进行同步;
(2) 确定每个进程各自需要读取的一个包含所请求数据的连续的文件区域;
(3) 每个进程根据自己的文件区域进行I/O访问,并将这些数据存放在一个临时缓冲中,同步所有进程到每个进程的I/O操作结束。
第二阶段:
(1) 进行I/O数据的置换,将缓存中数据发送给目标进程;
(2) 同步所有进程到数据置换结束。
写操作类似于读操作。两阶段I/O整合了多个进程所请求的数据范围,访问到稠密的数据区域的可能性比较大,因此对于非连续数据分布比较分散情况,该算法有明显的性能优势。但是,两阶段I/O的性能很大程度上依赖于MPI所提供的高效的数据传递机制,即消息传递机制。如果MPI无法提供比底层文件的聚合带宽更快的速度,那么在两阶段I/O中数据传递所带来的额外开销将会大大降低该I/O方式的性能[4]。
3 改进的并行I/O编程接口
从上述分析可知,MPI-IO在整个集群系统中起到了承上启下的作用,向上连接MPI计算系统,向下连接Lustre并行文件系统,所以其效率的高低一直影响到集群的整体并行I/O效率。为此,本文所提方案需要对以下三个方面进行改进。
(1) 如何界定数据块的大小
在Linux 32 bit的操作系统中,一个页面大小为4 KB,同时也是Lustre网络传输的基本单位。由参考文献[4]可知,当数据大小不到一页或不同进程同时读写一个页面中数据的时候,Lustre的I/O性能最差,甚至不如传统的本地文件系统;若数据块的大小不足一个条块(数据分片),则客户端每次读写只与一个OST交互信息,没有从真正意义上实现Lustre并发I/O的功能。
所以如何界定数据块的大小,是提高系统并行效率的关键。本文依据参考文献[4]所提供的实验数据,设定Lustre条块大小为64 KB,若数据块小于该值,则视为小数据,按本文改进的集中式MPI-IO编程接口操作;若数据块大于该值,则视为大数据,按非集中式MPI-IO接口操作。
(2) 采用直接I/O模式以减少内核消耗
Lustre文件系统底层采用Portals协议进行数据传输,上层则连接Linux操作系统的VFS(虚拟文件系统)。应用程序所有的I/O操作都必须通过Linux的VFS才能进入Lustre。在Linux操作系统中,读写模式分为文件缓存(Cache)模式和直接(Direct)模式。
对于Lustre文件系统而言,由于该文件系统是以页面为I/O的基本单位,所以当n个进程去读取仅需一个页面的数据流量时,若采用缓存机制,则实际系统需要n个页面的I/O流量才可完成,而随着I/O请求的增加,这种额外的开销将会越来越大;而对于写操作,缓存机制在小数据I/O的问题则更加突出。在写操作时,由于每个进程必须获得该页面上的文件锁才能进行,以保证对这个文件写操作的独占性。但是当一个进程获得锁后,其他进程只有等待该进程结束操作,所以对于同一个页面的写操作是串行的,系统不能发挥程序的并行作用而造成性能下降。并且,当数据块小于4 KB时(不足一个页面),文件缓存的作用已经不明显,反而使得I/O调用的开销越来越突出。因此, Lustre在非连续小数据I/O时,采用可以绕过系统缓存的直接I/O方式,直接将文件数据传递到进程的内存空间则是一个可行的办法。
(3) 减少集中式I/O第一阶段的通信量
由前述可知,MPI-IO中的集中式I/O操作是采用两阶段法来进行的。该算法第一阶段,通信域中所有进程同步操作方式采用广播的形式,即每个进程的数据信息通过广播的方式发送给通信域里的所有进程。也就是说,若有n个进程参与此次集中I/O操作,则整个过程中进程间需要n×(n-1)次点对点通信才能完成。这样,随着集群节点数的增加, 进程间的通信次数势必会给I/O性能造成较大影响。所以,本文的优化方案就是以减少进程间的通信量为目的,尽量减少进程间的通信次数,以提高整体的I/O性能。这里,选取通信域中的一个进程作为主进程,通过它从其他进程收集各自的I/O信息进行相关的计算,并汇总整合本通信域中的所有I/O信息,再将其进行广播,以达到进程间I/O信息同步的目的。若还是n个进程参与此次集中式I/O操作,则进程间的点到点通信次数将会降到2×(n-1)次。显然,改进后的策略可以明显降低进程之间的通信次数,进而提高了整个集中操作的I/O性能。
4 实验与分析
为验证改进方案的可行性,在传统的MPI集群上做了相应的测试。测试环境为7个节点的集群系统(3台OST,3台客户端,1台MDS),每个节点包含一颗PIV处理器和2 GB内存,40 GB的硬盘,操作系统采用Redhat Linux Enterprise 5(内核为2.6.18),并行集群软件为MPICH2.1,并行文件系统为Lustre 1.0.2。在测试程序中,在3个客户端上同时运行3个进程读写一个文件的不同部分,测试文件为2 GB,其他的什么都不做,来测试改进前后的I/O 读写带宽(改进前的读写方式为Lustre系统的普通读写方式)。
如图4所示,先分析改进前Lustre系统的读写情况:数据块为64 KB时,由于大部分RPC数据包中都包含了数十个页,从而减少了I/O调用的次数,效率达到最高;而当数据块小于64 KB(一个分片的大小)时,此时客户端每次读写只能与一个OST交互信息,从而无法使用Lustre分片技术的并发功能,造成这一阶段读写性能不佳;而当数据块大小为4 KB或者小于4 KB时,性能则快速下降,特别是写操作,性能下降得更为严重,这主要是因为数据块的大小不足1个页面(4 KB),此时大部分的RPC数据包仅仅包含1个页面而导致I/O效率不高,特别是在不同进程同时读写一个页面中的数据的时候,则性能更糟。
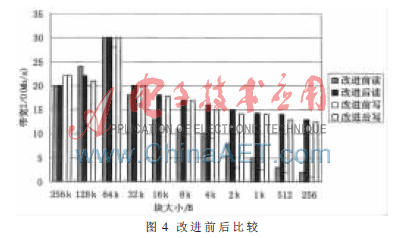
由于改进后的方案采用了MPI-IO中的改进集中式操作和直接I/O技术,使得数据块在64 KB以下区段性能差异较大。但对于数据块大于64 KB时,改进前后的差异不大,这是因为改进后的编程接口将大于64 KB的数据包均视为大数据,不做修改,所以与改进前基本一致;对于数据包小于64 KB时,改进后的读写明显放缓了I/O读写下降的速度,且读操作和写操作的速度基本持平,这主要是因为改进后的方案中使用了MPI-IO中的改进集中式操作,由于MPI-IO中可以使用单个函数来访问非连续数据,且可多次使用,同时MPI-IO也允许一组进程在同一时间访问一个普通文件,在进行多次读写时,I/O的访问开销不但可以降低,而且还可将定义开销分摊到各次访问, 从而改善了小数据I/O操作的性能。
总之,基于Lustre的MPI-IO编程接口的改进方案是可行的。在该机制下构建的MPI集群系统能够有效解决I/O瓶颈,提升并行计算速度,与传统的MPI集群相比性能提高空间很大。但是由于研究刚刚起步,还需要在总结现有不足的基础上,继续实践、改进和完善。
参考文献
[1] 钱迎进,金士尧,肖侬. Lustre文件系统I/O锁的应用与优化[J]. 计算机工程与应用, 2011,47(03):1-5.
[2] BRAAM P J. Lustre: A scable, high-performance file systme[M]. Lustre Whitepaper Version 1.0, 2002.
[3] 刘辉, 胡静, 王振飞,等.MPI-2中的并行I/O的使用分析[J].计算机工程, 2003,29(2):229-232.
[4] 林松涛. 基于Lustre文件系统的并行I/O技术研究[D].国防科学技术大学, 2004.